어제 지도학습에 필요한 재료에 대해서 이야기를 했다. 지도학습을 위해서는 관심대상에 대한 압축된 정보인 데이터셋 D가 필요하다.
그렇다면 지도학습을 한다는 건 궁극적으로 어떤 행위인가? 어제도 언급한 '추세선'이 그 비유적인 답이 될 것이다. 물론 선형회귀라는 지도학습의 일종에서는 추세선을 도출하는 것이 '비유'가 아니라 '진짜' 지도학습의 행위 자체가 되기도 한다.
 [이미지 출처 (클릭)]
[이미지 출처 (클릭)]
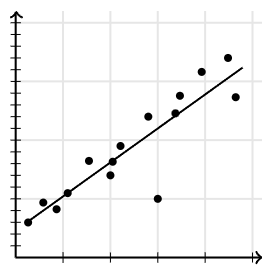
어제의 이 사진처럼 각각의 데이터 포인트는 그 자체로 관심대상에 대한 압축된 정보이지만, 이것들로부터 하나의 추세선을 도출한다면 그것은 이미 압축된 정보를 한 번 더 압축한.. 말하자면 '심하게 압축된' 정보가 된다.
왜 그토록 많은 데이터를 아까운 정보손실에도 불구하고 이렇게 심하게 압축해버릴까? 그 이유는 인간이 그런 방식으로 생각하는 생물이라서, 인간이 만들어낸 지도학습도 그런 특성을 지닐 수밖에 없는 것이라고 생각한다. 부전자전이라는 말도 있지 않은가.
정보압축의 선물, 이해와 오해
사실 수백/수천만개의 데이터도 그 자체로 효과를 발휘하진 못한다. 수백만개의 데이터를 들여다볼 사람이 있겠는가? 하물며, 그 사람이 종이 수천장을 들여다 보며 어떤 유용한 가치를 창출해낼 수 있겠는가? 나에게 묻는다면, 데이터 수집에 들인 시간과 종이의 값보다 나은 가치를 창출하기도 힘들 것이라고 확신한다.
데이터는 오로지 과거의 대표자다. 과거의 것을 지지고 볶아 나온 요리도 과거의 것이다. 그러나 우리는 지난 글에서 언급했던 '예측'에서 데이터의 가치를 찾는다. 아직 오지 아니함을 뜻하는 미래(未來)에 대한 진술은 항상 부정확한데, 오히려 그러한 환상을 말해줄 사람에 의존할 수밖에 없는 인간의 나약한 본성이 지도학습같은 예측용 도구에 가치를 더해준다.
우리는 지도학습의 과정에서 D라는 데이터셋을 크게 둘로 나눌 것이다. 하나는 과거로, 하나는 미래로 치부하여 지도학습 알고리즘의 성능을 계산하기도 할 것이다. 그 과정에서 진실 하나는 꼭 기억해야 한다. 미래로 치부한 한 쪽의 데이터셋도 결국 과거의 산물이라는 점을 말이다.
그 점을 알지 못한 채 인공지능을 활용하다보면, 정보를 압축함으로써 얻어낸 과거에 대한 총체적 이해가 오해로 뒤바뀐다. 그리고 그 오해는 다음의 말로 다시 압축되어 입밖에 나올 것이다.
"테스트할 땐 잘 됐는데.."
수학적 이해
우리의 관심대상은 크게 x와 y로 압축되었다. 어제의 예시에서 x는 날씨 정보, y는 맥도날드의 매출이었다. 그러면 지도학습의 궁극적 행위, 비유하자면 '추세선 도출'은 수학적으로 어떻게 표현되는가? 그 진술이 이것이다.
중고등학교 시절 많이 보던 y=f(x) 아닌가? 추세선이 곧 f다. 그런데 자세히 보면 y에 모자가 씌워져 있다. 말그대로 y hat이다. 이는 통계학에서 hat을 '추정값'의 의미로 쓰는 전통에서 비롯된 표현이다. 어쩌면, 양심의 표현이다. y와 x의 관계를 f로 표현했는데, y=f(x)라고 하자니 사실 도출한 f가 정답은 아니지 않은가? 다시 아래의 그래프를 보자.
[이미지 출처 (클릭)]
모든 점이 선과 겹치는가? 그러니까 모든 (x, y)에 대해 y=f(x)가 성립하는가? 그런 경우는 몇 없어보인다. 정말 그렇게 만들려면 그래프는 다음과 같아야 할 것이다.
