지도학습은 supervised learning이다.
super(over) + vise(see) = 모든 상황을 지켜보다
그러니 supervised learning은 모든 상황을 지켜보는 학습이다. supervised가 과거분사이니 행위의 주체로 by someone이 생략되어 있다. 그는 누구인가? 나 혹은 독자다.
supervised learning (by someone)
= 누군가가 모든 상황을 지켜보는 채로 진행되는 학습
무언가를 배우는 데, 모든 것을 이미 아는 채로 배운다니 모순적이지 않은가? 모르는 것을 배워야지, 아는 것을 배워봤자 무슨 소용인가.
배우는 건 내가 아니다.
우리가 아는 채로 우리가 배운다면 그건 모순이지만, 여기에 1명을 더 투입하면 모순이 아니게 된다.
we supervise someone else's learning.
우리는 '누군가가 배우는 과정'을 supervise할 것이다. 그 누군가는 바로 인공지능, 혹은 알고리즘이 될 것이다.
수학적 정의
지도학습을 수학적으로 정의하려면 우선 학습의 대상인 데이터에 대해 알아야 한다. 데이터(data)는 라틴어 datum(주어진 것)에서 유래했다고 한다. 관심대상 자체가 주어진 것이 아니라, 관심대상을 설명하는 어떤 수치가 주어진 것이 데이터다. 그렇기에 데이터는 관심대상에 대한 정보의 압축이다.
우리에게 관심대상에 대한 정보를 제공해줄 x라는 데이터셋(set of data, 데이터의 집합)은 관심대상을 온전히 표현하지 못한다. 대신, 관심대상으로부터 m개의 특성을 도출하면 관심대상을 n개의 반복적인, 일련의, 압축된 정보로 표현할 수 있다.
예를 들어 관심대상이 날씨라면? 데이터로 완벽하게 날씨를 표현할 수는 없겠지만, 다음처럼 날씨의 특성들을 도출할 수 있다.
1. 날씨를 관측한 날짜
2. 주관적인 기준으로 맑은 날씨인지 여부(맑지 않음=0 or 맑음=1)
3. 강우량
m=3개의 특성으로 날씨를 표현했으며, 100일간 관측/기록했다면 n=100개의 데이터를 포함하는 x라는 데이터셋을 확보한 것이다.
x와 y
날씨에 대한 압축된 정보를 수집해 x라는 데이터셋으로 정리했다. 지도학습은 이 날씨정보(x)가 다른 정보(y)와 어떤 연관이 얼마나 있는지 알아보기 위한 도구다. 중학교 때부터 수학 시간에 계산식보다 그래프를 그리기 시작하는데, x와 y는 항상 같은 그래프에 등장했을 것이다.
 [이미지 출처 (클릭)]
[이미지 출처 (클릭)]
x가 얼마이면? y는 얼마다. 그러한 진술 하나가 위 그래프에 포함된 어느 점 하나(데이터 포인트)를 뜻한다. 우리도 i번째 x(어떤 날짜의 날씨에 대한 압축된 정보)에 해당하는 i번째 y(어떤 날짜의 어떤 관심 대상에 대한 압축된 정보)를 만들어보자.
어떤 날이 맑지 않았고, 비가 꽤 많이 내렸다. 그 날에 맥도날드의 매출은 어땠을까?
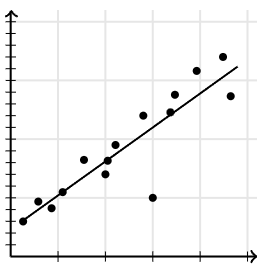
만약 그 날(i)이 아직 오지 않아서 xi에 해당하는 yi를 알 수 없을 때는 어떻게 이 질문에 답할까?
[이미지 출처 (클릭)]
추세선을 그어보니까, '대충' 이렇겠네~
경향성을 시각화하는 추세선을 도출하여 가로축(x)과 세로축(y)의 관계를 보고, 기존에 확보한 데이터 포인트가 없는 x값에 대해서도 y에 대한 추정값을 내보는 것이다. 과거에 대한 압축된 정보가 미래에 대한 불완전한 예측의 영역을 열어준다. 비록 그것이 '대충' 해보는 예측일지라도, 요즘의 데이터 과학은 압도적인 x를 확보함으로써 '완전에 가까운 대충'을 실현하려 노력하고 있다.
근거 없는 예측
어쨌든, 지도학습은 위처럼 x와 y의 데이터쌍이 n개 모여 형성된 D라는 통일된 데이터셋이 있어야만 진행할 수 있다. 데이터가 비록 압축된, 다르게 말하면 손실된 정보일지라도 그것마저 없으면 우리가 내놓는 예측에 아무런 근거가 없기 때문이다. 근거 없는 예측은 낭설에 지나지 않게 된다. 낭설은 가치가 없다. 가치가 없다면, 굳이 그런 예측은 할 필요가 없지 않은가.
그럼 지도학습으로 무엇을 해낼 수 있는지, 그 과정 등에 대해서 더 자세하게 다음 시간에 다뤄보자.

{kind=link}
{kind=link}