부스트캠프 ai tech 3주차에 배운 내용을 정리하는 글입니다. (핸즈온 머신러닝 2판 참고)
아래 용어의 컨셉을 잘 이해하자
Important Concepts in Optimization
- Generalization(일반화 성능): training error와 test error의 차이/
- 일반화 성능이 좋다는 것은 test data에 대한 성능이 train data에 대한 성능과 비슷하게 나올 것 같다는 뜻임
- 일반화 성능이 좋고 train data에 대한 성능이 나쁘면 test data에 대한 성능도 train data에 대한 성능과 비슷하게 나쁘겠지
- Underfitting vs. Overfitting
- train data에 대한 성능이 안 좋음 → Underfitting
- train data에 대한 성능은 좋은데 test data에 대한 성능은 안 좋음 → Overfitting
- Cross-validation
- train data(모델 학습, 훈련을 위한 데이터)와 validation data(모델 검증을 위한 데이터)를 나누어 학습 알고리즘을 평가하고 비교하는 통계적 방법
- Bias and Variance
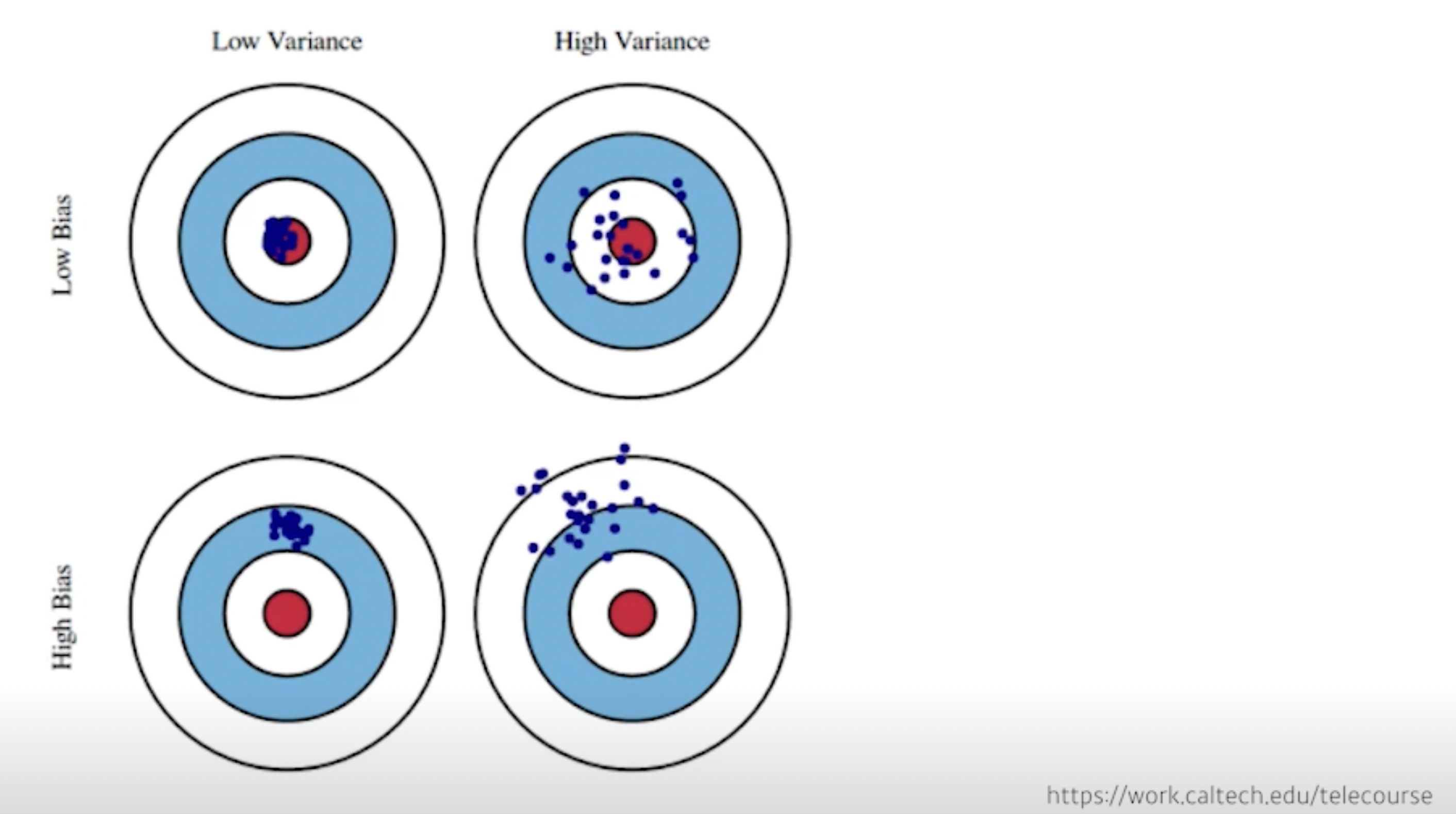
- Bias and Variance Tradeoff
- Bootstrapping
- 훈련 셋에서 중복을 허용하여 샘플링하는 방식
- 각 데이터 셋은 복원 추출(sampling with replacement)을 통해 원래 데이터의 수만큼의 크기를 갖도록 샘플링 (통계학에서는 중복을 허용한 리샘플링(resampling)을 부트스트래핑(bootstrapping)이라고 함)
- 예) original data set = [1,2,3,4,5], bootstrap1 = [3,2,2,3,5], bootstrap2 = [4,1,1,3,2] -> bootstrap1에는 1과 4가 없고 2와 3이 두 개씩 들어있음, 그리고 원래 데이터 셋의 크기가 5이기 때문에 bootstrap의 크기도 5
- Bagging vs. Boosting
