생활코딩 - Tensorflow 101 강의를 듣고 요약, 필기한 내용입니다.
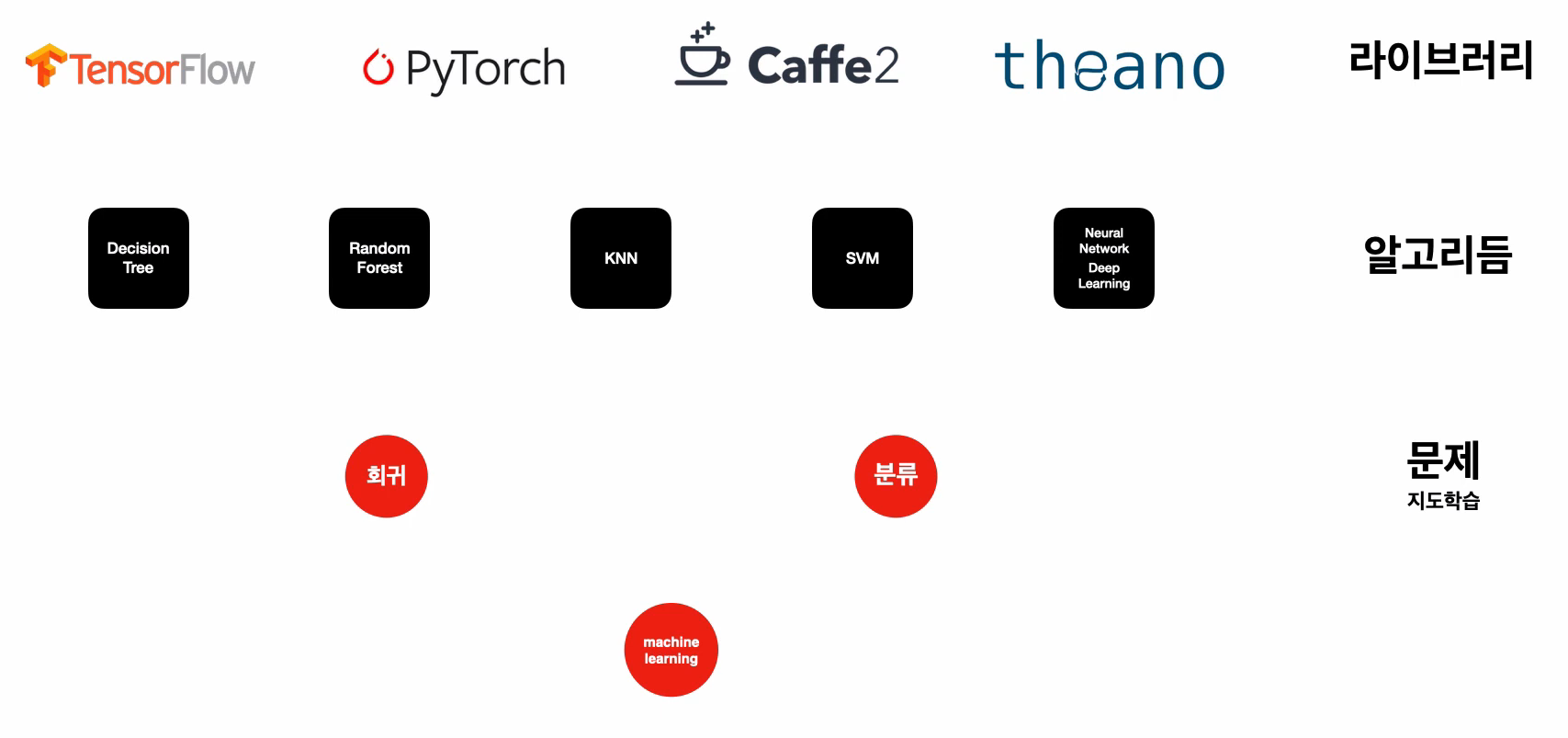
뉴럴 네트워크: 사람의 두뇌(뉴런)가 동작하는 방법을 모방한, 머신러닝 구현을 위한 알고리즘 중 하나. (= 인공 신경망, 딥러닝)
텐서플로우: 딥러닝 이론을 코드를 통해 이용할 수 있게 해주는 라이브러리 중 하나. 지도 학습 영역의 회귀 문제, 분류 문제를 해결 가능.
