
공부한 내용
< Graph Neural network (GNN) >
- Graph를 사용하는 이유
- 관계, 상호작용과 같은 추상적인 개념을 다루기에 적합 (SNS, 바이러스 확산, 유저-아이템 소비 관계 등을 모델링 가능)
- Non-Euclidean Space의 표현 및 학습이 가능 (왼쪽 : Euclidean space, 오른쪽 : Non-Euclidean space)
목적 : 이웃 노드들 간의 정보를 이용해서 특정 노드를 잘 표현할 수 있는 특징(벡터)을 잘 찾아내는 것.
방법 : 그래프 및 feature 데이터를 인접 행렬로 변환하여 MLP에 사용하는 방법 등이 있음. (naive approach)
naive approach 한계 : 노드가 많아질수록 연산량이 기하급수적으로 많아지며, 노드의 순서가 바뀌면 의미가 달라질 수 있음.
-> local connectivity, shared weights, multi-layer를 이용하여 convolution 효과를 만들면, 연산량을 줄이면서 깊은 네트워크로 간접적인 관계 특징까지 추출 가능
< Neural Graph Collaborative Filetering (NGCF) >
기본 아이디어 : GNN을 통해 High-order Connectivity를 임베딩 (경로가 1보다 큰 연결을 의미)
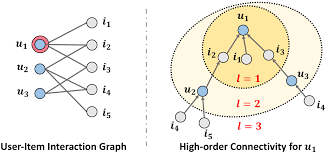
전체 구조
1. Embedding Layer
2. Embedding propagation Layer : high-order connectivity 학습
3. 유저-아이템 선호도 예측 레이어 (Prediction Layer) : 서로 다른 전파 레이더에서 refine된 임베딩 concat
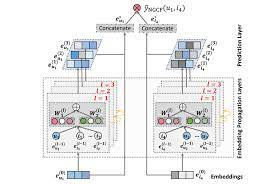
결과 및 요약 : 임베딩 전파 레이터가 많아질수록 모델의 추천 성능 향상 (but, layer가 너무 많이 쌓이면 overfitting 발생 가능 -> 실험 결과, 대략 L=3~4일 때 가장 좋은 성능을 보임)
< Context-aware Recommender System >
유저와 아이템 간 상호작용 정보 뿐만 아니라, 맥락(context)적 정보도 함께 반영하는 추천시스템
-> X를 통해 Y의 값을 추론하는 일반적인 예측 문제에 두로 사용 가능 --> General Predictor
- CTR 예측 : 유저가 주어진 아이템을 클릭할 확률을 예측하는 문제
- 예측해야 하는 y값은 클릭 여부, 즉 0 또는 1이므로 이진 분류 문제
- 모델에서 출력한 실수 값을 시그모이드(sigmoid) 함수에 통과시키면 (0,1) 사이의 예측 CTR값이 됨.
- 광고에 주로 사용 -> 다양한 유저, 광고, 컨텍스트 피처를 모델의 입력 변수로 사용
< Factorization Machine (FM) >
SVM(비선형 데이터셋에 높은 성능)과 Factorization Model(sparse한 데이터에 높은 성능)의 장점을 결합함.
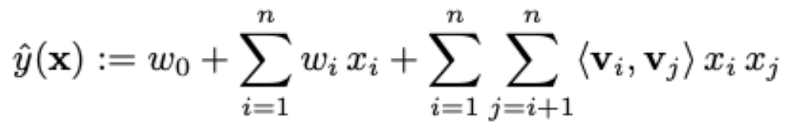
FM의 장점
- vs. SVM
- 매우 sparse한 데이터에 대해서 높은 예측 성능을 보임
- 선형 복잡도(O(kn))를 가지므로 수십 억개의 학습 데이터에 대해서도 빠르게 학습함. 모델의 학습에 필요한 파라미터의 개수도 선형적으로 비례함 (SVM은 data가 늘어날수록 학습수 많아짐)
- vs. Matrix Factorization
- 여러 예측 문제(회귀/분류/랭킹)에 모두 활용 가능한 범용적인 지도 학습 모델
- 일반적인 실수 변수(real-value feature)를 모델의 입력으로 사용
MF와 비교했을 때 유저, 아이템 ID 외에 다른 부가 정보들을 모델의 피쳐로 사용할 수 있음.
