Vision Transformer based Pose-Conditioned Self-Loop Graph for Human-Object Interaction Detection
배경
- HOI: Human-Object Interection, <human, object, interaction>의 triplet을 반환.
주로 action recognition, scence understanding, image captioning에 사용됨.
기존의 HOI Detector는 크게 2-stage와 1-stage로 갈림.
- 2-stage: 크게 3단계로 나눠짐.
1. human & object detection with off-the-shelf- feature extraction with ROI-Pooling/Align
- prediction interaction with extracted features in 2.
- 1-stage: PPDM이라는 페이퍼에서 처음 제안. interaction points와 union boxes를 기반으로 한번에 HOI triplet을 예측.
최근 연구는 대부분 two-branch transformer를 활용한 one-stage 모델을 활용.
그러나 느린 학습속도와 큰 메모리 사용량이 문제
반면에 two-stage모델은 pretrained를 사용하기에 학습속도가 빠르고, bbox를 알고있다면 추가적인 object detection없이 바로 interaction detection이 가능. 그치만 성능이 별로여서 연구가 덜 되고 있었음.
해당 논문에서는 two-stage 모델의 성능을 높이고자 함.
1. feature extraction 과정에서 ResNet이 아닌 ViT backbone을 활용하여 성능 높이기
2. 인간의 HOI detection 과정을 고려한 pose-conditioned graph neural network의 활용.
위 두가지를 합쳐 ViT based pose condionted self-lopp graph를 제안, HOI detection 분야의 데이터셋인 HICO-DET와 V-COCO에서 sota를 달성했다.
Method
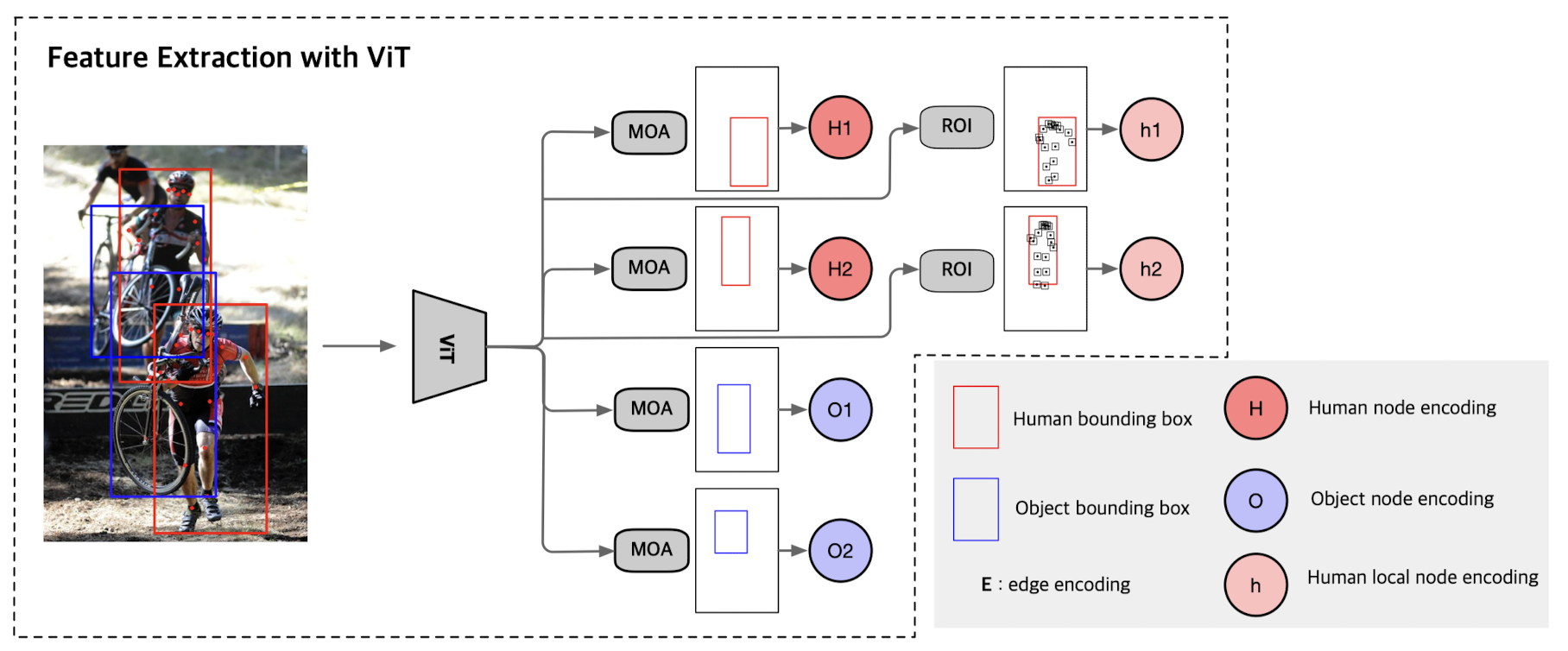
Feature Extraction with ViT
- human, object detection은 Fatser R-CNN으로 진행.
