오늘은 지도학습 개요를 마무리해보려 한다. 마지막으로 다뤄볼 내용은 모델의 복잡도, 평가지표다.
모델의 복잡도
여기서 말하는 '모델'은 지도학습 알고리즘처럼 훈련 데이터셋을 학습하고 테스트 데이터셋에 대해 예측을 수행할 가상의 주체를 말한다. 인공지능이라고 쉽게 이해할 수도 있겠다. 모델의 '복잡도'란 무엇일까?
복잡도는 영어로 complexity다. com(함께)+plex(묶임)이다. 여러 대상을 묶어놓은 상태로, 쉽게 풀어놓지 않아서 이해하기가 어려운 상태라고 생각해볼 수 있다. 한자로 하면 복잡(複雜)이다. 복(複)은 이미 발자국을 남긴 길(夂의 윗부분)을 따라 되돌아가는(夂) 것처럼 '옷(衣)을 입었는데 또 입는다'는 뜻이고, 잡(雜)은 옷(木의 윗부분)이 걸린 나무(木)에 웬 새(隹)가 날아들어 어수선해졌다는 뜻이다. 어수선하게, 겹겹이 싸인 상태를 표현한 단어로 생각해볼 수 있다.
종합하면 복잡도는 얼마나 이해하기가 어려운가, 얼마나 베일에 싸여 있는가를 말한다. 그렇다면 모델의 복잡도란? 그 알고리즘이 예측을 하는 기준이 얼마나 복잡한지를 뜻하는 것으로 생각해볼 수 있다.
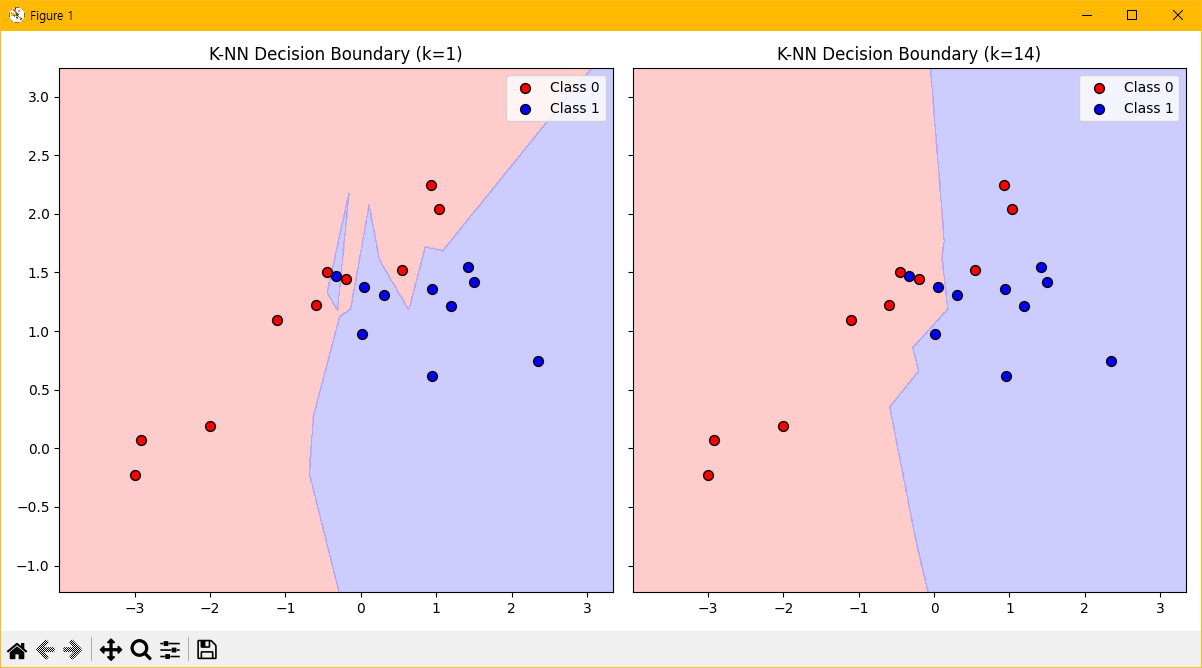 이 사진을 보라. 점들의 위치와 색깔은 좌우 그래프에서 동일하다. 다른 것은 배경의 영역뿐이다. 일단 직관적으로, 어느 쪽의 영역이 더 단순하게 생겼는가? 오른쪽이다. 거의 세로선을 절반으로 딱 자른 것에 가깝게 그려져있다.