예측방법
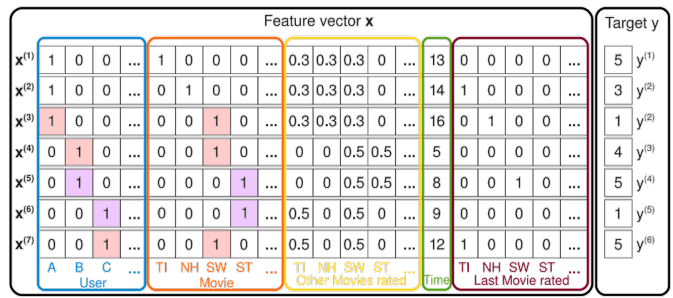
유저 A의 ST에 대한 평점 예측 -> , 가 FM모델을 통해 학습되기 때문에 상호작용이 반영됨
-
: 유저 B,C가 유저A와 공유하는 영화 SW의 평점 데이터를 통해 학습됨
-
: 유저 B,C의 영화 ST에 대한 평점 데이터를 통해 학습됨 (유저 B,C는 영화 ST외에 다른 영화도 평가함)
< Field-aware Factorization Machine (FFM) >
FM을 발전시킨 모델로서 입력 변수를 필드(field)로 나누어, 필드별로 서로 다른 latent factor를 가지도록 factorizae함
-> 기존의 FM은 하나의 변수에 대해서 k개로 factorize했으나 FFM은 f개의 필드에 대해 각각 k개로 factorize함.
Field는 모델을 설계할 때 함께 사용자가 정의
ex)
유저 : 성별, 디바이스, 운영체제
아이템 : 광고, 카테고리
컨텍스트 : 어플리케이션, 배너
FM vs. FFM
광고 클릭 데이터가 존재하고 사용할 수 있는 feature가 총 세 개(Publisher, Advertiser, Gender)일 때,
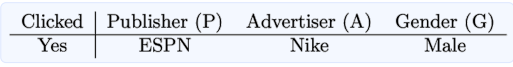
| Factorization Machine | Field-aware Factorization Machine |
|---|---|
| - 필드가 존재하지 않음 | - 각각의 feature를 필드 P, A, G로 정의 |
| - 하나의 변수에 대해 factorization 차원()만큼의 파라미터를 학습 | - 하나의 변수에 대해서 필드 개수(f)와 factorization 차원()의 곱()만큼의 파라미터를 학습 |
| : linear term, : factorization term) | : linear term, : factorization term) |
< DeepCTR >
CTR 예측에 딥러닝이 필요한 이유
- 현실의 CTR 데이터(ex. 광고 데이터)를 기존의 선형 모델로 예측하는 데에는 한계가 있음
- Highly sparse & super high-dimensional features
- Highly non-linear association between the features
-> 이러한 데이터에 효과적인 딥러닝 기법들이 CTR 예측 문제에 적용되기 시작
< DeepFM >
DeepFM = Factorization Machine(wide component) + Deep Neural Network(deep component)
- 추천시스템에서는 implicit feature interaction을 학습하는 것이 중요함
예시 : 10대 남성은 슈팅/RPG게임을 선호 (order-3 interaction)
-> 3개의 featrue가 동시에 ineraction했을 대 CTR이 높아진다는 것을 modeling해줘야함 - 기존 모델들은 low-나 high-oder interaction 중 어느 한 쪽에만 강함
Wild&Deep 모델은 이 둘을 통합하여 문제를 해결했으나, wide component에 feature engineering이 필요하다는 단점이 있음 -> FM을 wide component로 사용하여 입력값을 공유하도록함.
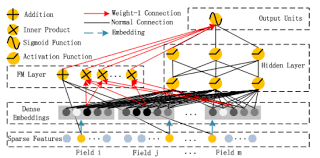
- 모든 feature들은 동일한 차원()의 임베딩으로 치환됨
이 때, 임베딩에 사용되는 가중치는 FM Component의 가중치()와 동일함.
