생활코딩 - Machine Learning 1 강의를 듣고 요약, 필기한 내용입니다.
모델
모델 = 판단력 = '추측을 위한 기준'
어떤 컴퓨터든 모델이 주어지면 그걸 통해서 추측을 하고 판단을 내릴 수 있다.
좋은 모델을 만들기 위해선 정확한 데이터, 많은 데이터를 통한 학습 과정 필요
복잡한 현실을 데이터화하여 학습을 위해 사용할 수 있어야 함.
- Teachable Machine - 아주 쉽게 나만의 모델을 만들어 볼 수 있는 사이트
표
표 = 행 + 열 = 데이터들의 모임 (데이터셋)
행 = 개체, 관측치
열 = 특성, 변수
변수
독립변수: 원인이 되는 열
종속변수: 결과가 되는 열
상관관계: 한쪽이 변할 때 다른 한쪽도 변하는, 즉 영향을 주고 받는 관계
인과관계: 상관관계 중 원인과 결과로 나누어지는 관계, 즉 독립변수와 종속변수의 관계
기계학습이란?
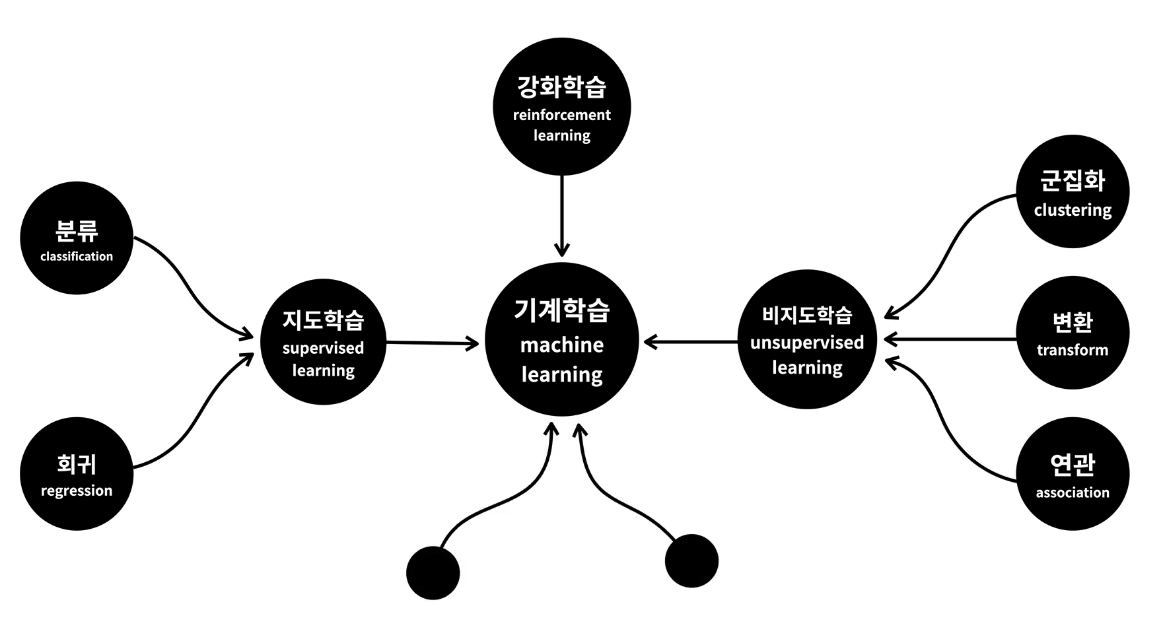
기계학습 = 지도학습 + 비지도학습 + 강화학습
- 지도학습 = 분류 + 회귀 / 문제와 정답이 정해져 있는 '문제집'을 통해 학습
- 비지도학습 = 군집화 + 변환 + 연관 / 데이터에 대한 통찰을 통해 새로운 의미나 관계를 스스로 파악하도록
- 강화학습 = '어떻게 해야 하는 것이 더 좋은지'를 스스로 느끼면서 시행착오를 통해 학습
=> '공식의 대중화', 모델을 누구나 더욱 쉽게 만들어 사용할 수 있게 함.
지도학습
과거의 데이터를 학습해서 미래의 데이터를 예측하기 위한 것. 인과관계로 이루어진 데이터를 독립변수와 종속변수로 나누고, 컴퓨터가 이를 학습하여 모델을 생성.
- 회귀(regression): 예측하고 싶은 종속변수의 값이 숫자, 즉 양적 데이터일 때 사용.
- ex. 기온을 독립변수로, 레모네이드 판매량을 종속변수로 두고 데이터를 기록한다
- 분류(classification): 종속변수의 값이 이름과 같은 범주형 데이터일 때 사용.