배깅(bagging, bootstrap aggregating)
- bootstrapping 샘플링을 한 뒤 bootstrap1으로 만든 모델 , bootstrap2로 만든 모델 , bootstrap3으로 만든 모델 , ... -> 이렇게 각 샘플들로 모델을 만듦 → 그리고 결합(aggregating)
부스팅(boosting)
- 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법
- 부스팅 방법의 아이디어는 앞의 모델을 보완해나가면서 일련의 예측기를 학습시키는 것
- 가장 인기 있는 것은 아다부스트(AdaBoost, Adaptive Boosting)와 그래디언트 부스팅(Gradient Boosting)
Practical Gradient Descent Methods
- Stochastic gradient descent: 하나의 샘플을 통해 gradient를 계산하고 업데이트
- Mini-batch gradient descent: 몇 개의 샘플을 통해(하나의 샘플도 전체도 아닌) gradient를 계산하고 업데이트
- Batch gradient descent: 전체 데이터를 다 사용해서 gradient를 계산하고 업데이트
- Batch-size Matters: 배치 사이즈를 줄이자니 너무 오래 걸릴 것 같고 전체를 활용하자니 gpu가 터질 것 같고…
- batch size를 키우면 sharp minimum에 도달하고, batch size를 줄이면 flat minimum에 도달함(실험적으로)
- 우리의 목적은 testing function(빨간 점선)에서의 최솟값을 찾는 것임
- 하지만 우린 training function(검정 실선)의 정보를 가지고 예측을 해야 함
- 아래 그림을 보면 flat한 그래프일수록 training function 값과 testing function 값의 차이가 적음 → batch size를 작게 잡으면 일반적으로 generalization performance가 좋아진다고 실험적으로 보임
- 그럼 큰 batch size를 사용하려면 어떻게 해야 될까?