지도학습 과정
- 과거의 데이터 준비, 독립변수와 종속변수로 구분
- 모델의 구조를 만듦 (독립변수 n개 → 종속변수 m개)
- 데이터로 모델을 학습(FIT)시킴 (fitting, 모델을 데이터에 맞춤)
- 모델을 이용함
Google Colaboratory: 구글 드라이브에서 사용할 수 있는 데이터 분석 & 머신 러닝 프로그램.
판다스 사용법
판다스: 파이썬에서 표를 다루기 위한 라이브러리. csv 파일을 읽어서 독립/종속 변수로 분리 가능
csv: 콤마(,)를 통해 컬럼을 구분한 데이터. 엑셀로 읽으면 표 형태로 보여줌.
pd.read_csv(파일경로): 파일을 읽어서 DataFrame 타입 객체로 반환DataFrame.shape: 데이터의 행 개수와 열 개수를 튜플 객체로 반환, 형태 확인 시 사용DataFrame.columns: 데이터의 컬럼 목록을Index([컬럼명1, ...])형태로 반환DataFrame[[컬럼명1, ...]]: 데이터를 컬럼별로 분리, 독립/종속 변수 분리 시 사용DataFrame.head(): 데이터의 상위 5개 데이터까지만 출력
지도학습 과정 with 코드 구현
- 과거의 데이터 준비 (판다스 이용)
레모네이드 = pd.read_csv('lemonade.csv')
독립 = 레모네이드[['온도']]
종속 = 레모네이드[['판매량']]- 모델의 구조를 만듦 (독립변수 n개 → 종속변수 m개)
X = tf.keras.layers.Input(shape=[독립변수 개수])
Y = tf.keras.layers.Dense(종속변수 개수)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')- 데이터로 모델을 학습(FIT)시킴 (fitting, 모델을 데이터에 맞춤)
model.fit(독립, 종속, epochs=1000)
# epochs: 전체 데이터를 몇 번 반복하여 학습할 것인지- 4번째 매개변수로
verbose=0을 넣어주면 학습 과정 출력을 생략함
- 모델을 이용함
print(model.predict([[15]]))
# 입력값 15에 대한 예측값을 출력Loss
- 각 학습이 끝날 때마다 얼마나 정답에 가까이 맞추고 있는지를 나타내는 지표
- 실제 종속변수(정답)와 모델에 입력값을 넣어 얻어낸 예측 결과의 비교 수치
- 컬럼별
(예측 - 결과)^2의 평균. 0에 가까울수록 정답에 근접한 것!
- 이상치(극단값): 전체 집단의 수치와 비교하여 상이하게 높거나 낮아서 평균의 대표성을 무너뜨리는 값
- 중앙값: n개의 값을 크기 순으로 늘어놓았을 때 가장 가운데에 있는 값
- 표본에 이상치가 존재할 때, 또는 각 표본 간의 격차가 너무 클 때 평균 대신 사용할 수 있는 대푯값 중 하나.
수식과 퍼셉트론
모델의 정체는 '수식'
모델을 생성할 때 가장 먼저 입력(독립변수 + 상수)의 개수와 출력(종속변수)의 개수를 받아 대응되는 수식을 만듦.
- ex.
y = w1x1 + w2x2 + ... + w13x13 + b - 이때
w는 가중치,b는 편향(바이어스)이라 부름 Model.get_weights()로 현재 모델이 학습한 가중치와 편항을 확인 가능
퍼셉트론은 이러한 수식에 대한 모형이며, 학습의 목적은 이 수식에서 종속변수에 가장 근접하기 위한 적절한 w와 b를 찾는 것.
