Low Manifold Theory, Manifold Hypothesis (Latent, Encoder, Docoder, Embedding에 관한 글)
좌충우돌 논문리뷰
💡 Latent? Code? 이게 뭐람?
- Latent란 무엇일까?
- Encoder, Decoder란 무엇일까?
- 대체 왜 Latent, Code로 바꾸는 걸까?
인공지능을 공부하다 보면, Latent, Encoder, Decoder와 같은 단어를 정말 많이 접할 수 있을 것이다.
"그냥 벡터다" 혹은 "컴퓨터가 이해할 수 있도록 숫자로 바꾼 것이다"라는 설명으로도 대충 이해하고 넘어갈 수 있을 듯 하지만,
앞으로 인공지능을 공부할 때 조금 더 수월하게 이해하는데 도움이 될 Low Manifold Theory에 대해서 설명해보고자 한다.
🥚 맛보기 예시 - 압축
- 사실 어렵게 생각할 필요없이, 우리가 큰 파일을 작은 사이즈로 줄이기 위해서 "압축"하는 것과 같다고 생각해도 무방하다.
- 혹은 "불필요한 정보들을 제거"하여 딱 필요한 정보만 남긴다고 생각해도 괜찮다.
🔢 예시 - MNIST 데이터셋

인공지능을 접했을 때 자주 보게 되는 손글씨 숫자 데이터, MNIST
- MNIST 데이터셋은, 28x28 (총 784개)의 픽셀 사이즈를 가진 흑백 손글씨 이미지 데이터셋이다.
- 그리고, 흑백이라는 것은 곧 0(검정색) ~ 255(흰색) 사이의 총 256개 중 하나의 정수값을 가진다는 뜻이다.
- 간단한 계산을 해보자. 각 픽셀 당 256개 중 하나의 값을 가질 수 있다면, 총 784개의 픽셀을 가지는 MNIST 이미지들은 의 무지막지한 경우의 수를 가지게 된다!
- 이게 말이 될까? 정말 그만큼의 손글씨 데이터가 있는 것일까???
(더 큰 사이즈의 이미지면, 게다가 컬러면 얼마나 많은 경우의 수가 있는걸까? 컴퓨터는 그것을 다 기억할 수 있을까?)
사실 가운데 정렬된 "흑백 숫자 이미지"라는 것은
"숫자 종류 (0~9), 글자 두께, 기울기, 글씨체(e.g. 4의 윗부분을 붙여쓰냐 띄워서 쓰냐) 등의 정보"
+ "어느 정도의 랜덤성"으로 구성되는 것이 아닐까??
위 가정이 들어 맞는다면, 사실 우리는 몇백, 몇천 개의 숫자로 충분히 위의 이미지들을 표현 or 요약할 수 있을 것이다!
그것이 바로 Latent, Code라고 불리는 것들이다.
그렇기에 때문에 En-coder는 단순히 데이터를 code로 압축하는 모델이고,
De-coder는 code를 다시 데이터로 압축해제 혹은 복원하는 역할의 모델인 것이다.
압축본이기 때문에, Latent나 Code단계에서의 Manipulation(조작)이 decode(압축해제)된 결과물에 영향을 미치는 것이다.
정말 간단한 내용이고, 컴퓨팅 비용을 줄여야 좋기 때문에 어찌보면 당연하게 행해지는 것일지도 모른다.
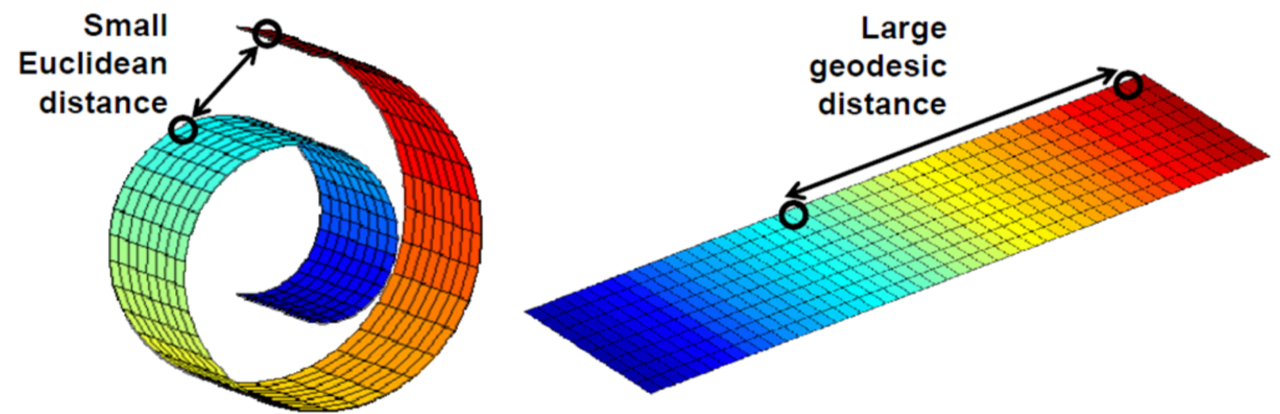
+ 위의 이미지처럼, 실제 데이터 공간에서의 거리와 우리가 느끼는 의미적인 거리는 다를 수 있다.
⭐️ 마무리 인사
이 포스팅을 통해서 여러분이 다른 논문을 읽거나 공부를 할 때, 조금 더 쉽게 공부할 수 있었으면 합니다!
읽어주셔서 감사합니다:)
관련 포스팅: https://velog.io/@jqdjhy/Stable-Diffusion-정복기-AutoEncoder-인코딩이-뭔데