- ex. 메일 발신인, 제목, 본문 내용이 독립변수, 스팸 메일 여부가 종속변수일 때, 지금까지 받은 메일들을 모으고 스팸 메일과 일반 메일로 구분한다
비지도학습
미지의 세계를 탐험하는 것과 같음. 데이터들의 성격을 파악하는 것이 목적. 독립변수/종속변수 구분이 중요하지 않음. 데이터를 정리정돈.
- 군집화(clustering): 비슷한 행들을 모아 그룹으로 만든다. (↔ 분류: 어떤 대상이 어떤 그룹에 속하는지 판별)
- ex. 각각의 위도와 경도를 지닌 사용자들을 좌표 평면 상에 배치한 후 비슷한 곳에 있는 것끼리 묶기
- 만약 행이 1000만 개라면? 열이 100종류라면? 좌표평면 대신 머신러닝-비지도학습-군집화 사용 (기계가 알아서! 관측치(1000만) + 클러스터 수(100개) = 100개의 클러스터 생성)
- 연관(association): '연관 규칙 학습'. 추천 알고리즘에 사용됨. 서로 연관이 있는 특성, 열을 찾아주는 기법.
강화학습
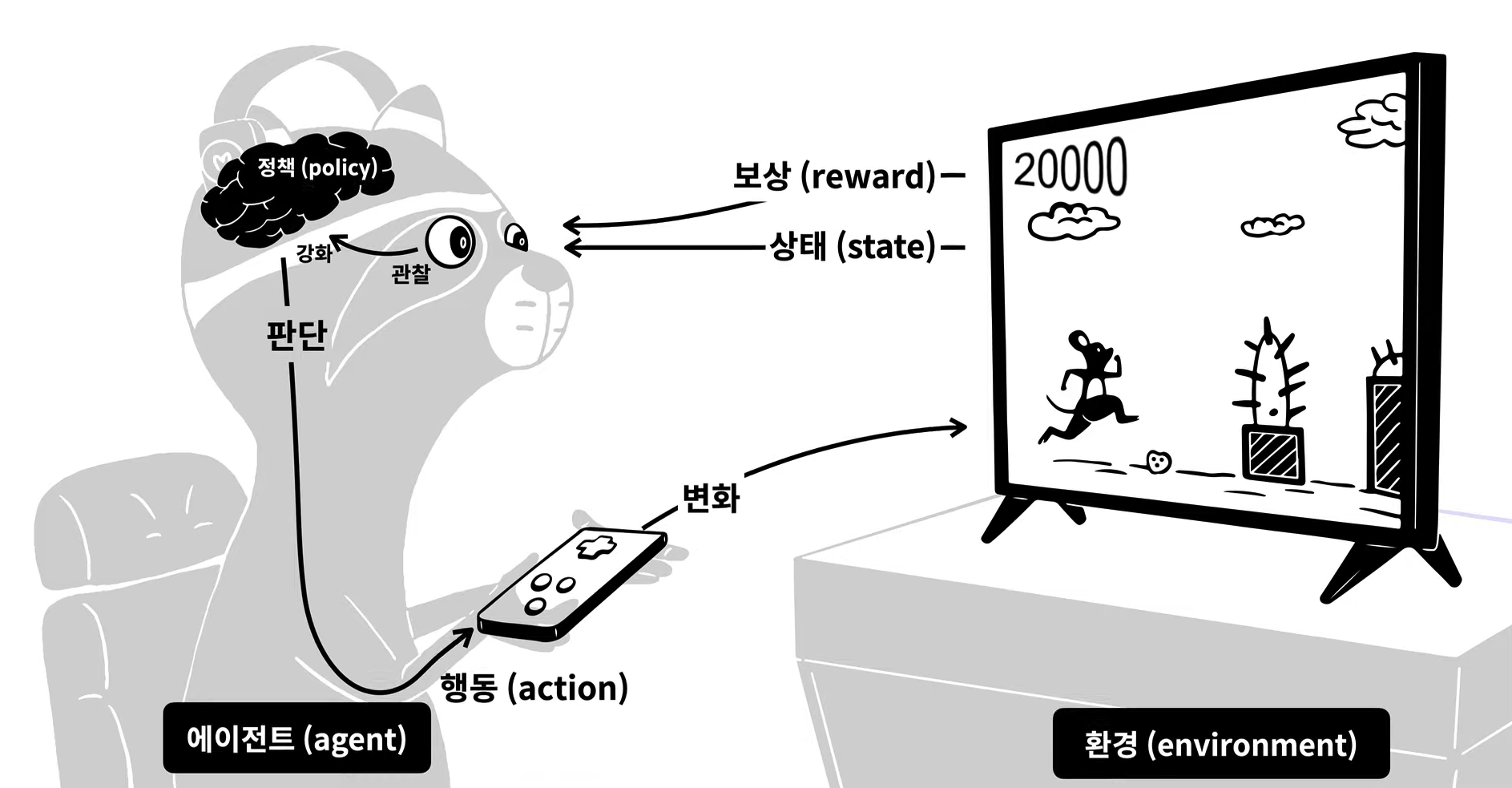
배움이 아닌 '경험', 일단 해보는 것을 통해 학습하는 것. 상과 벌을 이용.
ex. 게이머는 관찰하고, 판단하고, 행동하면서 게임을 진행하고, 이를 반복하면서 게임 결과에 따라 자신의 판단력을 적절한 방향으로 강화할 수 있음.