- 종속변수가 여러 개라면 퍼셉트론이 병렬로 연결된 구조로 표현할 수 있음.
'학습'의 원리
- 현재 w, b를 어느 방향으로 변화시켜야 loss를 줄일 수 있는가? => 미분 이용
- 미분 = 변화율
- (얼마만큼 변화시켜야 loss를 최소화할 수 있는가? => Learning Rate 찾기)
- 각 표에 적힌 수식을 참고하여 이해하기
- D6, E6 셀의
0.001은dt가 아닌 임의의 Learning Rate 값임에 유의
분류 모델
종속변수가 범주형 데이터일 때는 회귀 대신 분류 방식을 이용해야 함.
원핫-인코딩(onehot-encoding): 범주형 데이터를 수식에서 사용할 수 있는 숫자 형태로 변환하는 방법.
- ex.
A,B,C중 하나의 값을 갖는 종속변수X
→0또는1을 값으로 갖는 3개의 종속변수A,B,C로 변환
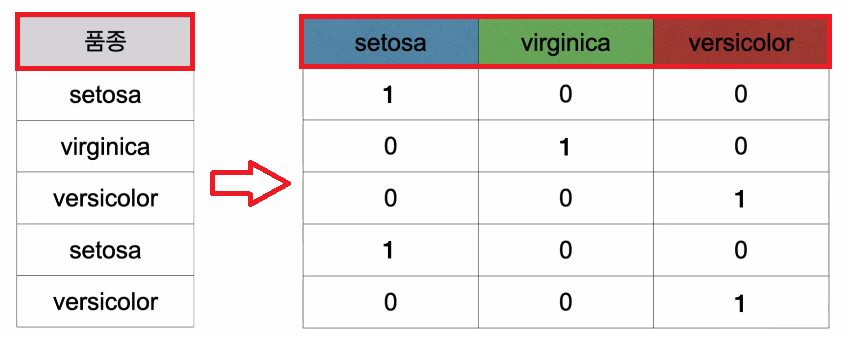
pd.get_dummies(데이터): 원본 데이터에서 범주형 변수들만 골라서 원핫-인코딩된 결과로 반환함.
활성화 함수(Activation): 퍼셉트론의 출력이 어떤 형태로 나가야 하는지 조절하는 역할을 하는 함수.
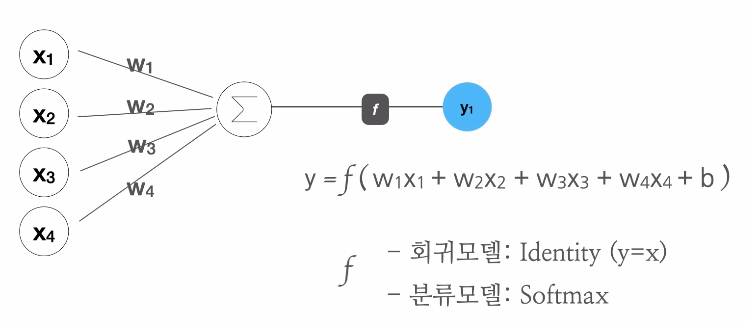
tf.keras.layers.Dense(3, activation='softmax')(X)
# Softmax 방식으로 확률 표현- Softmax: 분류 예측을 사람에게 친숙한 확률로 표현해 주는 방법 중 하나. 종속변수의 범위를 0부터 1 사이로 만들어 줌.
분류 모델에서의 loss는 MSE(Mean Squared Error) 대신 Cross Entropy를 사용함.
model.compile(loss='categorical_crossentropy')
# loss로 Cross Entropy 방식을 사용compile()의 매개변수로metrics='accuracy'를 추가하면 결과에서 0과 1 사이의 값을 가지는 정확도를 추가로 표시함
히든 레이어
딥 러닝: '깊은 신경망', 즉 여러 층의 퍼셉트론으로 구성된 인공 신경망의 학습.
