✏ Bagging
✅ 배깅 정의
- bootstrap aggregating
- 주어진 데이터로부터 랜덤하게 여러 개의 부트스트랩 데이터를 모델링한 후 결합하여 최종의 예측 모델을 생성하는
앙상블 기법중 하나
🌟 앙상블 기법 (Ensemble)
- 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
- 즉, 여러 개의 약 분류기를 결합하여 강 분류기를 만드는 것
- 앙상블 기법을 이용한 대표적인 모델은 랜덤포레스트와 그래디언트 부스팅이 있음
앙상블 종류
1. 배깅(bagging)
2. 부스팅(boosting)
3. 스태킹(staking)- 각 모델별 임의의 데이터 세트 생성 시 기존 데이터 세트에서
중복을 허용한 채로 무작위 N개를 선택하여 생성 - 데이터로부터
부트스트랩을 한 후, 부트스트랩한 데이터로 모델을 학습시킨다. 그리고 학습된 모델의 결과를 집계(평균 또는 투표방식 활용)하여 최종 결과 값을 구한다.
🌟 부트스트랩 (Bootstrap)
- 유한표본 또는 작은 표본에서 표본 추출과 통계치 계산의 과정을 반복함으로써
주어진 통계량의 유한표본분포를 구하는 방법
- 표본의 크기가 항상 크기를 기대할 수는 없다. 따라서 이때 표본평균을 정규분포에 근사시키는 방법으로 사용하는 것이 바로 부트스트랩
✔️ 중복을 허용하지 않고 샘플링하는 방식도 있는데, 이를 **페이스팅**이라고 한다.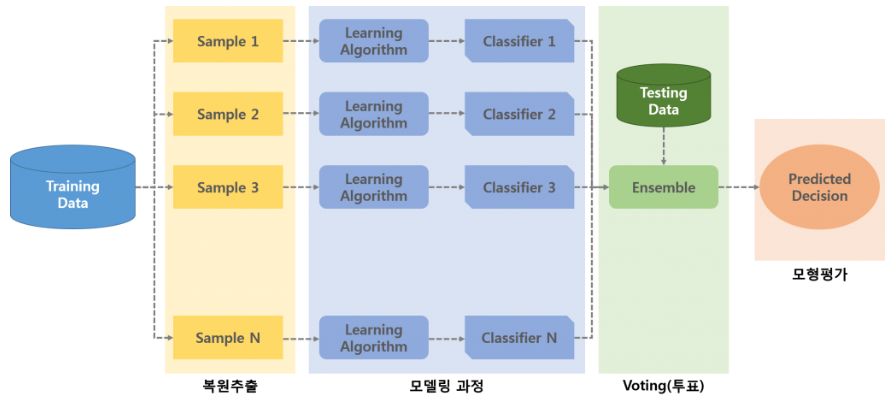
- 하늘색, 빨간색, 파란색으로 색칠된 도형들은 각 Bootstrap에 포함된 데이터를 의미하고, 각 그래프의 실선은 학습 모델의 분류 경계선을 나타낸다.
