업스테이지에서 LLM에 대한 논문을 공개했다.
논문에서는 LLM에 대한 전반적인 동향을 다루고 다음과 같은 내용을 다룬다.
- 초기의 언어모델부터 현재의 초거대 언어모델까지의 연구 및 발전과정
- 한국어 초거대 언어모델의 특징 및 최신 동향
- 최신 초거대 언어모델 연구 동향
- 초거대 언어모델의 성능 평가 방식과 그 변화
- 초거대 언어모델 연구와 활용에 있어 중요하게 여겨지는 윤리적 원칙과 관련된 최근의 동향
논문은 여기에서 볼 수 있습니다!
1. 서론
LLM은 최근 몇 년간 뛰어난 발전을 하고 이루고 있다.
- 교육, 의료, 금융, 제조 등 거의 모든 산업 분야에서 광범위한 활용 가능성을 제시한다.
but, 한계점과 위험성도 존재
- 학습 데이터의 편향성을 그대로 반영할 수 있어, 편향된 결과나 추천을 할 가능성이 있음.
- 의사 결정을 위해 LLM을 활용하는 경우 문제
- 악의적인 목적으로 사용하는 위험성
- 미스리딩 정보 생성이나 편향된 정보 전파
- LLM의 동작 윈리, 결과에 대한 설명력 부족, 최신 정보를 반영하는 데의 한계 등
2. 언어모델부터 초거대언어모델까지
자연어 : "인간의 언어"
자연어처리 : 자연어를 컴퓨터가 처리하는 것
(인간의 언어표현 체계를 컴퓨터가 이해할 수 있는 형태로 변환)
2.1. 전통적인 언어모델
인간이 사용하는 단어를 컴퓨터가 이해할 수 있는 숫자 체계로 변환하는데에 초점을 맞춰 발전했다.
대표적인 방법은 one-hot encoding이다.
- one-hot encoding : 원하는 곳에만 1을 표시, 나머지는 0으로 표시
하지만, 이런 방식으로는 이들 간의 의미적인 연관을 찾지 못한다.
-> 의미기반 언어모델 연구
2.2. 의미기반 언어모델
의미기반 언어모델 연구는 단어 간의 의미적인 연관성을 고려하기 위해 dense vector 공간에 표현하는 데에 초점 맞춰 발전했다.
대표적인 의미기반 언어모델 : Word2Vector
- Word2Vector : 주변 단어들로부터 중심 단어를 예측하거나 중심 단어로 주변 단어들을 예측하도록 학습함으로써, 유사한 의미의 단어들을 dense vector 공간 상 가까운 거리에 분포하도록 학습시킨다.
전통적인 언어모델의 한계는 극복했지만, 문맥을 파악하지 못한다는 한계를 가지고 있다.
2.3. 문맥기반 언어모델
2.3.1 단방향 문맥기반 언어모델
문맥 정보를 반영하여 언어를 표현하기 위해, 텍스트 내의 정보를 이용하는 RNN (Recurrent Neural Network) 등장했다.
RNN (Recurrent Neural Network), LSTM (Long Short-Term Memory), GRU (Gated Recurrent Unit) 등이 등장했지만, 텍스트에 존재하는 단방향 문맥 정보만 활용한다는 한계를 지닌다.
2.3.2 양방향 문맥기반 언어모델
ELMo는 주어진 텍스트에 존재하는 순방향 문맥 정보와 역방향 문맥 정보를 함께 활용하는 양방향 학습을 제안했다.
LSTM이 지니는 한계를 그대로 지닌다.
- 하나의 벡터에 텍스트의 모든 정보를 담기 떄문에
정보소실발생 - 입력 텍스트의 길이가 길어지만
기울기 소실 (gradient vanishing)발생
이런 한계를 해결하기 위해 Attention Mechanism과 이를 활용한 Transformer Architecture가 나왔다.
2.4. Attention Mechanism
하나의 벡터에 텍스트의 모든 정보를 담는 RNN, LSTM, GRU와 다르게, 텍스트 내 단어들의 벡터들을 필요에 따라 적절히 활용하는 메커니즘
현재 언어모델의 근간이 되는 Transformer가 Attention Mechanism을 기반으로 한다.
Transformer은 크게 인코더와 디코더로 구성
- 인코더를 기반으로 발전한 대표 모델 : BERT (Bidirectional Encoder Representations from Transformers)
- 디코더를 기반으로 발전한 대표 모델 : GPT (Generative Pretrained Transformer)
문맥기반 언어모델 이후, 모델 및 학습 데이터의 크기와 모델의 성능은 긍정적인 상관 관계를 보인다는 scailing law가 발혀지면서, LLM (Large Language Model) 이 등장하기 시작했다.