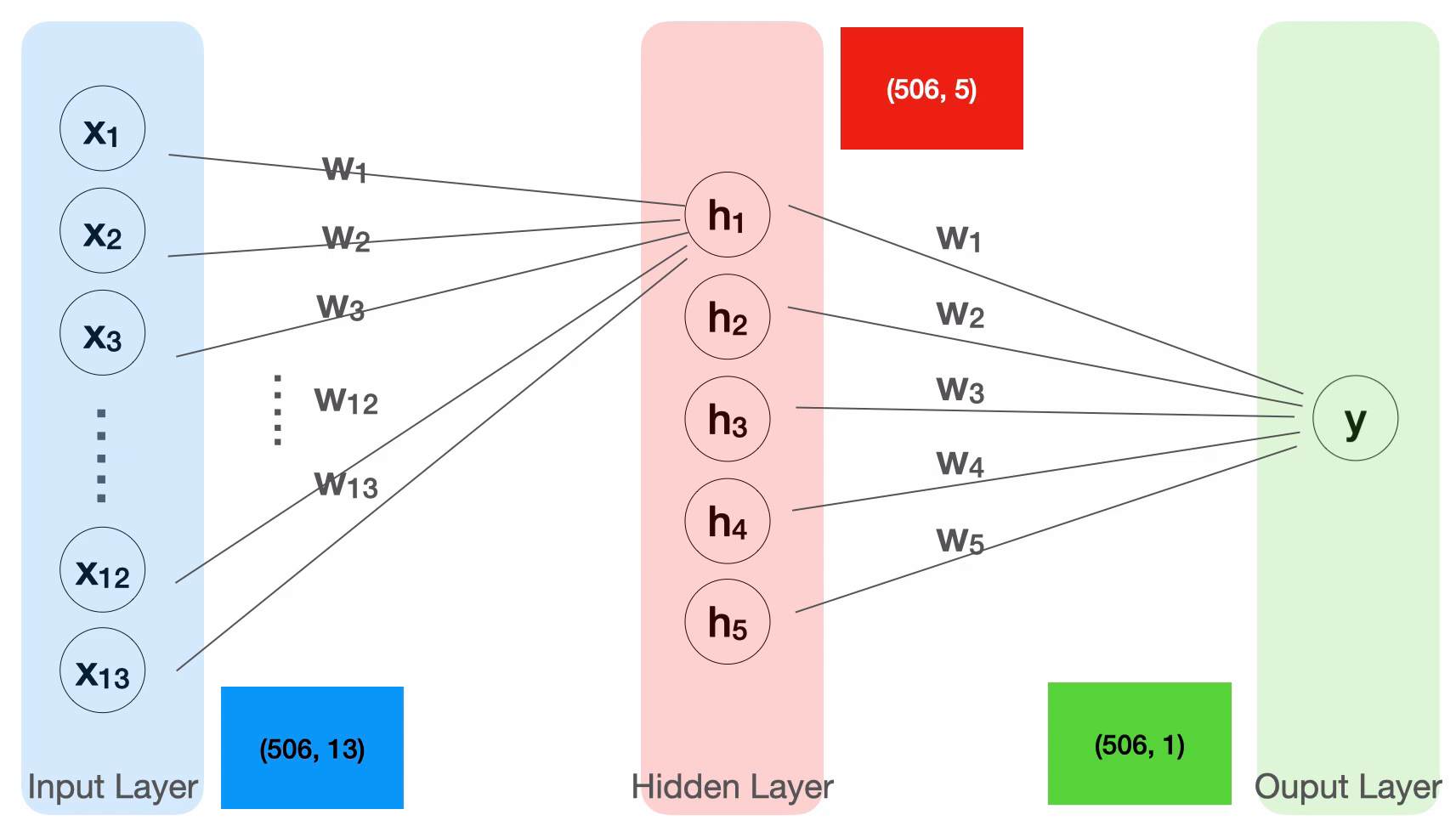
히든 레이어: 입력층과 출력층 사이에 끼어들어가는 층. 각 노드의 입력은 이전 층의 모든 노드임.