< Deep Interest Network (DIN) >
기존의 딥러닝 기반 모델들은 모두 유사한 Embedding&MLP 패러다임을 따름
- sparse feature들을 저차원 임베딩으로 변환 후 fully connected layer(=MLP)의 입력으로 사용
이러한 기존의 방식은 다양한 관심사를 반영할 수 없음
ex) 여러 종류의 식재료와 생필품을 동시에 찾아볼 때
-> 사용자가 기존에 소비한 아이템의 리스트를 User Behavior Feature를 만들어, 예측 대상 아이템와 이미 소비한 아이템 사이의 관련성을 학습
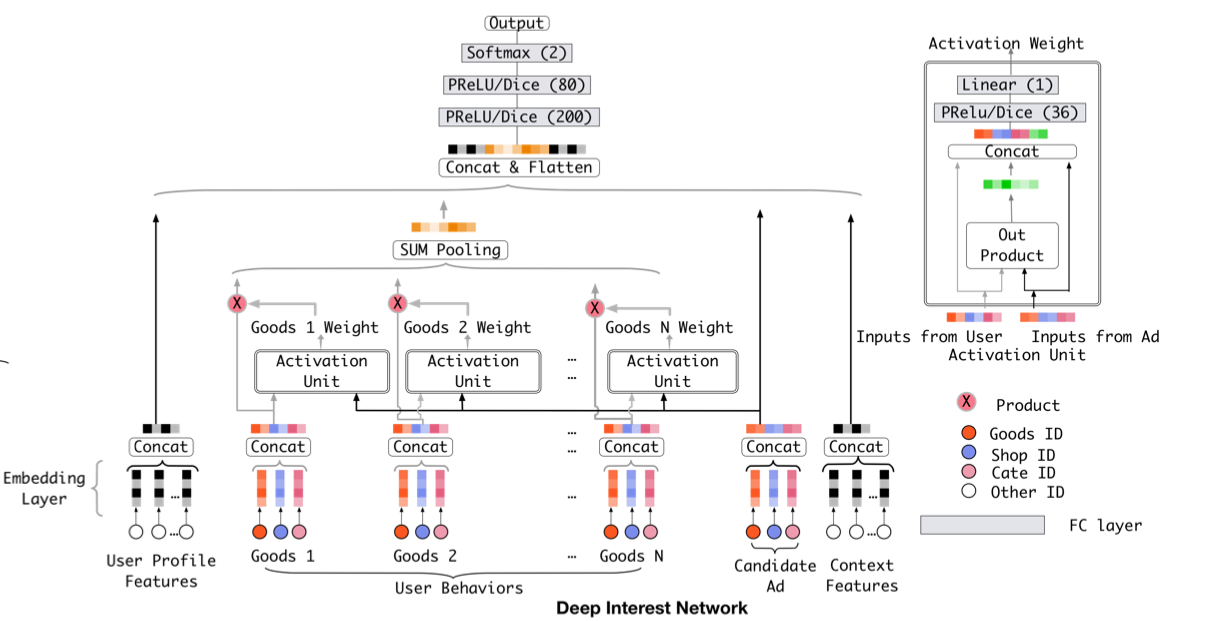
모델 구성
- Embedding Layer
- Local Activation Layer
- Local Activation Unit : 후보군이 되는 광고를 기존에 본 광고들의 연관성을 계산하여 가중치로 표현
- 후보 광고에 따라 과거 User Behavior에서 소비했던 광고들의 weight 크기가 달라짐
- Weighted Sum Pooling : 여러 개의 표현 벡터를 가중 합한 값을 출력으로 사용
- Fully-connected Layer
학습 회고 💁
저번주와 마찬가지로 모든 강의가 소화되지 않았다😥 모든 강의를 다 듣자는 마인드로 머리속에 넣다보니 다시 앞에 들었던 내용을 보면 매번 볼 때마다 새롭다.
드디어 lv2, lv3 팀을 찾았다. 사실 팀을 구해야겠다고 생각만 하고 느긋했는데, [구팀 중]에서 [구팀완료]로 바뀌신분들이 엄청 많아 갑자기 급해졌었다. 나에게 컨택하신분도 계시고 내가 컨택하자고 한 팀도 있었다. 지금 선택한 팀은 팀원들도 다들 좋아보이시고 분위기도 좋은것 같아서 선택했다. 기술 스택이 높지 않은 나를 받아주신 팀원들께 감사를... 꼭 공부를 배로 해야할 것 같다😅
이번주 일요일에는 처음으로 현재 팀원들을 만나기로 했다!!! 기대되면서 떨리는 중!!!
