Introduction
논문에서 소개한 EASE의 특징
- hidden layer 없다
- autoencoder로 구성
- convex training objective의 closed-form solution을 도출
- weight matrix의 대각선은 0
Input : user가 상호작용한 item
output(모델의 목표) : user에게 추천할 가장 좋은 item을 예측하는 것.
closed form
함수가 analytic하다?
→ analytic한 해를 가진다는 것은 해 x를 x = ab + c와 같이 수식으로 표현할 수 있다는 의미
analytic한 해를 가진다는 것 → closed-form solution을 가진다는 것을 의미
즉, closed-form solution은 문제에 대한 해답을 식으로 명확하게 제시할 수 있다는 것을 의미
EASE
MODEL DEFINITION
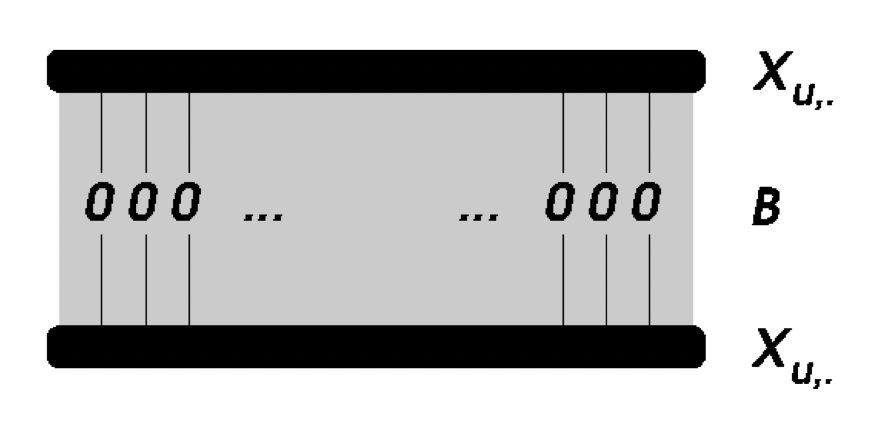
implicit feedback를 사용하는 많은 추천 논문과 마찬가지로, 입력 데이터 matrix인 는 User 와 item 이며, 를 만족한다.
X의 값은 (일반적으로 1) 사용자가 item과 상호작용했음을 나타내며, 값 0은 상호작용이 없을 의미한다.
데이터 설명
- X → U X I 행렬 (input data, binary)
- B → I X I 행렬 (model, weight, closed-form으로 훈련하는 모델)
- S → U X I 행렬 (해서 나온 predict)
Output data
user 가 아이템 에 관심이 있을 확률을 구해하는 것이 목표.
→ 입력 데이터 에 학습 파라미터 를 곱한 값을 모델이 예측한 ranking 점수로 활용.
objective function
weight B를 학습하기 위해 convex objective를 사용
- 앞에서 말했듯이 closed-form sultion을 사용하기 때문에 다른 loss function보다 데이터 와 predict score 사이의 square loss(Frobenius norm)를 선택한다.
- Frobenius norm : Euclidean Norm이라고도 부르며 대표적으로 행렬 버전의 L2-Norm이다.
matrix의 크기를 알고 싶을 때 Frobenius norm을 사용. vector의 L2 norm을 matrix로 확장한 느낌
- Frobenius norm : Euclidean Norm이라고도 부르며 대표적으로 행렬 버전의 L2-Norm이다.