기존에 사용되던 feature extraction backbone인 ResNet대신 ViT를 활용하기 위해서는 모델이 달라져야하는데, 그것을 바로 output feature map의 형태가 바뀌기 때문이다. 이를위해 Masking with Overlapped Area, MOA라는 모듈을 제안한다.
- ViT의 CLS token: ViT는 patch sequence앞에 CLS token과 같은 learnable한 embedding을 앞에 붙인다. 이러한 CLS token은 encoder를 거치면 image representation의 효과를 얻게 되는데, 따라서 여기에서 feature를 extract할 수 있다.
하지만, CLS token은 ROI-Pooling과 같은 quantization problem에서 문제가 있다.
주로 patch의 size가 14, 16, 32로 이루어져있기 때문에 완벽히 bbox와 일치하지 않게 되고, 단순히 영역이 포함된 패치를 모두 포함하는 등의 연산은 misalignment를 낳는다.
따라서 아래와 같이 각 패치가 ROI 영역과 얼마나 겹치는지를 연산 한 뒤에,
해당 값을 CLS token과의 Attention 연산 시에 반영하는 방식을 이용한다.
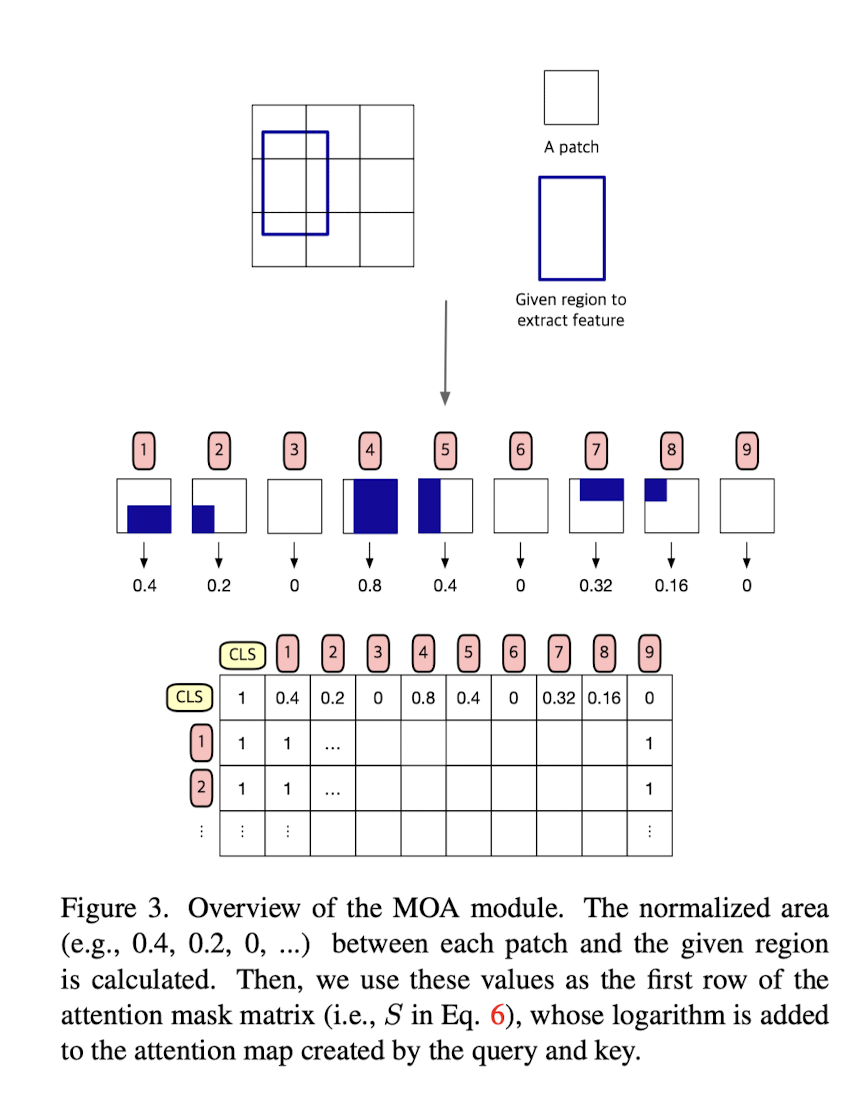
구해진 attention mask matrix는 softmax 연산시에 log가 취해진채로 더해져, normalize 값이 0일 경우 가 더해지는 식으로 진행된다.