- 사용하는 이유? => 보다 복잡한 모델 = 복잡한 수식 = 더 정확히 예측할 수 있는 함수!
X = tf.keras.layers.Input(shape=[13])
# 히든 레이어 추가, 활성화 함수로 swich 사용
H = tf.keras.layers.Dense(5, activation='swish')(X)
# 2개 이상의 히든 레이어도 추가 가능!
H = tf.keras.layers.Dense(3, activation='swish')(H)
H = tf.keras.layers.Dense(3, activation='swish')(H)
# 최종 출력 Y의 입력이 X가 아닌 H임에 유의
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')Model.summary(): 모델의 각 층과 출력 형태 등의 정보를 출력Param #: 가중치 및 바이어스의 개수
부록
범주형 데이터의 값이 숫자로 표현된 경우, get_dummies()를 통한 원핫 인코딩이 불가능함. (양적 데이터로 인식하기 때문)
데이터.dtypes: 각 컬럼들의 타입을 출력함.- 컬럼이
category및object타입인 경우에만get_dummies()를 통해 원핫 인코딩 가능. - 직접 변환:
데이터[컬럼명].astype('category')이용!
데이터에 N/A 값이 존재할 때에도 문제가 생길 수 있음.
데이터.isna().sum(): 컬럼별로 N/A 값이 있는지 체크함.- 직접 데이터 파일을 편집하여 N/A 값을 없애거나, 해당 컬럼의 평균값을 대신 넣어주는 식으로 해결 가능.
mean = 데이터[컬럼명].mean()
데이터[컬럼명] = 데이터[컬럼명].fillna(mean)Activation은 Dense Layer로부터 분리하여 작성 가능함.
H = tf.keras.layers.Dense(8, activation='swish')(X)
# 위, 아래 코드는 동일한 코드
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.Activation('swish')(H)이때 Dense와 Activation 사이에 BatchNormalization 삽입 가능.
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)=> loss가 훨씬 더 빨리, 많이 떨어짐! (자세한 원리는 이후에...)
나만의 정리
기계학습 중 지도학습은 '과거의 데이터를 분석해서 미래의 데이터를 예측하는 것'이라 했다.
입력과 출력, 원인과 결과, 독립변수와 종속변수로 구분되는 데이터를 이미 갖고 있다면, 이를 바탕으로 새로운 입력이 등장하더라도 그에 대한 결과를 예측하여 내놓는 기계를 만들 수 있다.
여러 개의 입력(xn)이 어떤 식으로 출력(y)을 만들어 내는지는 수식으로 표현할 수 있다:
그리고 학습이란 위 수식이 주어진 과거의 데이터(예시)와 최대한 가까운 결과를 내놓도록 적절한 와 를 찾아가는 과정이다.
초기 w와 b로부터, 주어진 입력값을 대입한 결과가 실제 예시와 얼마나 비슷한지 비교하고, 오차를 줄이기 위해 w와 b를 알맞은 방향으로 키우거나 줄이는 작업을 반복한다. 주어진 데이터가 많을수록, 학습을 많이 반복할수록 정확도는 높아지고 실제와 가까운 수식(모델)을 얻을 수 있게 된다.
기계학습의 정체를 알기 전까진 완전히 마법처럼 느껴지는 기술이었지만, 사실은 인간도 할 수 있는 계산 과정을 '매우 빠르고 효율적으로' 기계가 대신 해주는 것이라는 걸 알게 되었다.
다음 강의에서는 조금 더 깊은 부분에 대해 배울 것 같다.