2.5. Prompt Engineering
LLM의 능력을 잘 이끌어내기 위한 연구 분야 -> 프롬프트 엔지니어링
Prompt Engineering이란?
LLM이 모델 가중치 업데이트 없이 특정 테스크를 더욱 잘 해결하게 하기 위해, 입력으로 주는 프롬프트를 어떻게 설계할 것인지에 대한 연구 분야.
대표적인 프롬프트 엔지니어링 연구는 Chain-of-Thought(CoT)가 있다.
- Chain-of-Thought(CoT) : 해결하고자 하는 태스크의 예시를 넣어줌으로써, 복잡한 문제를 여러 단계로 나누어 해결
2.6. LLM 학습 기법 - Fine-Tuning
LLM의 조종성 (Steerability)을 높이기 위해 여러 학습 방법이 등장
- Instruction Tuning
- Reinforcement Learning from Human Feedback (RLHF)
3. 한국어 초거대 언어모델 동향
GPT, PALM, Falcon, Llama, Claude, Qwen 같은 모델이 연구되고 있지만, 한국어를 비효율적으로 토큰화하고, 학습한 한국어 토큰 수가 매우 부족하다는 한계를 가진다.
이를 필요성에 따라, 최근 많은 국내 기업에서 한국어 LLM을 자체적으로 학습하기 시작했다. (Naver Clova, LG AI Research, Kako Bran 등)
오픈소스 한국어 LLM도 존재하는데 대표적인 모델이 EleutherAI의 Polyglot-Ko이다.
공개된 이 모델을 통해 미세조정 등을 하여 활발히 연구하고 있다.
이와 같이 한국어 LLM의 빠른 발전을 위해 오픈소스 한국어 LLM이 더 많이 공개되는 것이 필요하다.
한국어 LLM 학습을 위해 사용된 한국어 공개 데이터셋 : AI-Hub, 모두의 말뭉치, 위키백과, 청와대 국민 청원 등
-> 큰 도움이 되지만, 여전히 학습할 고품질 한국어 데이터가 부족하여
-> 한국어 LLM은 아직까지 사용자가 만족하기에는 불충분한 성능을 보인다.
4. 최신 초거대 언어모델 연구 동향
4.1. 사전학습
언어 생성 및 문맥 이해 능력 등을 모델에 학습시킴으로써 LLM의 근간을 형성하는 과정이다.
4.1.1 데이터 활용 현황
사전학습을 위해 웹페이지, 책, 대화 데이터, 학술 데이터, 코드 등 다양한 종류의 이질적인 코퍼스를 혼합하여 활용하는 추세이다.
4.1.2 전처리
데이터의 크기와 노이즈, 중복, 독성 데이터 등의 존재로 인해 여러 문제를 야기 할 수 있기 때문에 데이터 전처리는 필수적이다.
이러한 전처리 과정은 크게 품질 필터링, 중복 제거, 개인정보 제거, 토큰화의 순으로 이루어진다.
- 품질 필터링 (quality filtering) : 수집된 데이터에서 저품질의 데이터를 걸러낸다.
- 제거 (de-duplication) : 반복되는 단어를 갖는 저품질 문장, 단어 및 N-gram 기반 겹침 비율을 기반하여 유사한 내용을 갖는 문서들을 필터링한다.
- 개인정보 제거 (privacy reduction) : 메일 주소나 전화번호와 같은 민감 정보 추출한다.
- 토큰화 : 원본 텍스트를 토큰으로 분리하는 작업이 수행된다.
4.2 미세조정
미세조정의 대표적인 전량으로는 Instruction Tuning과 Alignment Tuning이 있다.
- Instruction Tuning: 기존에 본 적 없는 태스크에 대한 일반화 능력을 향상시키는 법 (unseen task generalization ability)
- Alignment Tuning : LLM의 출력을 인간의 가치아ㅗ 기준에 부합하도록 조정하는 접근법
4.2.1. Instruction Tuning
사전학습된 LLM을 대상으로 자연어로 이루어진 포맷팅 지시사항과 그에 대응하는 ouput 쌍으로 이루어진 데이터를 기반으로 미세조정하는 추가 훈련 과정을 말한다.
Instruction Tuning을 위해서는
태스크의 의미를 LLM이 이해할 수 있도록 관련 지시사항과 이에 대응하는 출력으로 이루어진 자연어 포맷의 데이터를 구성해야한다.
ex) 번역, 요약, QA, 일상적인 대화 데이터 등
4.2.2. Alignment Tuning
주로 MLM 또는 NTP 형태의 목적함수를 가지고 학습
주변 또는 이전 컨텍스트를 기반으로 단어 예측
따라서, 사전학습 과정에서 인간의 선호가 반영된다고 보기 어렵다.