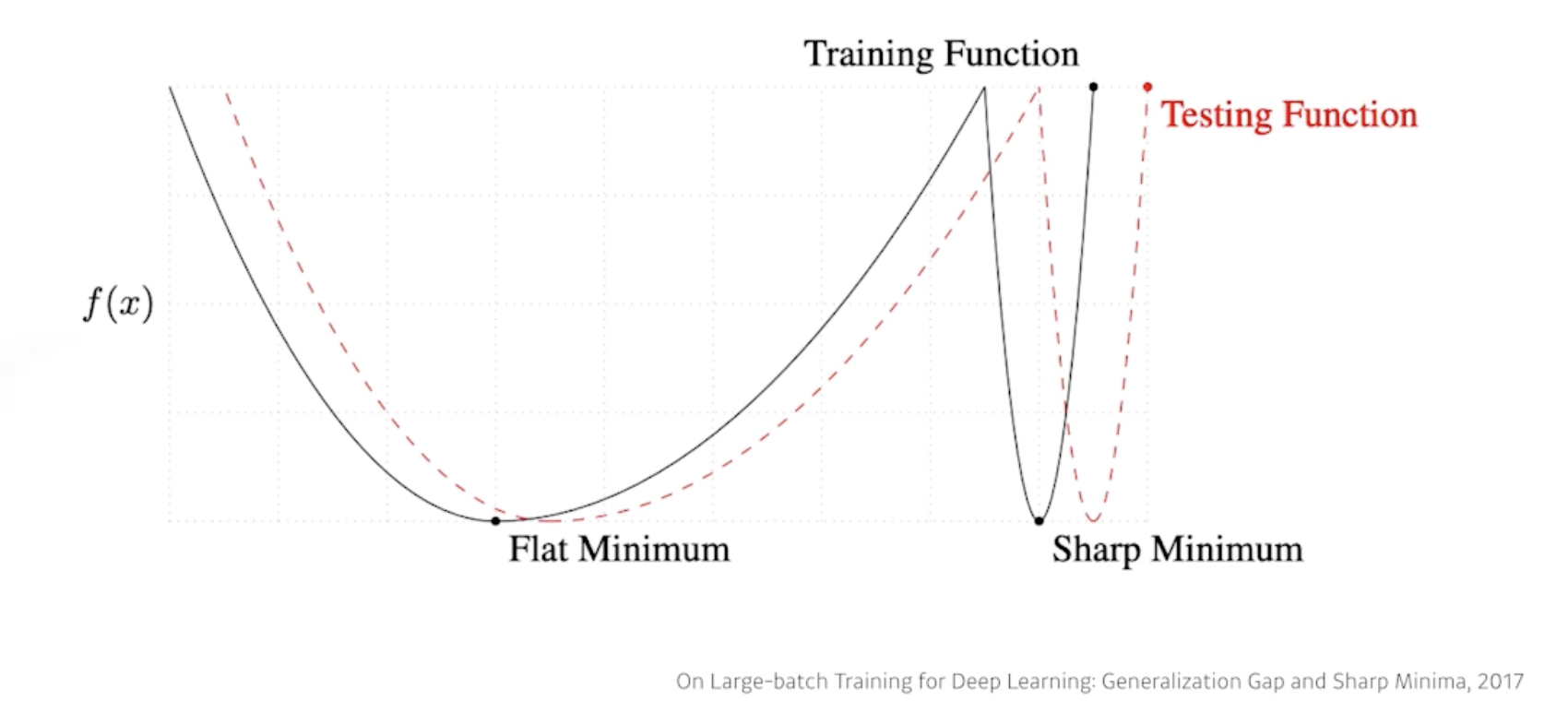
- Gradient Descent
gradient descent의 가장 어려운 점은 learning rate를 잡는 것임 → 아래는 learning rate을 잡는 몇 가지 방법들의 예시
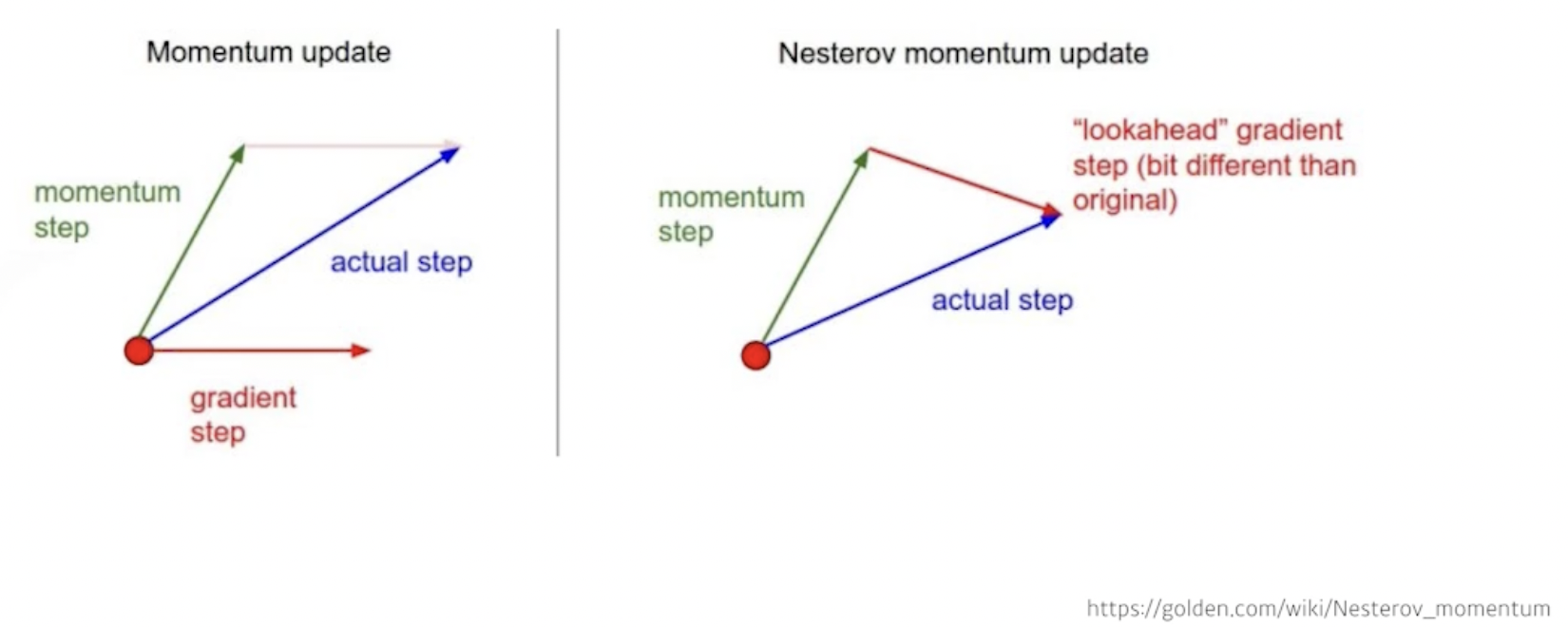
- Momentum: 이전 batch에서 나온 gradient의 정보를 다음 batch에서 활용하자(관성)
- Nesterov Accelerated Gradient
momentum 방식은 내 위치(빨간 점)에서의 gradient와 momentum step을 합침
NAG 방식은 내 위치에서 momentum step으로 이동했다고 생각하고 그 이동한 위치에서의 gradient(lookahead gradient)를 구해서 이동함
- Adagrad
: Sum of gradient squares(지금까지 gradient가 얼마나 많이 변했는지 제곱해서 더함)
: for numerical stability(0으로 나누지 않기 위한)
지금까지 많이 변한 파라미터는 적게 변화시키고, 적게 변한 파라미터는 많이 변화시키기
문제는 값이 계속 커지기 때문에 나중에는 학습이 거의 멈춰버림
