부스트캠프 ai tech 3주차에 배운 내용을 정리하는 글입니다.
1. Semantic Segmentation
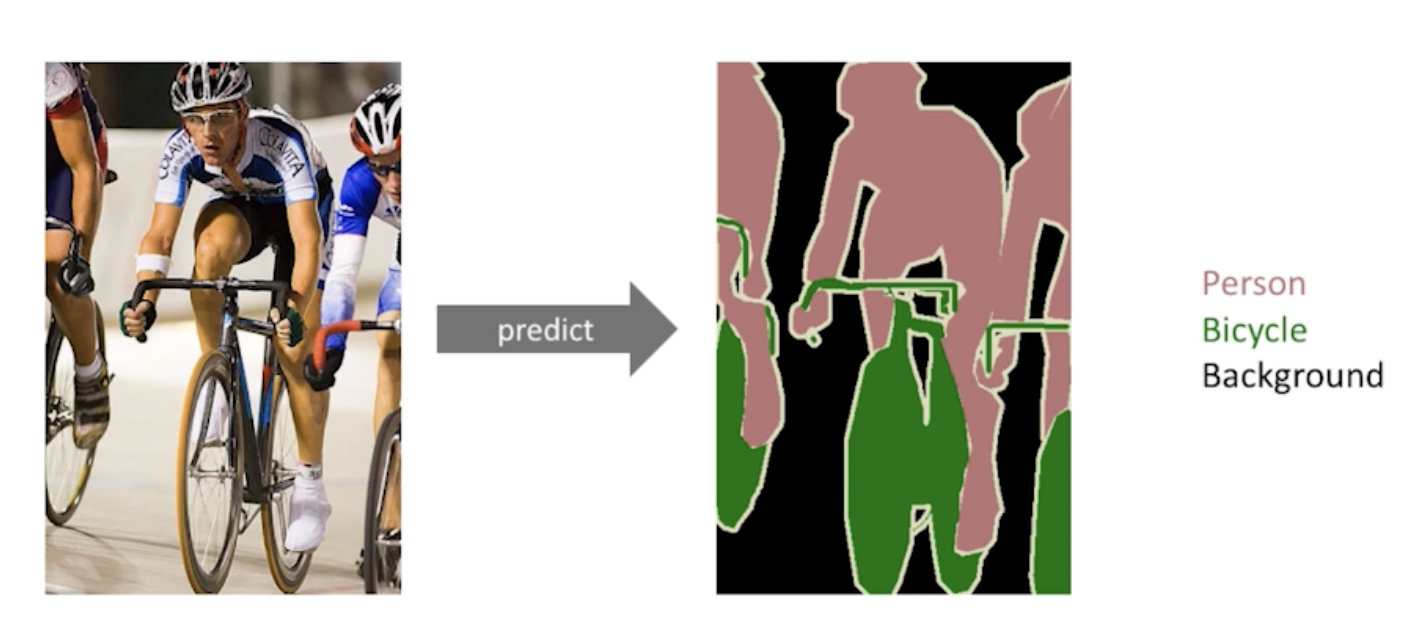
이미지의 각 픽셀이 어떤 라벨에 속하는지를 알아내는 문제(각 픽셀마다 분류)
그럼 semantic segmentation을 어떻게 할까?