=> 상태에 따라서 더 많은 보상을 얻는 행동을 에이전트가 할 수 있도록 하는 정책을 만드는 것.
마무리
-
머신러닝 지도: 어떤 문제를 해결하기 위해 어떤 머신러닝 기법을 써야 할까?
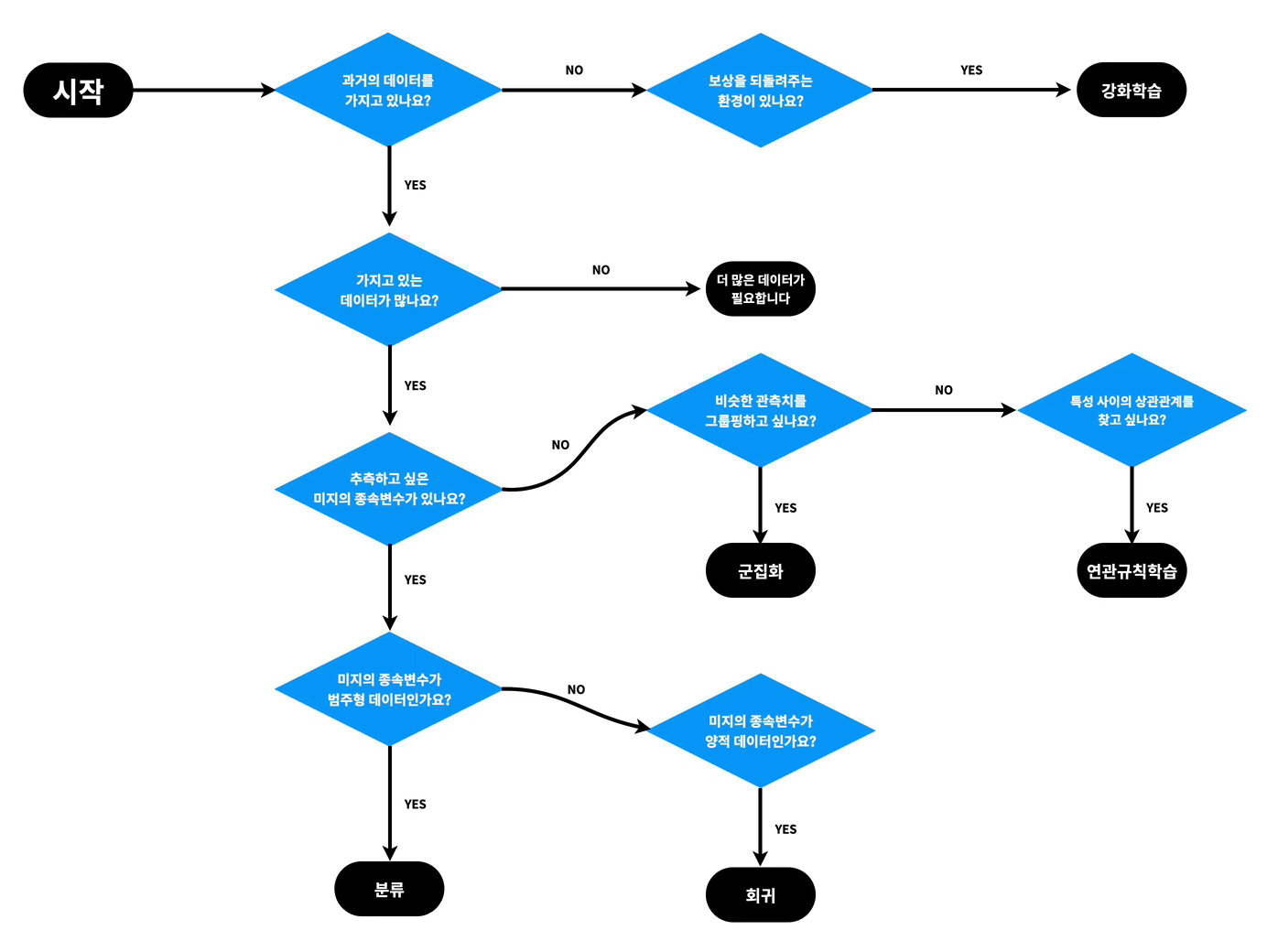
-
데이터의 종류
- 범주형
- 명목형 (성별, 혈액형 등)
- 순서형 (학점, 효과 등)
- 수치형
- 이산형 (개수, 횟수 등)
- 연속형 (키, 혈압 등)
- 범주형