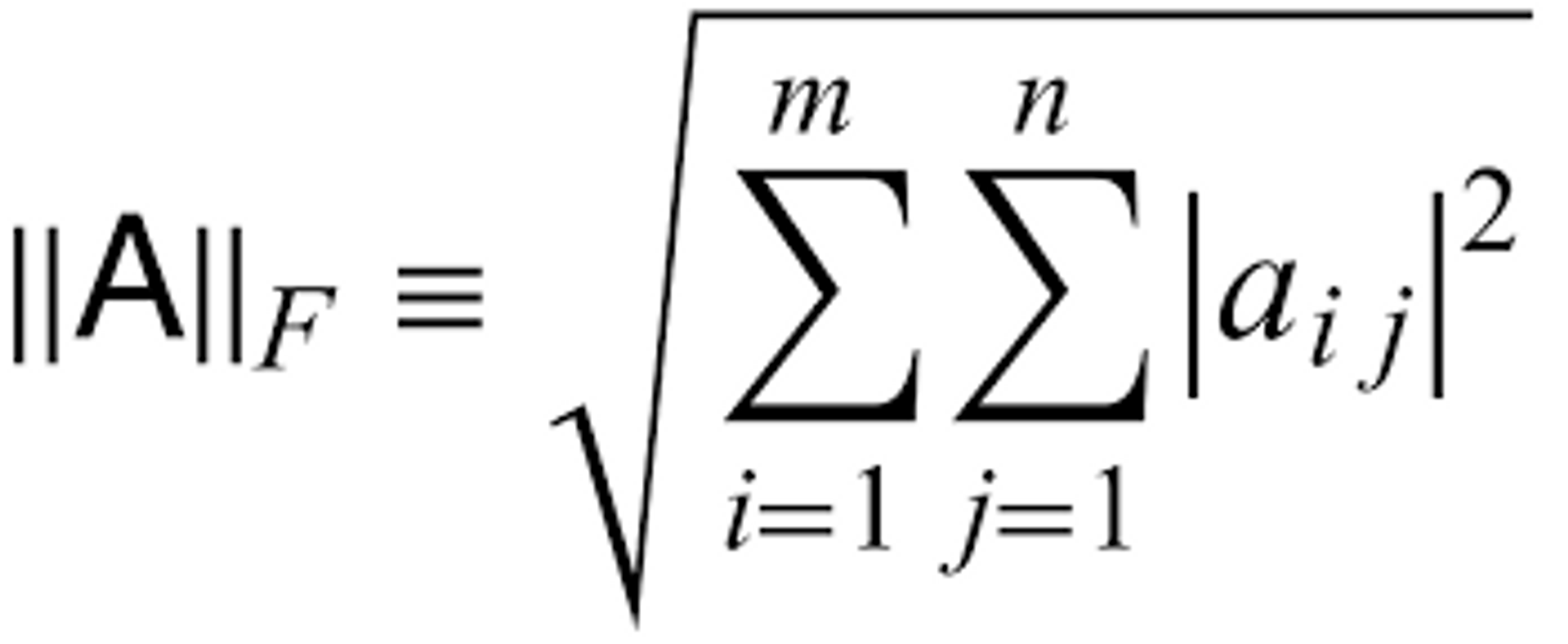
- 학습하기 위해 weight B의 L2 norm regularization 사용
- 단일 hyper-parameter : validation set에 최적화될 매개 변수
- 의 대각 성분은 0이 되어야만 한다.** → 이라는 제약이 없으면 가 단위행렬 가 되어버려서 결국 에 학습된 파라미터인 가 아니라 단위행렬 를 곱해버리는 의도치 않는 현상이 발생해버린다.
- 의 대각 성분은 0이 되어야만 한다.** → 이라는 제약이 없으면 가 단위행렬 가 되어버려서 결국 에 학습된 파라미터인 가 아니라 단위행렬 를 곱해버리는 의도치 않는 현상이 발생해버린다.
목적 함수를 최적화 하려면?
일반적인 딥러닝 모델이라면 를 파라미터로 지정해서 모델에 입력 데이터 가 들어왔을 때 목적함수이자 손실함수인 식의 계산 결과를 반환해고 역전파 알고리즘을 통해 loss를 최소화하는 gradient를 찾을 것이고, Optimizer를 통해 gradient 방향으로 파라미터 를 업데이트 해주면 된다. (단, 의 대각성분이 0이어야 한다는 조건을 만족해야하므로 목적함수 뒤에 대각성분이 0이 되지 않도록 반영된 항을 추가해줘야한다.)