convolutionalization: (dense layer를 없애는 과정, 위 사진에서 아래 사진처럼)
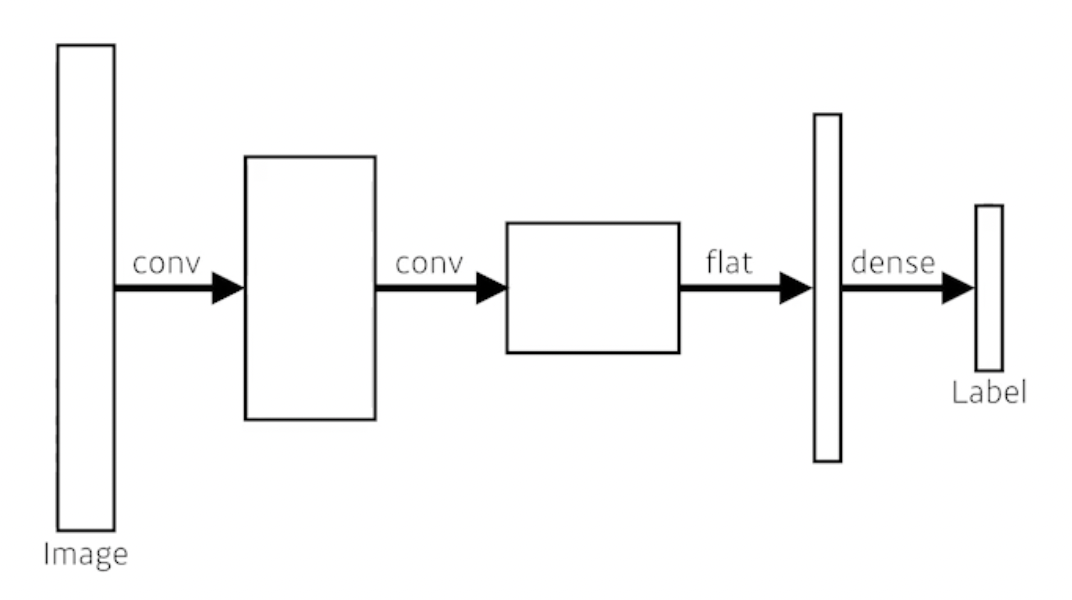 ordinary CNN
ordinary CNN
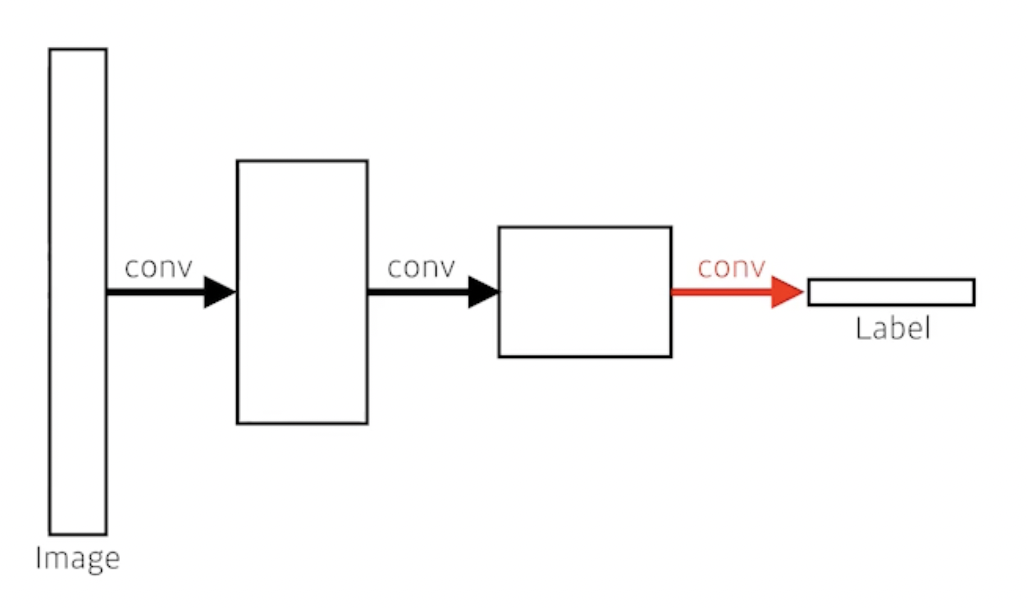 fully convolutional network(FCN)
fully convolutional network(FCN)
두 과정 모두 파라미터 수는 같음 → 당연한 것임. 왼쪽은 flat하게 resize 한 뒤 dense layer를 거치는 것 / 오른쪽은 왼쪽의 과정을 수행하기 위해 convolution layer를 사용한 것임(동일한 역할을 수행하고 있는 것임)

왼쪽 # of parameters: 4 x 4 x 16 x 10 = 2560(flat은 layer를 그냥 펴준 것뿐이고 dense layer가 fully connected layer이므로)
오른쪽 # of parameters: 4 x 4 x 16 x 10 = 2560(4 by 4 by 16 convolution kernel이 10개 있는 것임)
