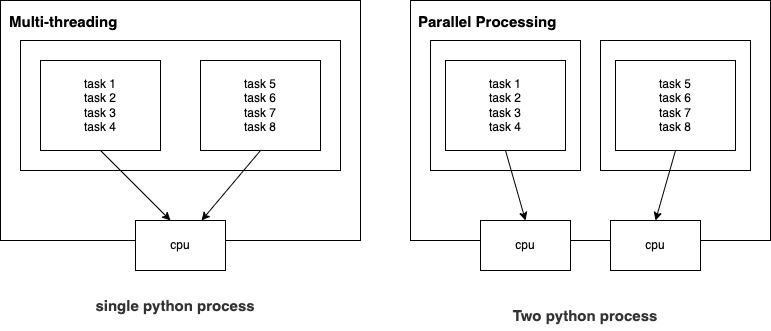
1. Multi-threading vs Parallel Processing
내용 | Multi-threading | Parallel Processing |
|---|---|---|
| 동일 메모리 공유 | O. 하나의 python 인스턴스(session)를 사용하기 때문에 모든 thread가 동일한 메모리를 공유(same RAM space) | X. python의 여러 인스턴스를 사용하기 때문에 각 작업을 위해 각 각의 RAM 메모리 공간을 이용 |
| 데이터 복사 필요 | X. 한개의 python 인스턴스에서 진행되기 때문에 해당 배열을 복사할 필요가 없음 | O. 여러 인스턴스를 사용할 경우 결과를 도출하기 위해서 해당 값들을 main session으로 한번 복사해야 해야함 |
| GIL 문제* | O. for loop 돌 때 한 i에 대한 loop를 돈 후 i+1에 대한 loop를 돌수 있음 | X. 각 process는 각자 GIL을 갖고 있음. i와 i+1에 대한 loop가 동시에 가능함 |
GIL이란
- Global Interpreter Lock
- 한번에 한 thread만이 python script를 읽을 수 있는 제한이 존재한다는 것
- 그러나 GIL을 해소시키는 function이 존재함 i.e.
pd.read_csv()- 이런 경우 multi-thread를 이용하는 것이 더 빠름
Thread | Process |
|---|---|
| - Dask Array - Dask DataFrame - Pipeline based dask.delayed() | Dask Bags |
-
dask function별 default로 parallel processing 혹은 multi-thread를 사용하도록 정해져있는데 이는 모든 상황에서 최선의 선택은 아님
-
그래서 해당 default를 수정하기 위해서는
.compute(scheduler = '')를 사용 -
Process와 thread를 동시에 사용하기 위해서는 Cluster 및 Client를 사용
(추후 Local Cluster에서 설명)
conc = x.compute(scheduler = 'threads') # or processes
conc = dask.compute(x, scheduler = 'threads') # or processes2. Lazy Evaluation
- Dask는 Lazy Evaluation을 사용
- 변수가 실제로 필요한 스크립트의 지점까지 변수가 계산되지 않음을 뜻함
- Lazy eval 코드로 변환하기 위해
from dask import delayed을 사용할 수 있음. 이 함수는 다른 함수를 인수로 취하고 지연 버전을 반환 - 추후
compute()를 이용해 실제 계산 진행
def add_function(x, y):
return x + y
# create delayed version of above function
delayed_add_function = delayed(add_function)
# Use the delayed function with input 4
delayed_result = delayed_add_function(4, 5)
# print the delayed answer
print(delayed_result)
# --> function이 실제로 계산된 결과가 아님
# --> 지연된 개체가 반환될 뿐
result = delayed_result.compute() # 계산된 값
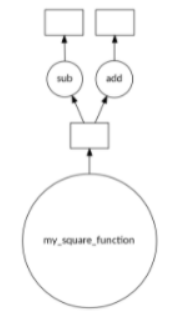
3. Task Graph
.visualize()를 이용하여 task work-flow를 그릴 수 있음
x = delayed_add_function(4, 5)
delayed_result1 = x - 5
delayed_result2 = x + 5
dask.visualize(delayed_result1) # delayed_result1.visualize()
dask.visualize(delayed_result2)
# 위의 코드는 dalyed_result1과 2의 중복되는 계산과정을 굳이 한번 더 해야하기 때문에 효율적이지 못함
dask.visualize(delayed_result1, delayed_result2)
# plot 보면 효율적이라는 걸 볼 수 있음
4. Chunked Dataset
- 대량의 데이터를 사용하는데 있어 pipeline을 생성하는데 좋음
- 데이터가 클수록 메모리에 한번에 load할 수가 없기 때문에, 더 빠른 속도를 위해 chunked dataset을 이용
# chunked data
path = '/Volumes/GoogleDrive/My Drive/Colab_Notebook/kaggle/ecom_behavior/data'
maximums = []
filenames = glob(os.path.join(path, '*.csv'))
for file in filenames:
# print(file)
df = delayed(pd.read_csv)(file)
max_length = df['price'].max()
maximums.append(max_length)
print(maximums) # delayed 값
dask.compute(maximums) # 계산된 값

:)