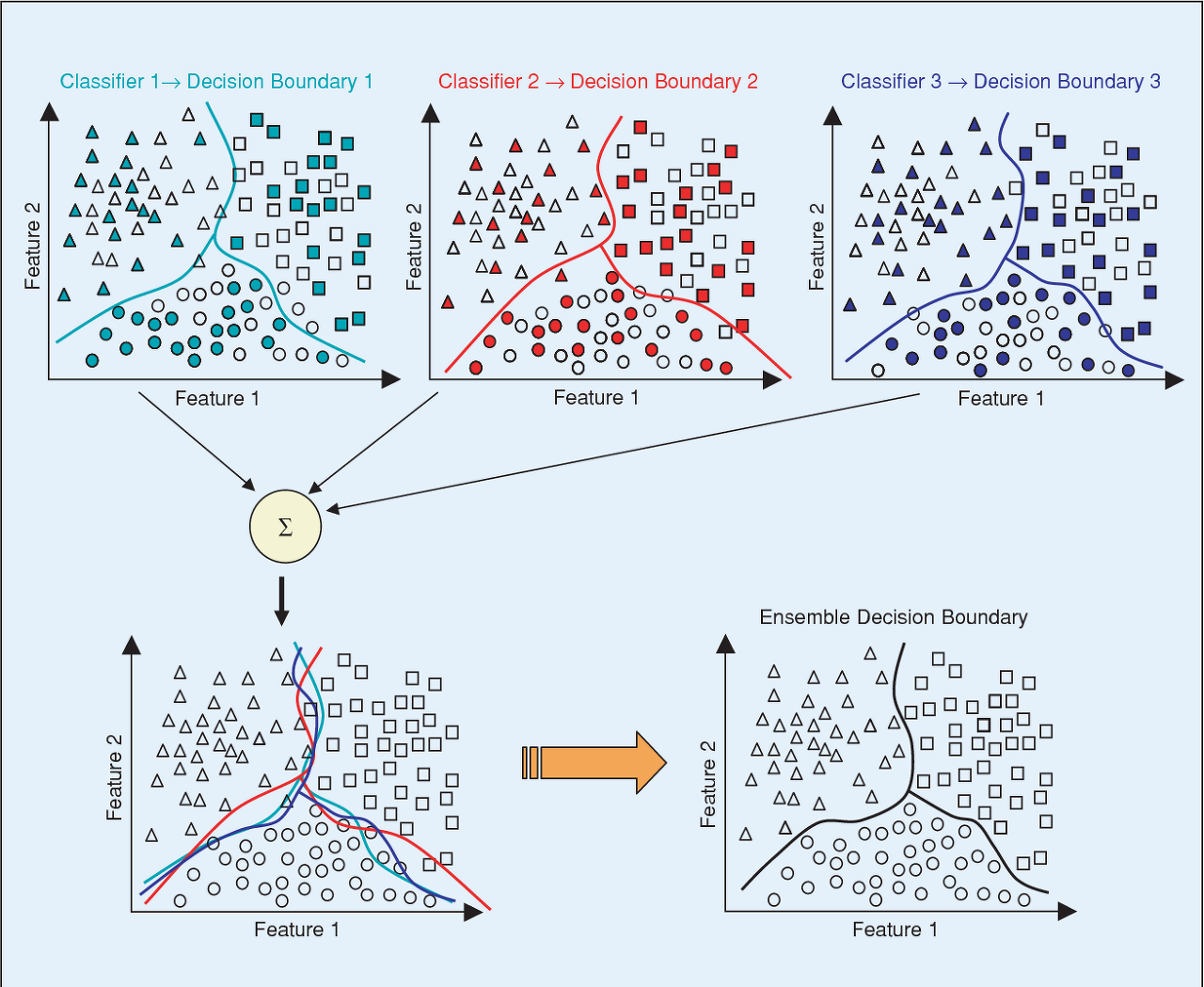
개별 모델들의 분류 경계선은 전체 데이터의 관점에서는 정확도가 떨어지지만, 이를 결합한 모델(왼쪽 하단의 그래프)은 전체 데이터의 분포에 대해서 좀 더 정확한 분류 경계선을 갖는 것을 확인 할 수 있다.
