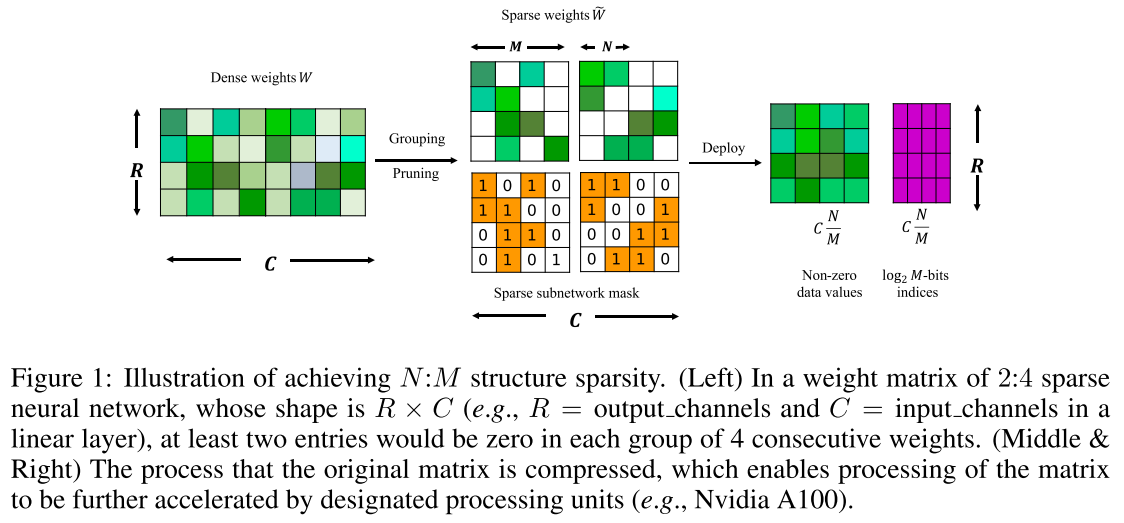
Overview
💡 N:M sparse는 NVIDIA Ampere Architecture에서 지원하는 기능을 활용하여 unstructured pruning을 가속화할 수 있는 방법
1. The first systematic study into training N:M structured sparse neural networks from scratch without performance drop
2. We propose a sparse refined term(SR-STE) to enhance the effectiveness on training the sparse neural networks from scratch instead of STE
Problem to solve
- ASP(APEX’s Automatic Sparsity - Nvidia) is computationally expensive since it require training the full dense models from scratch and fine-tuning again.