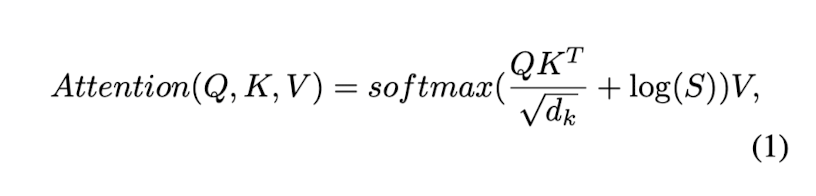
위 방식은 높은 성능 개선을 보였지만 (4.3의 ablation study 참조), S가 모든 bbox에 대해서 연산되어야하는 문제가 있었고 그 문제를 GPU에서의 연산과 추가적인 테크닉의 적용을 통해서 해결했다고 한다. (Appendix B.)
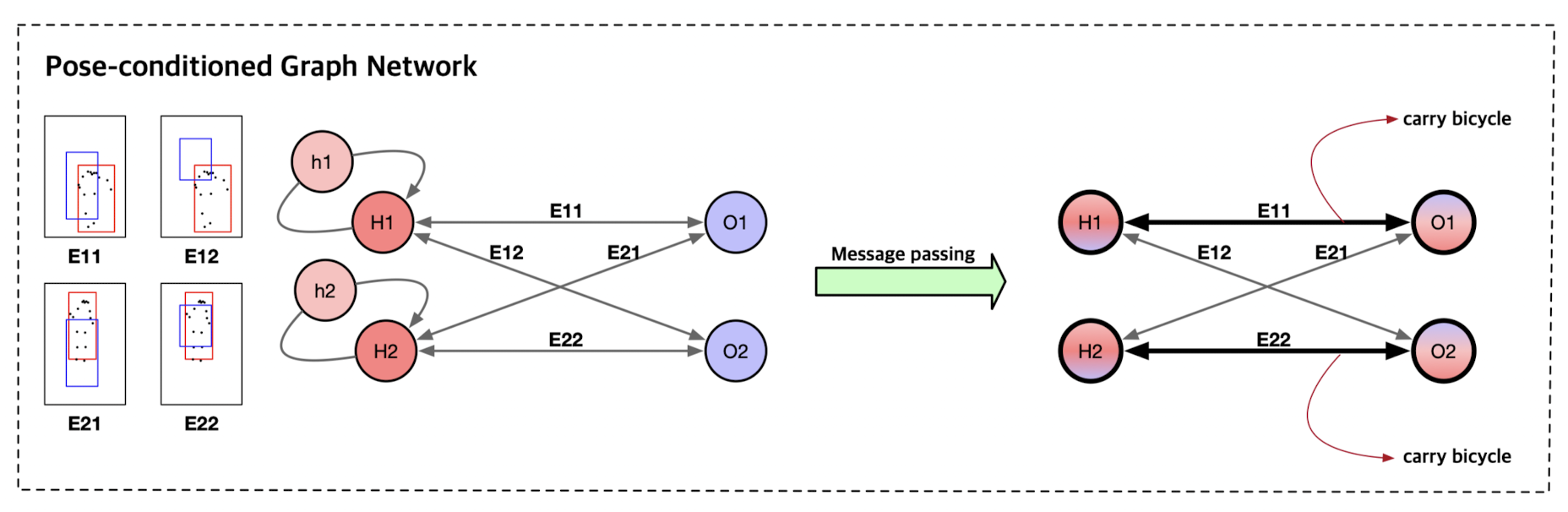
Pose-conditioned Graph Neural Network.
-
배경지식이 부족하니 우선 간단한 이해만 적어보기로
-
인간의 HOI recognition 과정을 3단계로 정의
1. Human, objects localize 2. Interactiveness 여부 판단 3. Human의 특정 joint 에 집중하여 interaction의 종류 알아내기. -
위 3가지 과정을 고려하여 pose-conditioned gnn을 사용하기로 결정.
기존에 연구들은 2번단계를 진행하기 위해서 non-interactive pair들을 제거하는 aux network를 사용했지만, 해당 논문에서는 사람의 pose와 spatial human-object relation으로 부터 얻어진 edge encoding을 통해서 interactiveness를 나타낸다고 한다.