- Adadelta
일정 기간의 gradient들로만 를 만들기
learning rate이 없기 때문에 잘 안 씀
- RMSprop
: EMA(exponential moving average) of gradient squares
: stepsize(learning rate)
- EMA(지수 가중 평균): 데이터의 이동 평균을 구할 때, 오래된 데이터가 미치는 영향을 지수적으로 감쇠하도록 만들어주는 방법
- Adam(Adaptive Moment Estimation)
EMA of gradient squares(Adaptive)와 momentum을 함께 사용
: momentum
: EMA of gradient squares
: 모멘텀을 얼마나 유지시킬지
: gradient squares에 대한 EMA 정보
: zero division을 막기 위한 파라미터(default는 1.0e-7인데 이걸 조정하는 것이 중요)
Regularization
generalization 성능을 높이기 위해 규제(학습을 방해)를 거는 것 - 학습을 방해함으로써 test data에 대한 성능이 올라가기를 기대
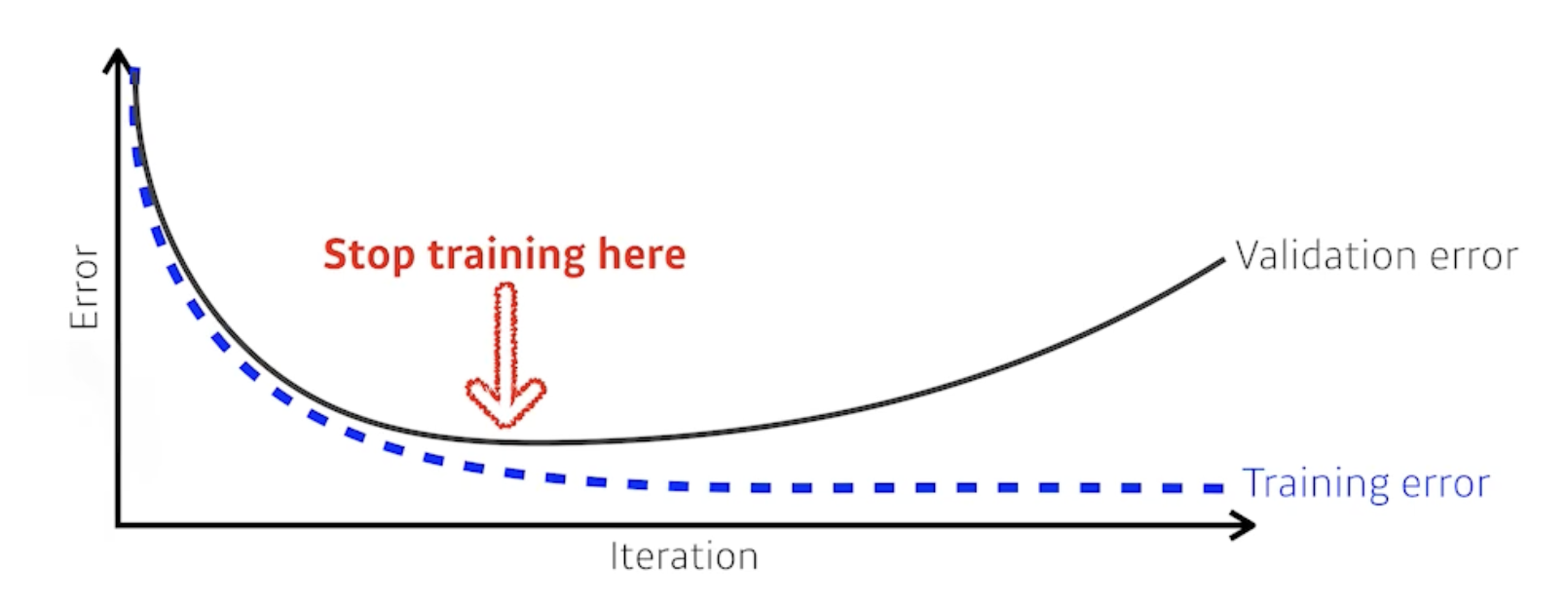