다 똑같아 보이는데 왜 convolutionalization을 하는 것일까? (특히 semantic segmentation 관점에서)
input의 spatial dimension에 상관없이 convolution filter로 찍으면 되니까 input size가 어떻게 되든 동작시킬 수 있음(대신 input의 spatial dimension이 커지면 output의 spatial dimension도 커지겠지) → 그리고 동작시킨 결과는 heatmap처럼 나옴
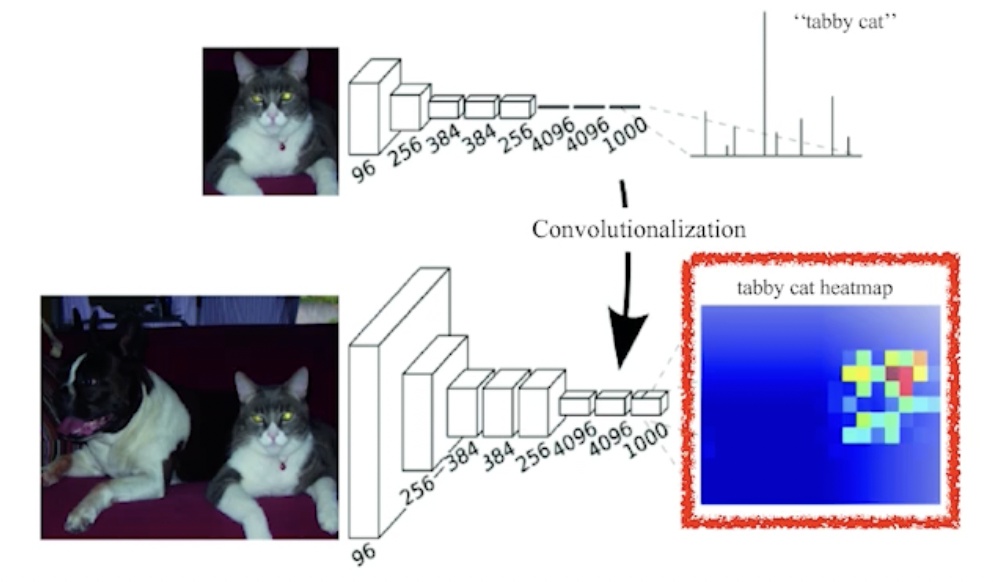
하지만 1 by 1 filter만 사용하는 것이 아니라면 output dimension은 감소함(coarse output) → 원래 dense pixel로 늘려야 함
Deconvolution(conv transpose)
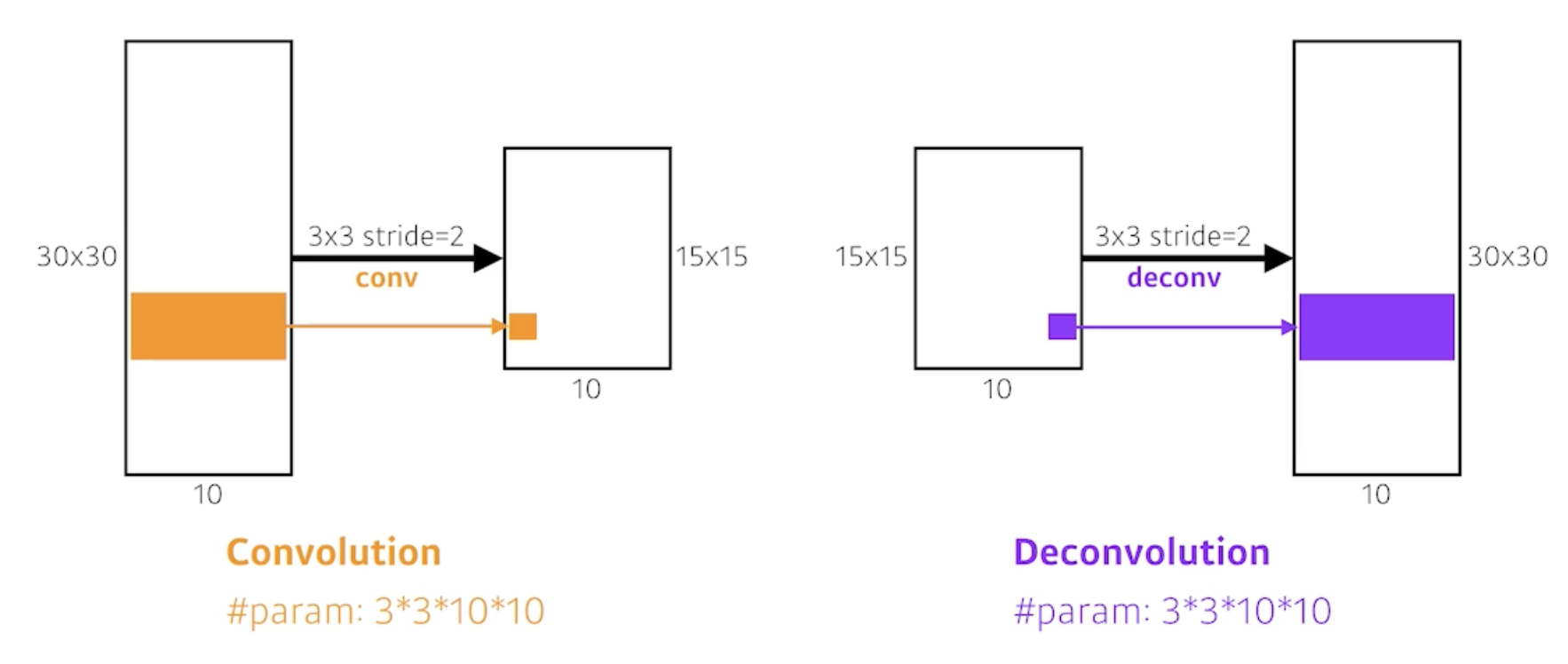
이 방법은 convolution의 역은 아님(convolution을 역으로 계산한다는 것 자체가 엄밀히 말하면 불가능)
예) 2와 8을 더했을 때 답은 10이지만 10을 쪼갰을 때 답이 꼭 2 + 8은 아님