Algorithm

EASE의 학습은 user-item 행렬 X가 아니라 대신 가 입력으로 들어가므로 의 크기 가 의 user-item 수보다 작으면 효율적.
item수가 user수보다 많다면 효율적이지 않을 수 있다.
Neighborhood-based Approaches
수많은 논문에서 neighborhood-based 접근이 사용되지만, 논문에서 본 저자는 EASE의 closed-form solution에서 기존 neighborhood-base 접근이 잘못되었다고 주장한다.
- 대부분의 neighborhood-based 접근법에서는 co-occurrence matrix(Gram-matrix, X′X)를 사용합니다.
- 그러나 EASE 모델에서 solution을 구해보니, 이러한 co-occurrence matrix를 그대로 사용하는 것이 아니라, 이를 inverse한 행렬을 사용하는 것이 더 정확한 방법이였다고 말하고 말하고 있습니다
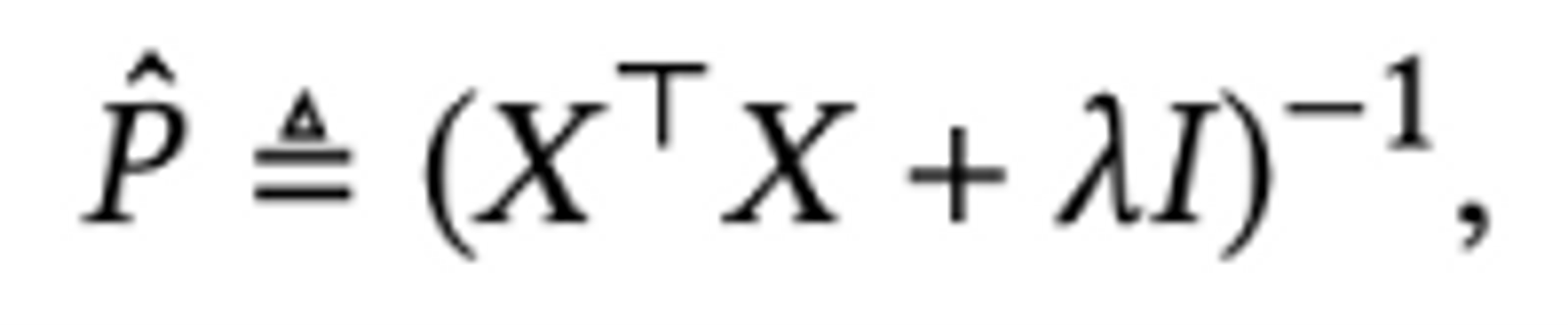
-
또한, 다른 (높은 성능을 보이는)모델들과 비교하여 우수한 성능을 보이고 있는 EASE가 원칙적인 neighborhood approach라고 볼 수 있다고 말하고 있습니다.
[참고][https://velog.io/@whattsup_kim/Embarrassingly-Shallow-Autoencoders-for-Sparse-Data2019-논문-리뷰](https://velog.io/@whattsup_kim/Embarrassingly-Shallow-Autoencoders-for-Sparse-Data2019-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0)
Gram-matrix
는 item-to-item matrix이고, 와 같은 꼴을 Gram-matrix라고 한다.
- 활동이 증가한 사용자로 인해 밀도가 높아진 에 의해 의 entry가 커질 수 있다.
- 의 사용자 수가 증가함으로써 의 entry가 커질 수 있다.
- 유저 수가 증가하면 데이터의 sparsity가 어느정도 보완될 수 있다고 주장
→ 즉, 각 사용자에 대해 사용할 수 있는 소량의 데이터(즉, 데이터 희소성)만 있을 수 있다는 문제는 데이터 matrix 의 사용자 수가 충분히 큰 경우 를 추정하는 불확실성에 영향을 미치지 않는다.
⇒ EASE가 sparse한 데이터에 robust한 모델