- Early stopping
training에 활용하지 않은 data set(아래 그림에서는 validation data)에 대한 loss를 보고 loss가 어느 시점부터 커진다면 멈추기
- Parameter Norm Penalty
가정: weight vector가 작을 경우 ‘이 함수는 간단하다’라고 간주함 → 함수가 간단할수록 generalization 성능이 높을 것이다. (뉴럴 네트워크의 파라미터들이 너무 커지지 않게 하면 함수가 부드러워질 것이고 overfitting을 줄일 수 있을 것임)
https://ko.d2l.ai/chapter_deep-learning-basics/weight-decay.html
weight vector를 작게 하기 위한 하나의 방법으로는 최소화해야 하는 네트워크의 loss function에 weight vector의 제곱을 penalty로 더해주는 것 → 이렇게 했을 때 weight vector의 제곱이 커진다면 학습 알고리즘은 loss를 최소화하는 것보다 weight vector를 최소화하는 데에 우선순위를 두겠지
- Data Augmentation
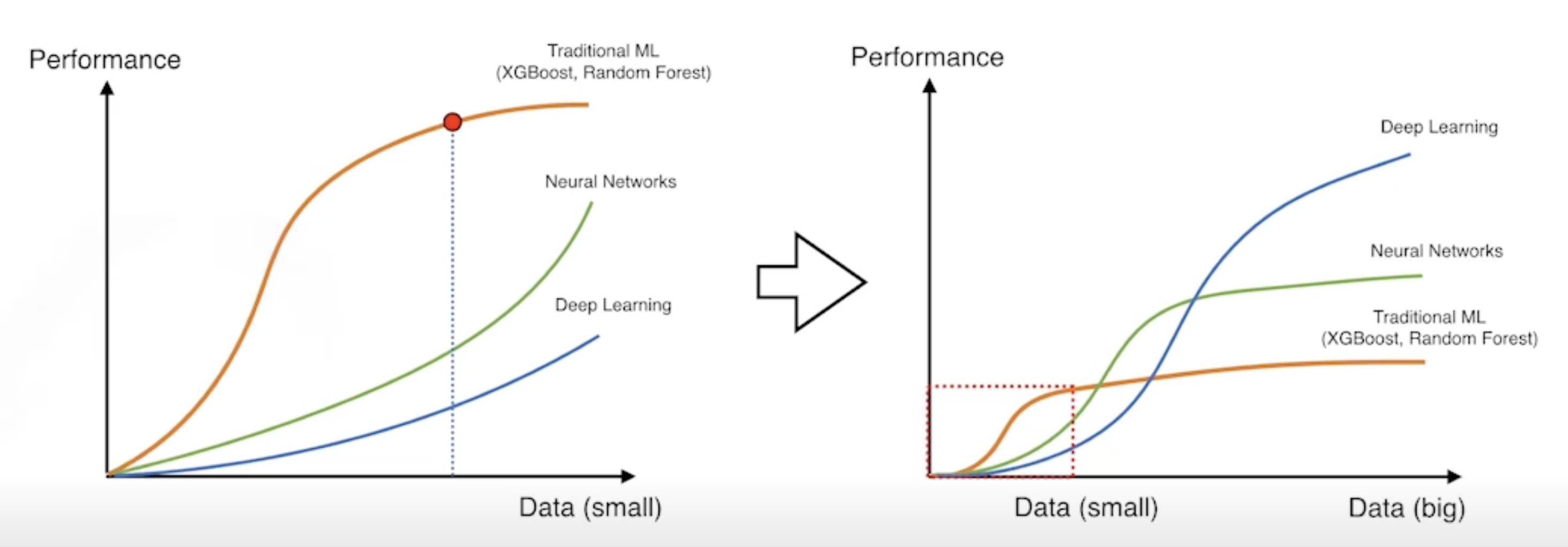