하지만 파라미터의 수나 네트워크의 크기를 계산할 때는 convolution의 역이라고 생각하면 편함
실제 deconvolution은 아래 그림과 같음
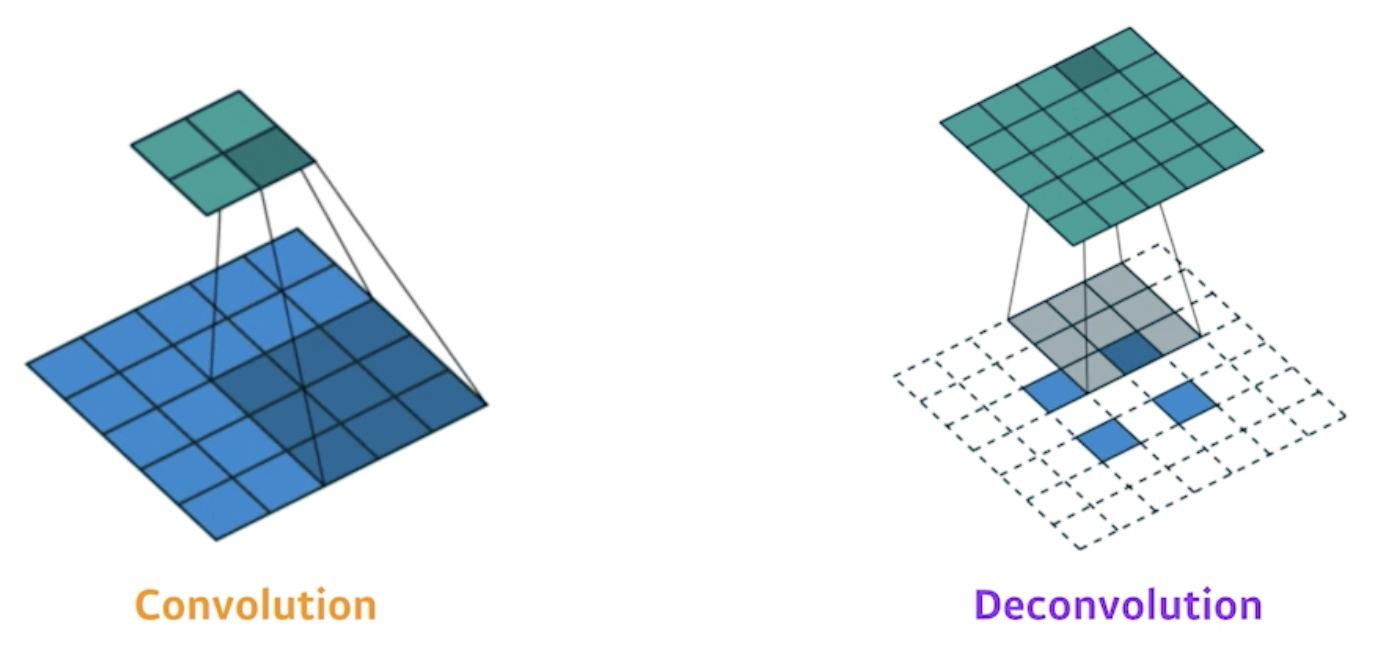
convolution(5 by 5 → 2 by 2): 5 by 5 input → 3 by 3 conv(stride 2) → 2 by 2 output
deconvolution(2 by 2 → 5 by 5): 위에서 나온 2 by 2 ouput에 padding 처리한 7 by 7 input → 3 by 3 conv(stride 1) → 5 by 5 output
2. Detection
이미지에 나타나는 객체들의 bounding box를 찾는 문제
R-CNN(Region Based CNN)
이미지 안에서 객체가 있을만한 2000개의 후보 region을 뽑음(2000 region proposals using Selective search) → 크기가 다른 region들의 크기를 같게 맞추고(CNN에 넣어주기 위해) AlexNet에 넣어줌(features 뽑기) → 분류(linear SVM)
단점: AlexNet을 2000번이나 돌려야 함
SPPNet
