의존성 유형
Airflow의 의존성 패턴에 다음이 있다.
- 선형 체인 (linear chain) 유형
- 팬아웃/팬인 (fan-out/fan-in) 유형
하나의 Task가 여러 Downstream Task에 연결되거나 그 반대인 유형
선형 의존성 유형
이전 Task 결과가 다음 Task 입력으로 사용되는 관계
예시
download_launches >> get_pictures >> notifyUpstream 의존성이 성공적으로 실행된 후에 지정된 다음 Task 실행을 시작할 수 있다.
팬인/팬아웃 의존성
아래 DAG는 우산 판매 DAG이다.
서로 다른 Source에서 매일 날씨 데이터와 판매 데이터를 가져와서 데이터셋을 결합하고 모델을 학습시키는 DAG이다.

의존성 측면에서 각 데이터셋은 병렬로 실행되는 선형 의존성을 가진다.
fetch_weather >> clean_weather
fetch_sales >> clean_sales팬아웃(fan-out)
start Task는 DAG의 시작을 나타내는 dummy Task를 추가한 것이다.
이 Task가 반드시 필요한 것은 아니지만, 팬아웃을 설명하기 위해 적합하다.
팬아웃(fan-out) 종속성은 한 Task를 여러 Downstream Task에 연결한다.
팬아웃(일대다, 1대*) 의존성 추가하기
from airflow.operators.dummy import DummyOperator
start = DummyOperator(
task_id="start"
)
start >> [fetch_weather, fetch_sales]팬인(fan-in)
join_datasets Task는 clean_sales과 clean_sales Task 모두에 의존성을 가지고, 이러한 Upstream Task가 모두 성공적으로 완료된 후에 활성화 된다.
하나의 Task가 여러 Upstream Task에 영향을 받는 구조를 팬인 구조(fan-in structure)라고 한다.
[clean_weather, clean_sales] >> join_datasets나머지 Task 의존성은 다음과 같이 추가한다.
join_datasets >> train_model >> deploy_model브랜치하기
만약 ERP 시스템 전환으로 판매 데이터가 다른 Source에서 제공될 예정이라면 어떻게 해야될까?
이런 변경이 있어도 모델 학습이 중단되어서는 안된다.
또 향후 분석에서 과거 판매 데이터도 계속 사용할 수 있도록 이전 시스템과 새로운 시스템 모두 정상 동작해야한다.
이런 경우 다음과 같은 방법을 취할 수 있다.
- Task 내에서 브랜치하기
- DAG 내부에서 브랜치하기 (추천!)
Task 내에서 브랜치하기
다음과 같이 판매 데이터 수집 및 처리를 위한 두 개의 개별 코드로 분리할 수 있다.
# 수집 로직 분리
def _fetch_sales(**context):
if context["execution_date"] < ERP_CHANGE_DATE:
_fetch_sales_old(**context)
else:
_fetch_sales_new(**context)
...
# 새 형식에 맞춰 정제 로직도 분리
def _clean_sales(**context):
if context["execution_date"] < ERP_CHANGE_DATE:
_clean_sales_old(**context)
else:
_clean_sales_new(**context)
...
clean_sales_data = PythonOperator(
task_id="clean_sales",
python_callable=_clean_sales
)이 접근 방식의 장점
DAG 자체 구조를 수정하지 않고도 DAG에서 약간의 유연성을 허용할 수 있다는 것. 그러나 코드로 분기가 가능한 유사한 Task로 구성된 경우에만 작동한다. 새로운 데이터 Source가 완전히 다른 Task Chain이 필요한 경우 데이터 수집을 두 개의 개별 Task 세트로 분할하는 것이 나을 수 있다.
단점
DAG 실행 중 어떤 코드 분기를 사용하고 있는지 확인이 어렵다.
특정 DAG 실행에 사용된 ERP 시스템을 유추하려면 Task에 좀 더 세세한 logging을 포함해야 한다.
DAG 내부에서 브랜치하기(추천!)
ERP 시스템을 선택하는 Task를 두는 방법으로 DAG 구조를 변경
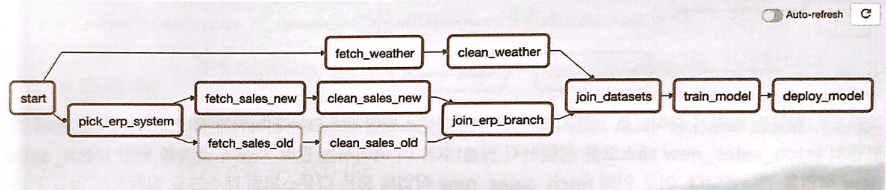
이 DAG 구조에서 들여다봐야 할 부분은 pick_erp_system Task와 join_erp_branch Task이다.
BranchPythonOperator
BranchPythonOperator를 사용하면 Downstream Task 세트 중 선택할 수 있는 기능을 제공한다. 이 Operator에 전달된 callable 인수는 작업 결과로 Downstream Task ID를 반환한다.
from airflow.operators.dummy import DummyOperator
def _pick_erp_system(**context):
if context["execution_date"] < ERP_CHANGE_DATE:
return "fetch_sales_old" # Task 반환
else:
return "fetch_sales_new" # Task 반환
pick_erp_system=BranchPythonOperator( # task 분기를 제공한다.
task_id="pick_erp_system",
python_callable=_pick_erp_system
)
start_task > pick_erp_system
pick_erp_system >> [fetch_sales_old, fetch_sales_new]
fetch_sales_old >> clean_sales_old
fetch_sales_new >> clean_sales_new트리거 규칙
브랜치 구조를 좀 더 명확히 하기 위해 join_erp_branch Task를 추가해준다.
join_branch = DummyOperator(
task_id="join_erp_branch",
trigger_rule="none_failed", # 상위 Task 실행 완료되자마자 실행
)
[clean_sales_old, clean_sales_new] >> join_branch
join_branch >> join_datasets트리거 규칙
이 때 트리거 규칙을 변경해주어야 한다. 그렇지 않으면 join_erp_branch Task 실행 시 모든 Downstream 작업을 건너뛴다.
Upstream Task가 모두 성공적으로 완료되어야 join_erp_branch가 실행되는데, 분기되는 경우가 만들어졌기 때문이다.
이 경우 트리거 규칙에 의해 Task 실행 시기를 제어해야 한다.
trigger_rule 인수를 이용하면 트리거 규칙을 정의한다.
값을 none_failed로 설정한다. 이를 통해 모든 상위 항목이 실행 완료 및 실패가 없을 시 즉시 작업을 실행한다.
다시말해, 모든 상위 Task가 실패없이 실행을 완료하자마자 join_erp_branch Task를 실행하여 브랜치 후에도 다음 Task 실행을 계속 할 수 있다.
| 값 | 설명 |
|---|---|
all_success | 모든 상위 Task가 성공해야 해당 Task 실행 |
none_failed | 이 옵션을 통해 Upstream Task 중 하나를 건너뛰더라도 계속 트리거가 진행되도록 할 수 있다 |