이 사진을 보라. 점들의 위치와 색깔은 좌우 그래프에서 동일하다. 다른 것은 배경의 영역뿐이다. 일단 직관적으로, 어느 쪽의 영역이 더 단순하게 생겼는가? 오른쪽이다. 거의 세로선을 절반으로 딱 자른 것에 가깝게 그려져있다.
위 사진은 지도학습 알고리즘의 일종으로 다음에 다룰 K-NN 알고리즘을 다르게 설정한 두 경우에 형성된 모델의 의사결정 기준을 보여준다. 우리가 아직 K-NN이 뭔지 몰라도, 오른쪽의 기준선이 왼쪽의 기준선보다는 훨씬 단순하다고 쉽게 생각해볼 수 있다. 따라서 오른쪽 모델의 복잡도가 낮다고 판단한다.
평가지표
두 그래프의 제목을 보면 각각 k=1, k=14라는 문구가 있다. 각 알고리즘에 k라는 설정값을 1, 14로 준 모델이라는 뜻이다. 이는 1과 14 말고 다른 값을 더 다양하게 넣는 경우들이 존재할 수 있음을 내포한다.
모델의 설정값에 따라 모델의 의사결정 기준이 달라진다면, 어떤 설정값을 가진 모델이 가장 나은 모델인가? 우리의 관점으로 서술하자면, '대체 어느 모델을 선택해야 하나?'의 문제가 남았다. 모델도 의사결정을 하지만, 우리에게는 더 중요한 의사결정이 남은 것이다.
굳이 선택을 해야돼? 그러지 말고 두 모델을 다 남겨놓으면 데이터에 대한 시야가 넓어져서 좋은 것 아닌가?
..라고 생각해볼 수 있겠지만, 애초에 지도학습이란 '정보의 압축'이라고 이야기했다. 무수한 데이터에 대해 정보를 압축하려고 기법을 도입했는데, 여전히 무수히 많은 모델들이 남아있다면 유용한 정보를 얻어내는 절차를 완전히 끝냈다고 볼 수 없다. 물론 참고용으로 다른 모델들을 남겨둘 순 있겠지만, 적어도 '이 중에 최고는 무엇인가?'에 대해 고민하는 과정은 '정보의 압축'이라는 과정을 계속하기 위해 필요하다는 것이다.
그런데 사실 최고의 모델을 판단하는 것은 불가능하다. 그러니까, 어떤 모델을 콕 집어서 '이게 최고네~'라고 말할 근거는 없다는 뜻이다. 의사결정의 기준선이 단순하다고 좋은 모델인가? 혹은 복잡하면 좋은 모델인가? 아무도 모른다.
그 절대적인 기준을 만들어보려고 조상님들(?)과 선배님들이 노력해본 흔적이 바로 평가지표다. 평가지표는 오로지 주어진 데이터셋 내에서만 유효한 모델 선택기준이다. 따라서 미래에도 그 모델이 잘 적용될 것이라는 것을 '절대' 보장해주지 못한다. 그럼에도 미래를 보장받고 싶어하는 인간의 나약한 본성으로 인해 국소적으로라도 적용되는 평가지표가 세상에 등장하였고, 실제로 어떤 종류의 문제에는 어떤 평가지표를 이용하면 좋다는 의견들이 퍼져있기도 하다. 물론, 의견일 뿐이지만 말이다.
지난 01-3에서 소개했던 '오차'라는 개념이 사실 평가지표의 일종이다. 오차는 그 모델이 얼마나 '부적합'한지를 측정하는 수단인 것이고, 반대로 그 모델이 얼마나 '적합'한지를 측정하는 수단도 많다. 그러한 구체적인 종류들에 대해서는 굳이 이번 글에서 다루지 않을 것이다. 어차피 구체적인 알고리즘에 대해 배우지 않고서 구체적인 평가지표를 논하는 것은 딱히 이해가 되지 않을 것이기 때문이다.
정리
그래서 이번 글까지 지도학습에 대해 여러 측면으로 정리해보았다. 지도학습은 총체적으로 보면 '미래를 알고자 하는 인간의 노력'이다. 그 과정에서 과거를 미래처럼 속이는 환상에 빠지기도 하지만, 스스로 무엇을 속이고 있는지를 알면 적어도 자기의 속임수에 자기가 넘어가진 않을 것이다.
앞으로도 지도학습에 대해서 글을 올릴 것이다. 어떤 데이터셋을 예시로 지도학습 알고리즘들을 소개할지 벌써 기대가 된다.