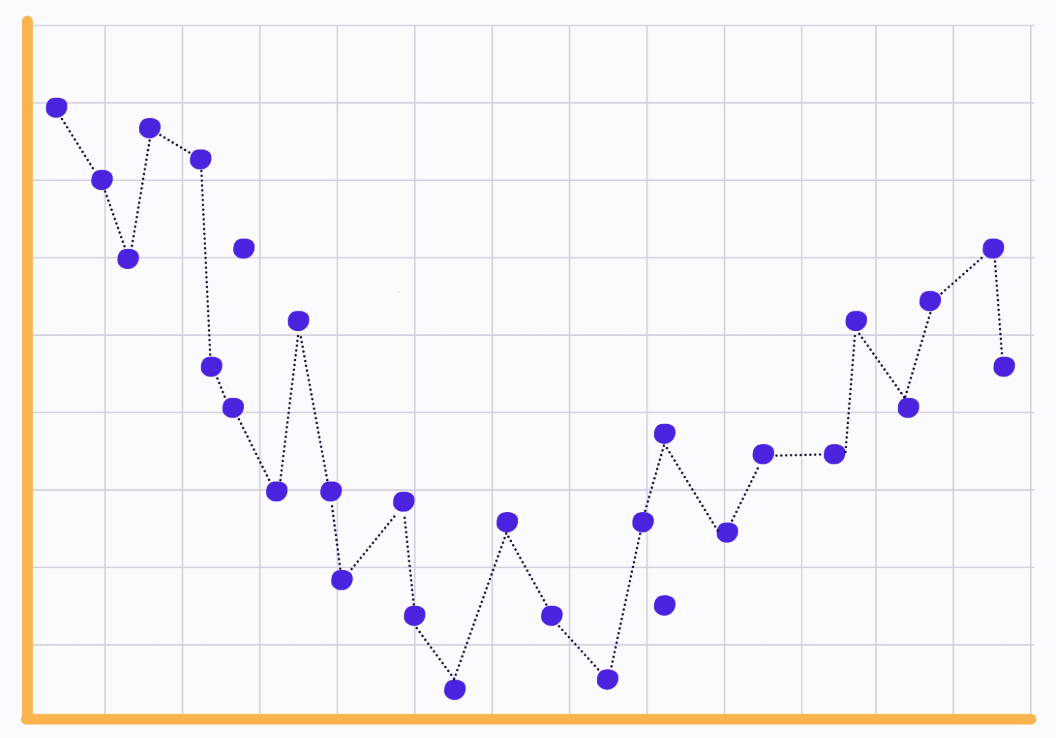
훌륭한 그래프지만, 이게 과연 정보가 압축된 것인가? 저기서 데이터 포인트를 모두 지워버리든 말든 아무 상관이 없게 된다는 건, 정보가 압축되지 않았다는 것이고, 이를 통해 얻은 게 없다는 뜻이 된다.
그래서 데이터과학은 그 미묘한 간격 사이에 위치하는 것 같다. 너무 많은 것을 손실하면 오해가 되고, 너무 손실하지 않으려고 애쓰면 얻는 게 없다. 적당히 잃고 적당히 얻는 균형점을 발견하여 그 속에서 관심대상을 이루는 배경, 즉 시스템을 이해하려는 것이 데이터과학이라고 생각한다.
회귀와 분류
그렇다면 지도학습으로 무엇을 할 수 있는가? 크게 회귀와 분류로 나눈다. 어쩌다 둘로 나뉘게 되었니? 결국 같은 뿌리에서 무엇에 주목하는가에 따라 나뉜 것이다.
관심대상 그 자체가 아니라, 관심대상에 대한 압축된 정보를 숫자의 형태로 다룬다.
지도학습은 숫자를 다루는 도구다. 숫자는 본질적으로 상대적이다. 100은 큰 숫자인가? 나도 모른다. 그러나 99에 비해 큰가? 그렇다. 다른 존재가 빗대어질 때 100에는 '크다'라는 의미가 추가적으로 부여된다. 관심대상에 따라, 우리는 100이라는 숫자에 주목하기도 하고 '크다'라는 부연적 의미에 주목하기도 한다.
숫자에 주목하면 회귀, 의미에 주목하면 분류가 된다.
예를 들어 어제의 예시에서 우리의 최종적 관심대상 y는 맥도날드의 매출이었다. 우리는 매출이 얼마 만큼의 숫자로 표현되는지에 관심을 들였으므로, 이것은 회귀 문제다. x는 날씨 정보였는데, 만약 우리의 최종적 관심대상 y가 어떤 다른 지역의 날씨가 맑은지에 대한 여부(false=0, true=1)라면? 숫자의 양적 크기보다는 부연적 의미(0보다 1에 가까울 때 그 지역의 날씨가 맑을 것으로 더 확신함)에 주목하고 있으므로, 이것은 분류 문제다.
관심
그래서 데이터과학에서는 내가 무엇에 관심이 있으며, 그것을 어떤 시각으로 바라보고 있는지가 중요하다. 또한, 그 시각은 실험의 과정에서 계속 변한다. 예상대로 결과가 나올 수록 입장이 강화되고, 그렇지 않으면 현재의 방식에 대해 고민하게 되는 방식으로 말이다.
기회가 되면, 언젠가는 직접 실제의 데이터를 활용해 분석하는 과정을 글로 써보고 싶다. 내가 실력이 충분해졌다고 판단하면 말이다. 그 전에는 이렇게 이론적인 내용을 위주로 글을 전개할 것이다. 다음 시간에는 지도학습의 결과를 평가하는 기준인 '일반화'에 대해 이야기해보자.

![[이미지 출처 (클릭)]](https://cdn.kastatic.org/ka-perseus-graphie/082fc77f4f368712b64c6b8c82d41db9e7aa2dfa.svg){kind=link}
![[이미지 출처 (클릭)]](https://cdn.prod.website-files.com/5fb24a974499e90dae242d98/621608ae7abbdc500080ef96_23.png){kind=link}