
🦁 TIL
👩🏻🔧 One-Hot Encoding
✅ 정의
- 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식
- 한 개의 요소는 True, 나머지 요소는 False로 만들어주는 기법
순서가 없는 데이터에 사용- 해당 관계는
**독립적**임을 표현 - 흩어져있을 뿐 모든 정보 유지
✅ 필요성
- scikit-learn에서 제공하는 머신러닝 알고리즘은 문자열 값을 입력 값으로 허락하지 않기 때문에 모든 문자열 값들을 숫자형으로 인코딩하는 전처리 작업 후에 머신러닝 모델에 학습
✅ 한계
- 해당 Feature에 너무 많은 고유값이 있는 경우 Feature가 지나치게 많아짐
- 필요한 저장공간도 늘어나게 됨
- 단어의
유사도를 표현하지 못함- [늑대, 호랑이, 강아지, 고양이]라는 4개의 단어에 대해 원-핫 인코딩을 했을 때
강아지와 늑대가 유사하고, 호랑이와 고양이가 유사하다는 것을 표현할 수 없음 - 여행 숙소 예약을 위해 ‘삿포로 숙소’라는 단어를 검색할 때
제대로 된 검색 시스템일 경우 [삿포로 게스트 하우스, 삿포로 호텔] 등과 같은
유사 단어의 결과도 보여줄 수 있어야 하지만, 유사성을 계산하지 못할 경우
연관 검색어를 보여줄 수 없음
- [늑대, 호랑이, 강아지, 고양이]라는 4개의 단어에 대해 원-핫 인코딩을 했을 때
✅ 방법
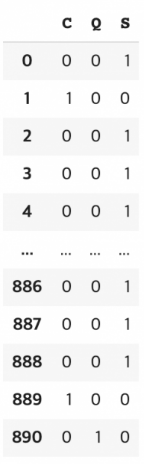
1️⃣ Pandas - get_dummies
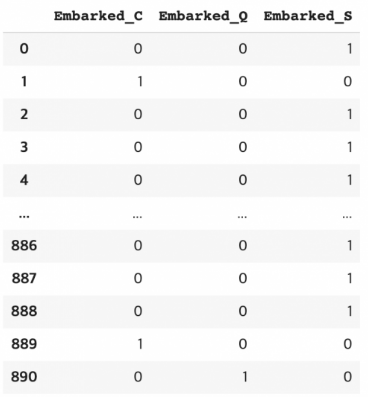
pd.get_dummies(data['Embarked'], prefix = 'Embarked')🌟 prefix를 활용하여 컬럼을 좀 더 명시적으로 표현 가능
prefix 적용 전
prefix 적용 후
2️⃣ sklearn - OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
X = [['male', 'from US', 'uses Safari'],
['female', 'from Europe', 'uses Firefox']]
enc.fit(X)
enc_out = enc.transform([['female', 'from US', 'uses Safari'],
['male', 'from Europe', 'uses Safari']]).toarray()
=>[[1. 0. 0. 1. 0. 1.]
[0. 1. 1. 0. 0. 1.]]
------------------------------------------------------------------------------------
enc.get_feature_names_out()
=> ['x0_female' 'x0_male' 'x1_from Europe' 'x1_from US' 'x2_uses Firefox'
'x2_uses Safari']
------------------------------------------------------------------------------------
pd.DataFrame(enc_out, columns=enc.get_feature_names_out())
↓
🔗 참고 자료
- scikit-learn 공식 문서
- wikidocs - 딥 러닝을 이용한 자연어 처리 입문
- 블로그

python