- Perturbations are introduced during the back-propagation using STE.
Concepts
N:M sparsity
- NVIDIA Ampere Architecture에서 지원하는 기능으로 연산 시 in_channel 차원을 전부 한번에 연산하는 것이 아니라 M 단위로 끊어서 연산을 하고 이 때 M 단위로서 N개만을 남겨두는 방식으로 pruning 한다면 unstructured pruning임에도 불구하고 acceleration이 가
- forward는 weight의 magnitude에 따라 pruning하여 흘려줌
- backward는 그냥 STE를 활용하면 성능저하 발생하여 새로 제안
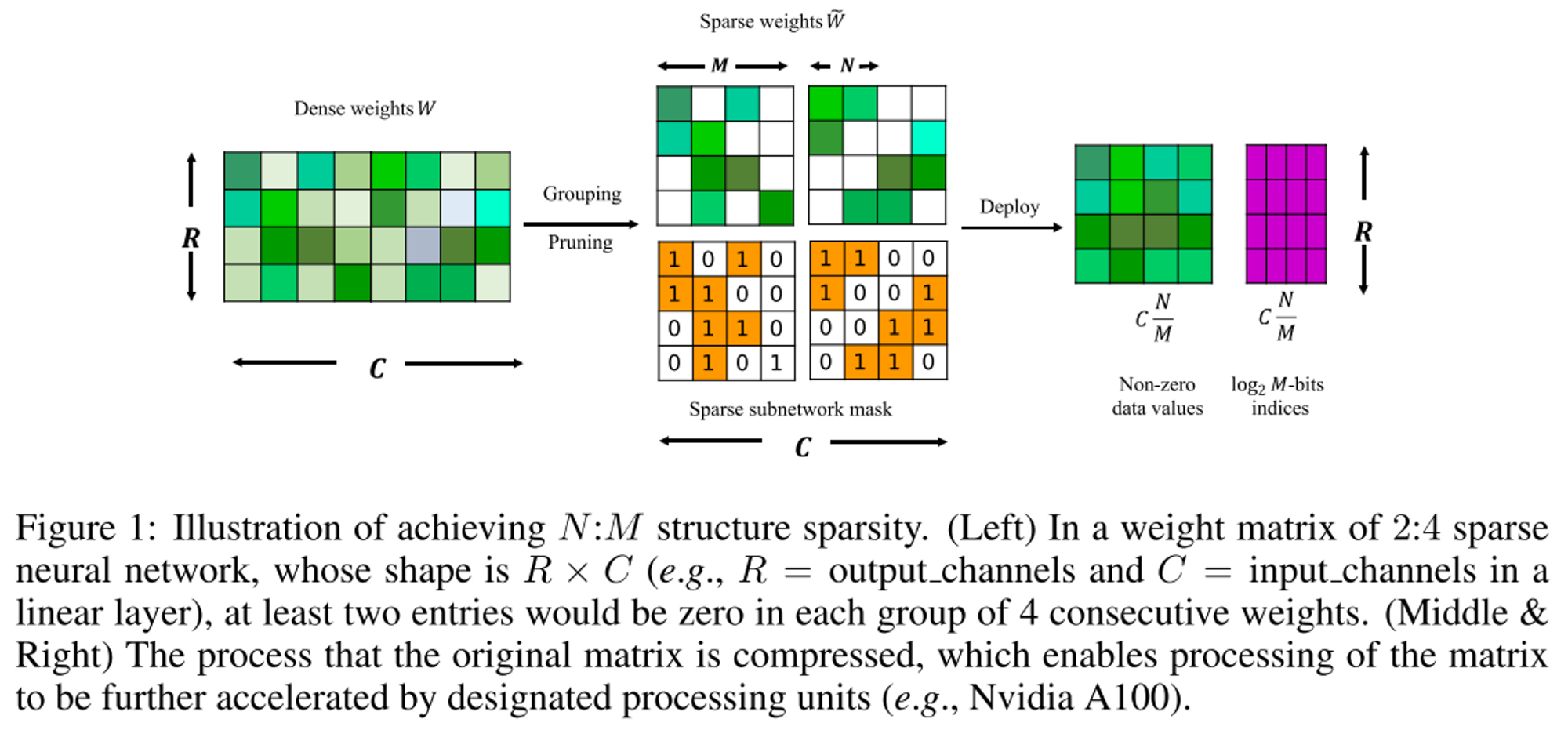
SAD (Sparse Achitecture Divergence)
- , : binary mask