LLM은 종종 유해한 또는 잘못된 정보의 제공이나 편향된 표현을 생성하기도 한다.
이를 방지하기 위해 LLM을 인간의 기대치에 맞게 조정하는 human alignment 방식이 있다.
but, 이 방식은 고품질의 human feedback 수집이 필수적이기 때문에 cost가 많이 든다.
이러한 alignment criteria는 대부분 인간의 인식으로 기반으로 하므로 LLM에 최종적으로 적용하기 어렵다.
LLM을 인간의 가지와 일치시키는 방법인 RLHF(강화 학습) 제안되었다.
RLHF : 인간의 피드백을 바탕으로 보상 모델을 학습하면서 LLM을 적응시킨다.
+ 추가 예정
4.2.3. Resource-Efficient Fine-Tuning
LLM의 계산 집약적 특성으로 인한 한계를 개선하기 위한 방법론이다.
LLM들은 수많은 모델 파라미터를 가지기 때문에, 각 미세조정 시에 모든 파라미터를 튜닝하는 것은 비용 관점에서 비효율적이다.
-> 가능한 성능을 유지하면서, 학습가능한 파라미터의 수를 줄이는PEFT (Parameter-Efficient Fine-Tuning)
Adaptor Tuning : Transformer 구조에 adaptor라 부르는 작은 신경망 모듈을 추가한다. 이는 원래 고정된 상태인 모델의 파라미터를 adaptor 모듈의 파라미터만 특정 태스크 목적을 달성하기 위해 최적화 된다.
예로는 Low-Rank Adaption (LoRA)가 있고 PEFT에 low-rank approximation을 차용한다.
4.3. 활용 및 증강
4.3.1. Utilization of LLMs
LLM을 활용하는 가장 대표적인 방법 중 하나는 태스크를 해결하기 위한 적절한 프롬프팅 전량을 수립하는 것이다.
대표적인 프롬프팅 방법으로는 in-context learning (ICL)이 있다.
- ICL : 시연 (demonstratin) 형태의 몇 가지 예시만으로 언어 모델이 태스크를 학습하게 하는 방식
ICL의 이점은 다음과 같다.
1. 자연어 형태로 제공되는 시연은 LLM과이 명확하고 이해하기 쉬운 소통 방식을 제공한다.
2. 유사성에서 학습하는 인간의 의사결정 과정과 비슷한 측면이 있다.
3. 전통적인 지도학습 방식에 비해 training-free learning을 가지고 있어, 새로운 태스크 적응에 필요한 계산 비용을 크게 줄일 수 있으며, 확장 가능한 (scalable) 특성을 지닌다.
추론 능력을 보다 강화하기 위해 연구로 CoT가 소개되었다.
CoT 프롬프팅은 입력-출력 매핑을 여러 중간 단계로 분해함으로써,
산술 추론, 상식 추론 및 기호 추론 등의 복잡한 추론 태스크에서 LLM의 성능을 향상 시킬 수 있다.
4.3.2. Augmented LLMs
- 구조적으로 그럴듯하게 보이는 컨텐츠를 생성하는 환각 등의 내재적인 한계
- 자연어 코스퍼를 활용하여 학습하기 때문에, NLP 태스크가 아닌 산술 추론 등에 약점을 지님.
- 대용량의 지식 등을 기억해야 하고 결과적으로 많은 수의 파라키터를 요구
이런 내재적인 한계를 해결하고 적은 수의 파라미터로도 목적을 달성할 수 있도록, LLM을 추론 (reasoning) 및 도구 사용 (use tools) 관점에서 강화한 모델을 Augmented LLMs이라 부른다.
* RAG (Retrieval Augmented Generation)
LLM이 외부의 지식 또는 정보에 효과적으로 접근하여 활용할 수 있다면,
모든 지식을 내부에 저장하는 것 대신, 필요한 정보를 외부에서 추출해 사용하면 파라미터 수를 줄일 수 있다.
이를 RAG라고 한다.
* Other Tools
- LaMDA : 대화 애플리케이션에 특화된 LLM (검색, 계산기 및 번역기 등의 외부 도구 호출 기능을 가지고 있다.)