✅ 배깅의 목적
- 예측 모형의 변동성이 큰 경우, 해당
변동성을 감소시키기 위해 사용 - 원 자료로부터 여러 번의
복원 샘플링을 통해 예측 모형의 분산을 최소화하여예측력 향상
✅ 배깅의 절차
1) Rawdata에서 bootstrap 데이터 추출
2) 추출을 반복하여 n개의 데이터 생성
3) 데이터를 각각 모델링하여 모델 생성
4) 단일 모델을 결합하여 배깅 모델 생성
✅ 배깅의 특징
- 과적합된 모형, 편의가 작고 분산이 큰 모형에 적합
병렬학습함- 여러 개의 모델이
독립적 - 범주형 데이터는
투표 방식(Votinig)으로 결과를 집계하며, 연속형 데이터는평균으로 집계함
🔍 배깅의 대표적인 예시: Random Forest
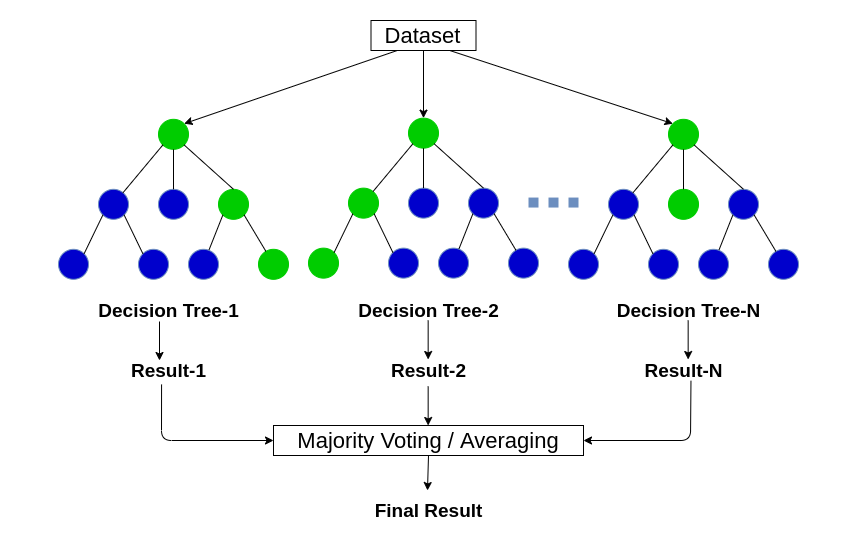
-
앙상블 기법(Ensemble) 의 일종으로 다수의 결정 트리들을 학습하여 검출, 분류, 그리고 회귀 등 다양한 문제에 활용하는 기법
-
배깅 모형의 문제는 동일한 데이터셋에서 복원추출로 만든 데이터 셋 B개가 서로 상관관계가 존재해서 B개의 트리 모형도 상관관계를 갖게 되고, 공분산이 존재하게 되어서 예측력이 떨어질 수 있다는 것이었다. 👉 이 공분산을 줄이기 위해 랜덤 포레스트는 트리를 그릴때 모든 변수를 다 사용하지 않는다.
-
랜덤포레스트의 주요 파라미터
n_estimators: 트리를 몇 개 만들 것인지 (int, default=100), 값이 클수록 오버피팅 방지
criterion: gini 또는 entropy 중 선택
max_depth: 트리의 깊이 (int, default=None)
bootstrap: True이면 전체 feature에서 복원추출해서 트리 생성 (default=True)
max_features: 선택할 feature의 개수, 보통 default값으로 씀 (default='auto')
✅ 배깅의 장점
- 편향은 그대로 유지하면서 분산은 감소시키기 때문에
성능을 향상시킴
🌟 랜덤포레스트와 의사결정 트리를 예시로 설명하면, 한 개의 결정트리의 경우 훈련 데이터에 있는 노이즈에 대해서 매우 민감하지만, 트리들이 서로 상관화 되어 있지 않다면 여러 트리들의 평균은 노이즈에 대해 강인하다.- 배깅에서 사용할 수 있는 기본 학습기의 종류에는 제한이 없음
🌟 분류문제에서 DT 이외에도 로지스틱회귀 모형을 사용해도 좋고, 회귀문제에서 선형 회귀모형이나 knn방법을 써도 좋다.- 별도의 검증데이터 없이 데이터를 Hyper Parameter 최적화나 성능검증에 활용 가능
- 어렵지 않은 구현
- 불안정한 모형일수록 빛을 발하는 성능
✅ 배깅의 단점
해석이 다소 어려움- 항상 성능 향상을 보장하는 것은 아님
🧚🏻♀️ 참고자료
- tistory
랜덤 포레스트 원리와 구현 사이킷런 예제로 코드 실습해보기
머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)
1. 앙상블(Ensemble) 기법과 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)
머신러닝 강좌 #15 랜덤 포레스트 (Random Forest)
- naver 블로그