- pruning 과정에서 mask가 바뀌는 정도를 측정하는 metric
- SAD (Sparse Architecture Divergence) metric를 제안하여 기존 STE를 사용했을 때 성능이 저하되는 현상 분석 → SAD가 클수록 모델의 변화가 크다는 것을 의미하며, SAD가 크면 성능저하가 큰 현상을 발견
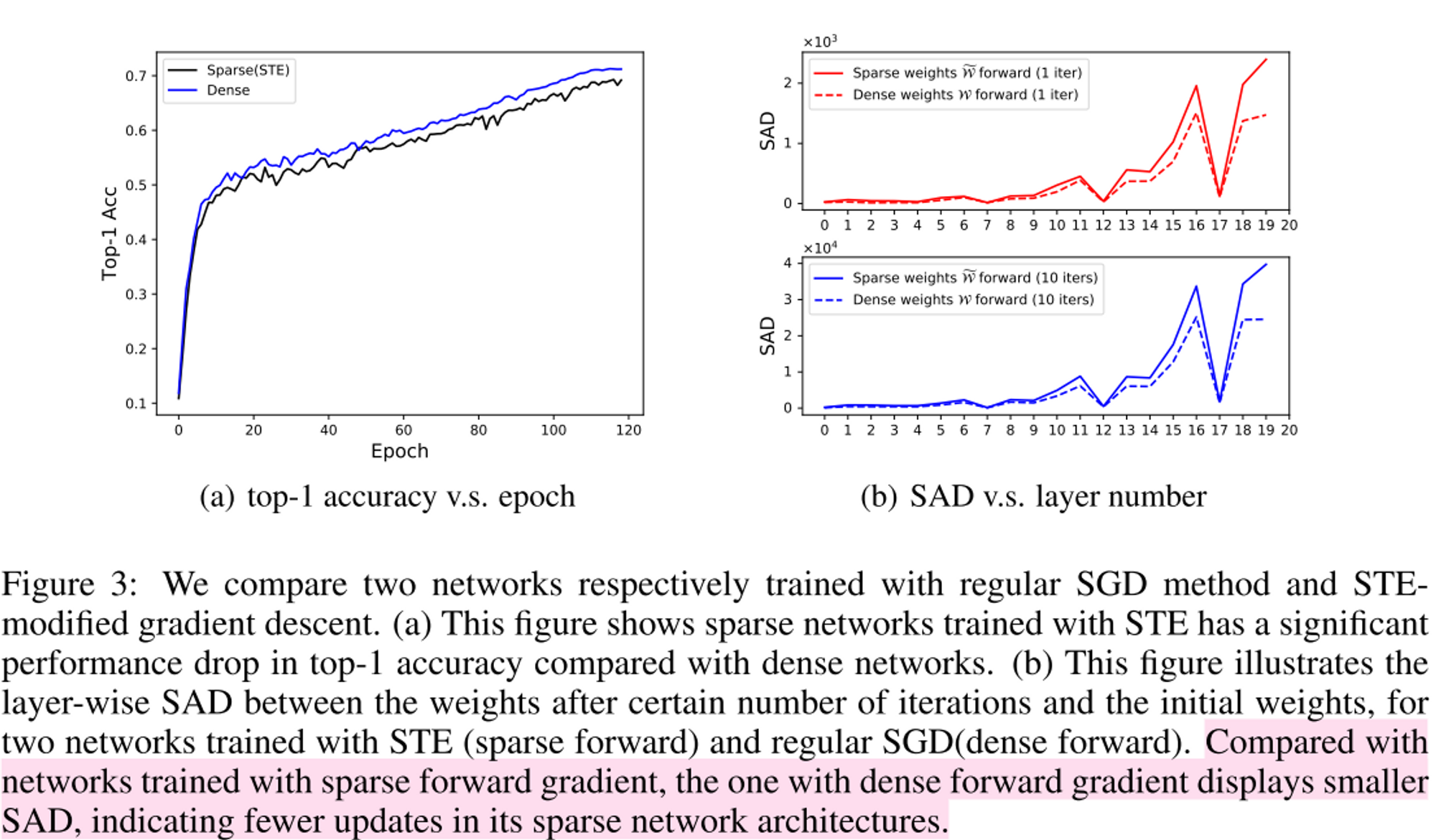
SR-STE

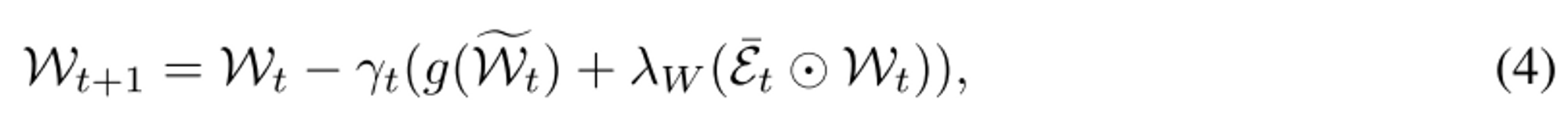
- : binary mask (pruned weight = 1, non-pruned weight=0)
- 결론적으로 기존 STE backpropagation에 pruned weight에 regularization 추가함
- STE를 통해 backpropagation approximation을 하면 non-pruned weight는 gradient가 원래와 같지만 pruned weight는 gradient가 원래와 크게 다르다.