- WebGPT : 웹 브라우저와의 상호작용을 통해 검색 쿼리에 사실 기반의 답변과 함께 출처 정보를 제공
- PAL : Python interpreter를 통한 복잡한 기호 추론 기능 제공
5. 초거대 언어모델 평가 동향
기존의 벤치마크 데이터셋 : 고도의 언어 이해 능력, 일반 상식기반의 추론 능력
LLM 등장 이후 벤치마크 데이터셋의 유효성은 크게 낮아지고 변별력이 줄어들고 있다. 벤치마크 데이터셋은 LLM의 정확한 평가를 내는데 적합하도로 보기 어렵다.
즉, LLM이 얼마나 적절하게 발현할 수 잇는지에 대한 새로운 평가 척도의 개발이 절실하다.
5.1. OpenLLM Leaderboard
HuggingFace는 OpenLLM Leaderboard를 공개하면서, 벤치마크 데이터셋을 통해 LLM의 성능을 체계적으로 평가하고 있다.
LLM이 여전히 정복하지 못한 추론능력, 환각현상, 상식능력 등을 종합적으로 검증할 수 있는 리더보드이다.
평가 방법
- ARC (AI2 Reasoning Challenge) : 초등학교 수준의 과학 문제 바탕으로 추론 능력 평가
- HellaSWAG : 일반 상식을 기반으로 한 추론 능력 평가
- MMLU : 언어모델이 광역 도메인의 지식에 대해서 사전 훈련 과정이 얼마나 이를 습득하고 발현하는지 평가 (인문학, 사회학, 과학 등 57개의 도메인에 초등학생~ 전문가 수준)
- TruthfulQA : 얼마나 높은 정보력을 바탕으로 신뢰성 있는 정보를 생산하는지 평가
5.2. Open Ko-LLM Leaderboard
한국에서도 Open LLM leaderboar가 운영되고 있다. (Open Ko-LLM leaderboard)
평가 방법
- Ko-HellaSwag
- Ko-MMLU
- Ko-Arc
- Ko-Truthful QA
- Ko-CommonGen V2
한국의 대표적인 Open LLM인 Polyglot-Ko, KULLM22, KoAlpaca23와 더불어 42MARU24, ETRI25, Maum.AI26 등 다양한 기업들이 참가하고 있다.
6. 초거대 언어모델 윤리 원칙 동향
다양한 윤리 원친에 명시된 내용은 6가지로 구분된다.
1. 인간성 (Humanity & Human-centered)
2. 책임성 (Responsibility & Accountability)
3. 보안성 (Privacy & Security)
4. 안전성 (Safety & Reliability)
5. 투명성 (Transparency & Explainability)
6. 다양성 (Fairness & Diversity)
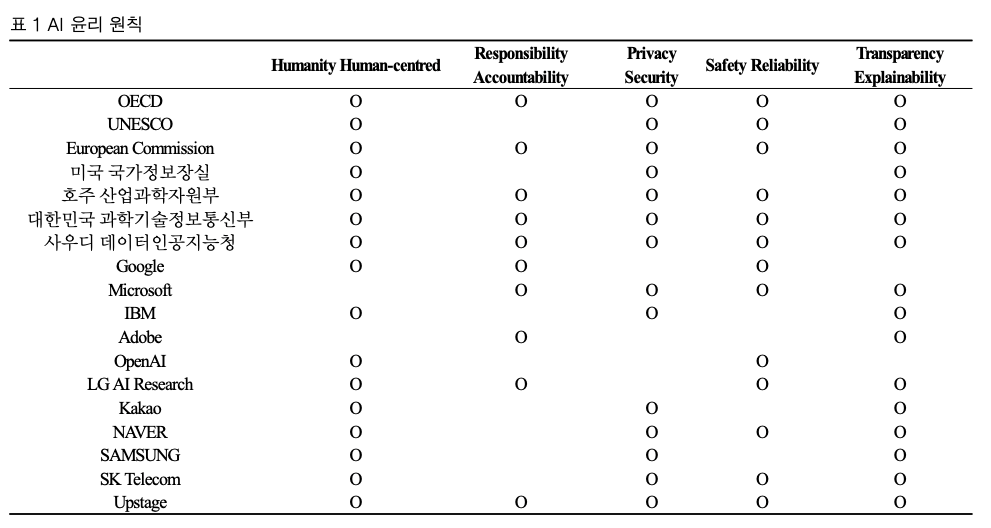
[각 기업마다 인공지능 윤리원칙 제시]
7. 결론
교육, 의료, 금융, 제조 등 다양한 산업 분야에서 LLM의 활용 가능성을 넓혔지만, 편향성, 안전성, 설명 가능성 및 쇠신성 문제는 LLM의 한계점으로 지속적으로 고려되어야하고, 문제를 해결하기 위해 중요한 도전 과제로 남아있다.