위 그래프에 나온 것처럼 deep learning은 데이터가 매우 많을 때 좋은 성능을 낸다.
Data Augmentation은 기존 데이터로부터 새로운 데이터를 생성하여 데이터의 양을 인위적으로 늘리는 과정이다.
- Noise Robustness
input과 weight에 random noise를 넣으면 성능이 좋아진다는 실험적 결과가 있다.
- Label Smoothing
학습 데이터 두 개를 뽑아서 섞어줌(일반적으로 아래 방법들을 사용하면 성능이 꽤 올라감)

- Dropout
뉴럴 네트워크의 weight을 0으로 바꾸는 것(dropout ratio p=0.5면 랜덤한 절반의 뉴런 0으로 바꿈) → 이렇게 하면 가중치 값들이 다른 특성들 사이에 더 확산되도록 하고, 잠재적으로 가짜 연관들에 더 적게 의존되도록 모델을 학습시킴
https://ko.d2l.ai/chapter_deep-learning-basics/dropout.html
- Batch Normalization(BN)
배치 정규화는 층으로 들어가는 입력값이 한쪽으로 쏠리거나 너무 퍼지거나 너무 좁아지지 않게 해주는 기법
→ 각 층의 파라미터들을 정규분포를 따르게 만들어줌(평균을 빼고 표준편차로 나눠서)