R-CNN의 단점을 극복하기 위해 이미지 전체를 CNN에 넣고 feature map을 만든 뒤 region에 해당하는 sub tensor 부분만 뜯어와서 사용함(CNN을 한 번만 돌리면 됨)
Fast R-CNN
마지막 부분의 neural network를 통해 bounding box를 어떻게 옮기면 좋을지(위치 교정, regression), 이 bounding box의 label이 무엇인지(classification) 계산
Faster R-CNN
bounding box의 후보를 임의로 뽑지 말고 뽑는 것도 학습시켜서 뽑자(region proposal network)
- anchor box: region proposal을 위한 다양한 크기의 bounding box(여러 크기의 anchor box를 만들어 놓으면 다양한 크기의 객체를 포착할 수 있겠지)
- Region Proposal Network: 특정 anchor box가 의미 있는 proposal일까?(anchor box에 있는 것이 뭔지는 뒷단의 network가 찾아주는 것이고 여기서는 anchor box에 객체가 있을 것 같은지 없을 것 같은지를 proposal 해주는 것임) → 최적의 region proposals만을 Faster R-CNN에 전달 → classification
- RPN에서도 FCN이 쓰임
- RPN에서도 FCN이 쓰임
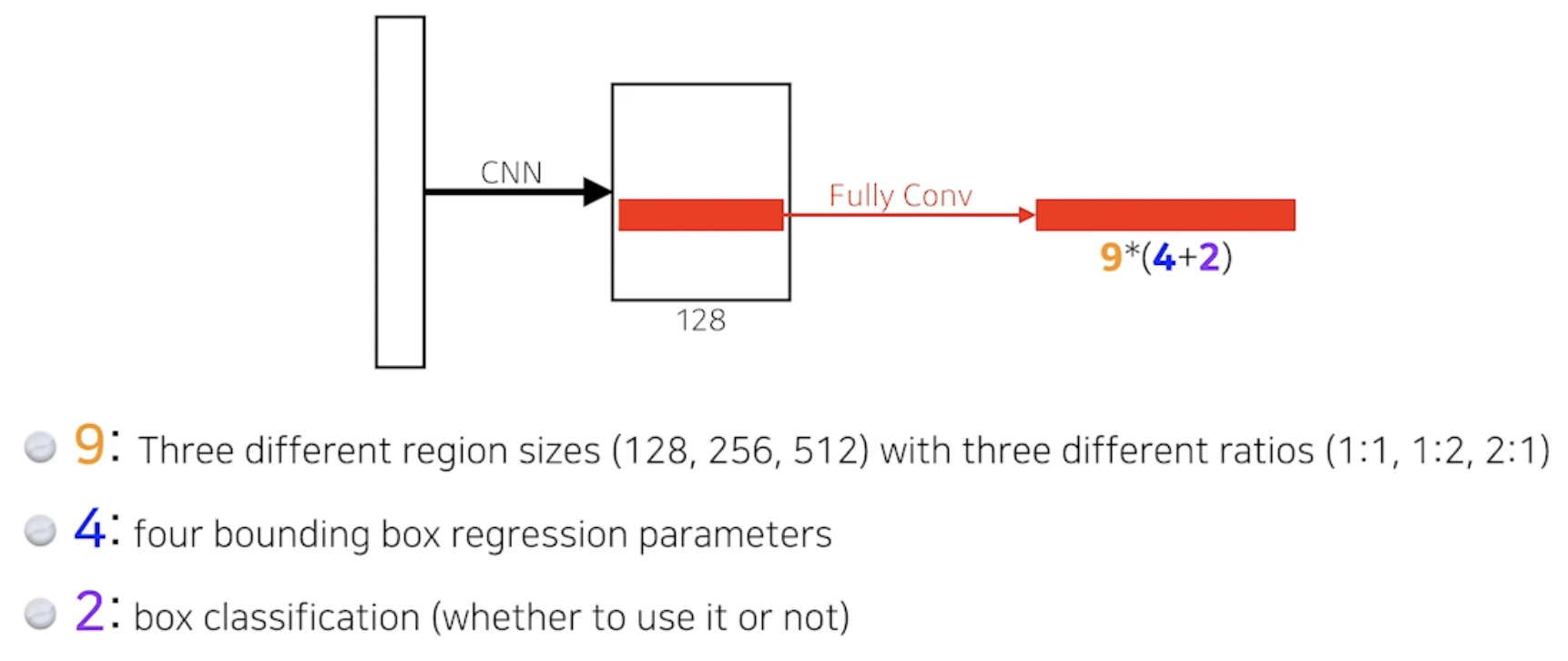
9: size 3개, width와 height의 비율 3개 → 조합하면 9개
4: width의 증가 또는 감소, height의 증가 또는 감소 → 4개
2: box가 쓸모 있다, 없다 → 2개
→ FCN을 통해 나온 54개의 값을 통해 어떤 영역에서 어떤 bounding box를 쓸지 말지를 정하게 됨
YOLO(You Only Look Once)
bounding box와 class probability를 동시에 예측함
bounding box를 찾아야 하는 region proposal network가 없음(Faster R-CNN과 비교해서) → 그래서 빠름
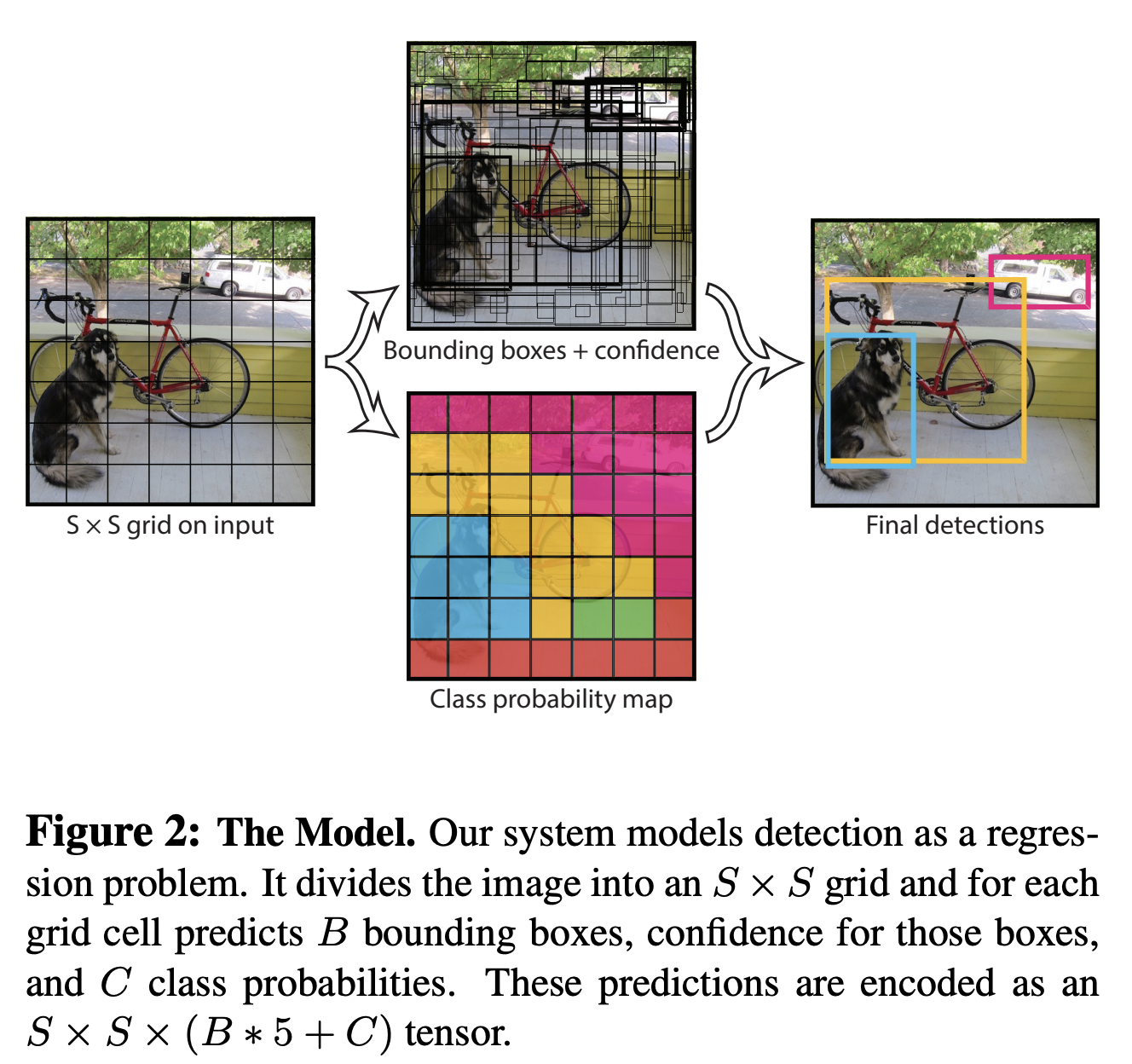
위 그림의 작동 방식
-
input 이미지를 S * S의 그리드 셀로 나눔
-
만약 물체의 중심이 어떤 그리드 셀 안에 들어가면 그 그리드 셀은 객체를 감지(해당 객체의 bounding box와 해당 객체가 무엇인지 감지)하는 역할을 담당함(위 사진에서는 B=5개의 bounding boxes)
-
B에 곱해진 5: offsets(x, y, w, h) and confidence
- x, y: 그리드 셀 내 bounding box 중심의 상대 위치
- w, h: 이미지 전체에 대한 bounding box의 상대 너비와 상대 높이
- confidence score:
- : 그리드 셀에 객체가 있는지를 나타내는 확률
- (intersection over union): 실제 bounding box와 예측 bounding box의 교집합 / 실제 bounding box와 예측 bounding box의 합집합
-
만약 B=2이면 하나의 그리드 셀에서 2개의 bounding box를 예측하겠다는 뜻
-
C: 라벨링 된 클래스의 수(위 실험에서 사용한 데이터 셋의 C=20) → 20개의 class probability(그리드 셀 안에 객체가 있다는 조건 하에 그 객체가 어떤 클래스인지에 대한 조건부 확률)가 나오겠지
-
-
두 정보(해당 객체의 bounding box와 해당 객체가 무엇인지)를 합치면 결과가 나옴