- 따라서 pruned weight에 대한 regularization을 추가한 것이 SR-STE
- pruned weight에는 크기가 줄도록 regualrization을 추가하여 자연스럽게 현재 pruned weight는 나중에도 pruned weight로 유지시켜 pruning하면서 network의 architecture가 변하지 않도록 한다. pruning 하면서 network의 architecture가 변하지 않으면 training stability가 높아져 도움이 된다.

- Intuitively, we encourage the pruned weights at the current iteration to be pruned also in the followin iteratinos so that the sparse architecture is stabilized for enhancing the training efficientcy and effectiveness.
Results
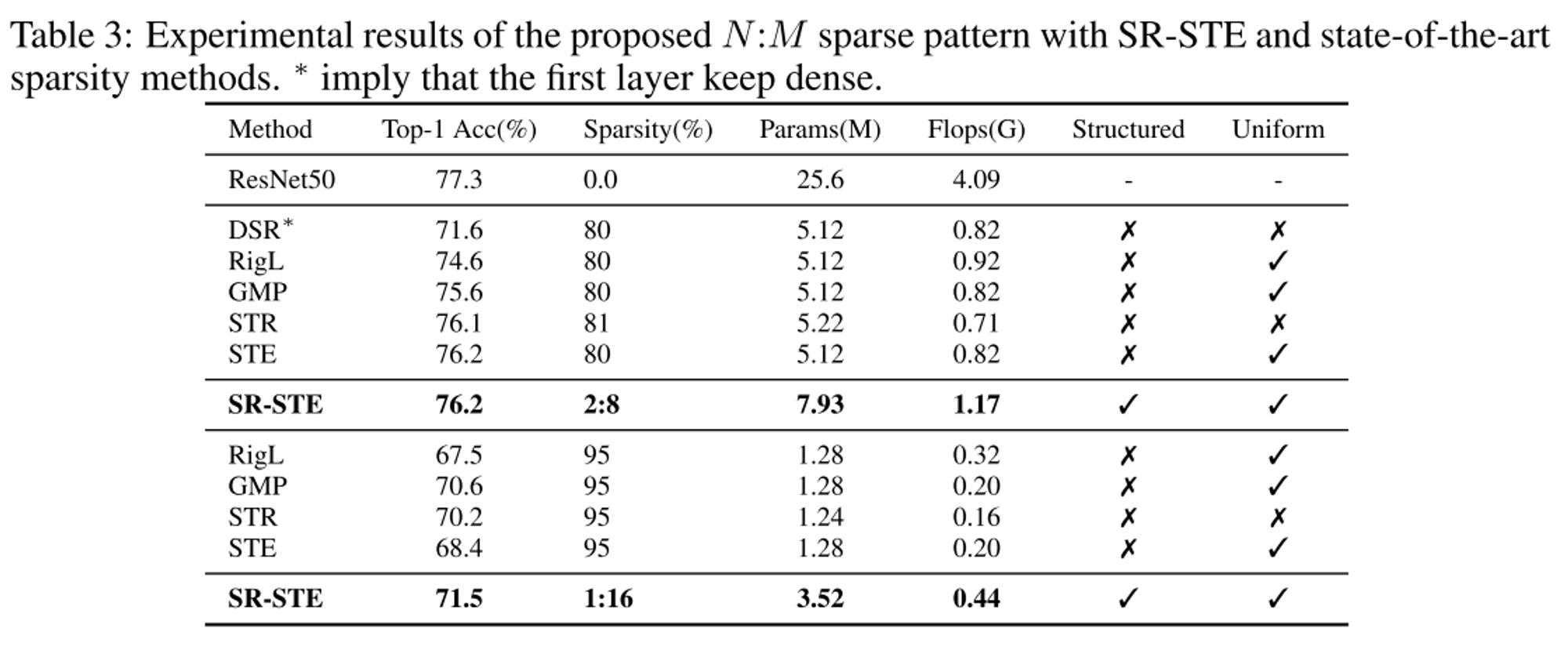
Classification

Object detection

Optical Flow and Machine Translation
- Machine Translation은 Transformer 기반 모델로 linear layer에 method를 적용
