전체적인 데이터나 code는 공유가 불가능하니 부분적으로만 기록..
Data & BaseLine
Data로는 아래가 주어졌고
- users, books, ratings
baseline code로는 아래와 같이 주어졌다
- FM, FFM, WDN, NCF, CNN_FN, DeepCoNN
전처리

위는 users, ratings, books를 모두 합쳤을 때 null시각화이다
Age
우선 users의 age값을 우선 채워줄 필요가 있었다.
여러가지 생각을 했었다.
1. 단순히 유저의 평균으로 fillna
2. drop
3. age가 null인 사람들이 읽은 책을 읽은 사람들의 나이대의 평균
4. 국가별 나이의 평균1,2 는 가장 기본이 되는 생각이라 일단 제외하고
3. 실제로 책을 읽는다면 나이대가 어느정도 비슷한 연령대에 대해서 책을 읽고 평가를 내릴 것이라 생각해서 3번의 방식으로 null값을 제외한 평균으로 취해주고 진행했다.
4. 추후에 팀원들끼리 얘기하며 나온 방식이며 개인적으로는 아직 실행해보지 않았다.
마지막으로 연령을 10대 20대 ... 로 categorigal하게 변경함으로써 age변수를 채웠다
Image
Image 관련 데이터는 기본적으로 사용하지 않을 것이라 생각해서 애초에 지우고 시작했다.
Category
Category는 null값도 문제였지만 기본적으로 데이터 자체에 굉장히 이상하게 들어가 있는 경우가 많았다
이를 summary와 boot_title을 기반으로 category를 재설정했고 육안으로 봤을 때 기존보다는 더 잘 정리가 된것 같아 그대로 사용하기로 했다.
null값 처리는 아직까지 논의중이다.
publisher
publisher의 경우 대표 publisher를 일정 기준에 따라 추출하여 대표 publisher를 포함하는 모든 publisher를 묶어서 진행했다.
import re
import tqdm
bcpy = books_df.copy(deep=True)
bcpy.loc[bcpy[bcpy['publisher'].notnull()].index, 'publisher'] = bcpy[bcpy['publisher'].notnull()]['publisher'].apply(lambda x: re.sub('[\W_]+',' ',x).strip())
bcpy['publisher'] = bcpy['publisher'].str.lower()
bcpy['publisher'] = bcpy['publisher'].apply(lambda x : re.sub('books?|publishing|publisher','',x).strip())
bcpy2 = bcpy.copy(deep=True)
# publisher의 리스트 만들기 위함
publisher = bcpy2.groupby("publisher").count()['isbn'].sort_values(ascending=False)
# penguin books, penguin adas, penguin ... 등 publisher개수를 4개 이상 있는 경우 <- 여기 고쳐주면 대표 publisher 갯수 조정
publisher = publisher[publisher.values>4]
publisher_list = []
for p in tqdm.tqdm(publisher.index):
# p가 너무 다양한 publisher를 포함할 수 있는 단어들은 제외
if p =='i' or p == 'pan' or p == 'roc' or p == 'que' \
or p == 'ump' or p== 'asa' or p=='pol' or p=='rac': continue
# a a 등 이상한 publisher들은 중간 공백 제거후 너무 짧은건 제외 (tv도 있었지만 그냥 제외)
w = p.replace(" ",'')
if len(w) < 3 : continue
cont_p = bcpy2[bcpy2['publisher'].str.contains(p)]['publisher']
idx = cont_p.index
publisher_list.append(p)
bcpy2.drop(idx, axis=0, inplace=True)
print('---finish---')
#####################셀 나누는 구간###########################
print("기존 publisher nunique : ", bcpy['publisher'].nunique())
print("수정후 : ", len(publisher_list))
#############################################################
idx_list = []
# 속도 조금이라도 빠르게 하기 위해서 인덱스를 계속 삭제하기 위한 df
bcpy2 = bcpy.copy(deep=True)
for publisher in tqdm.tqdm(publisher_list):
idx = bcpy2[bcpy2['publisher'].str.contains(publisher)].index
idx_list.extend(idx)
bcpy.loc[idx,'publisher'] = publisher
bcpy2.drop(idx, axis=0, inplace=True)
idx = bcpy.drop(idx_list, axis=0).index
bcpy.loc[idx, 'publisher'] = 'etc'
print('---finish---')
#############################################################
bcpy['publisher'].value_counts()
그렇게 기존 정돈되지 않아있던 publisher를 10938개에서 2496개까지 추려낸 후 불필요한 index까지 최종적으로 추려낸 결과
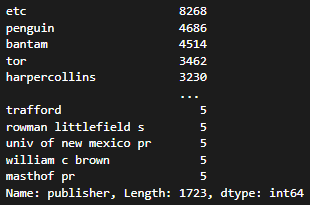
대표 publisher는 1723개까지 줄일 수 있었으면 etc로 통합된 약 700개를 생각해보면 나름 유의미하다고 생각했다.
(대표 pubisher의 갯수는 언제든지 바꿀 수 있기 때문에 언제든지 수정 가능 -> 그만큼 etc가 늘어남)
모델링
feature를 잡기위해서 실제 책을 읽는 사람들의 관계를 생각해봤다
- 같은 지역에 있는 사람들은 유사한 책을 읽었을 때 점수에 유의미한 관계를 나타낼 것이다.
- 비슷한 연령대의 사람들은 유사한 책을 읽었을 떄 점수에 유의미한 관계를 나타낼 것이다.
- 비슷한 내용의 책에 대해 비슷한 평점을 보일 것이다.
그렇게 여러가지 생각을 하니 Context Aware Recommendation 관련한 것이 가장 유의미할 것이라 생각했고 다음으로는 Summary를 요약한 Text처리 DL이 유용할 것이라 생각해서 Fm, FFM, DeepCONN, GBM계열, DeepFM, WDN 등에 대해 기본적으로 생각했다.
이후 DEEPFM을 구현하며 전체적인 성능을 측정했지만
아래 WANDB에서 볼 수 있듯이 DeepCoNN을 제외하곤 default에서 성능은 그다지 좋은 모습을 보이지 못하는 경향이 있는 것 같다.
왜 DeepCoNN을 제외하곤 일정 수준에서 overfit이 일어나는 경향을 보이는지에 대해 고민중이다.
심지어 WDN과 DeepFM의 hybrid model같은 경우 FM, FFM보다 성능이 더 좋길 기대했는데... 오히려 더 개판이다...
WANDB
WANDB를 돌리면서 로그를 남기고 하이퍼 파라미터에 따른 변화를 봤다.
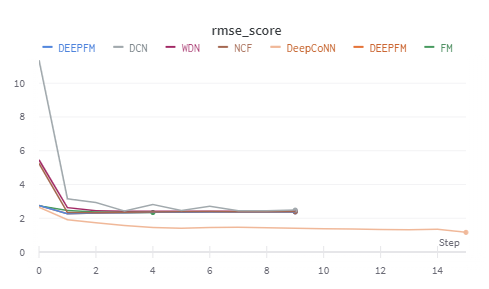
1차적으로 하이퍼 파라미터 튜닝없이 base line코드를 모두 돌렸을 때 DeepCoNN을 제외한 대부분 epoch 4이상부터 overfitting되는 경향이 있었고 DeepConn은 계속해서 학습이 진행되는 듯 보였다.
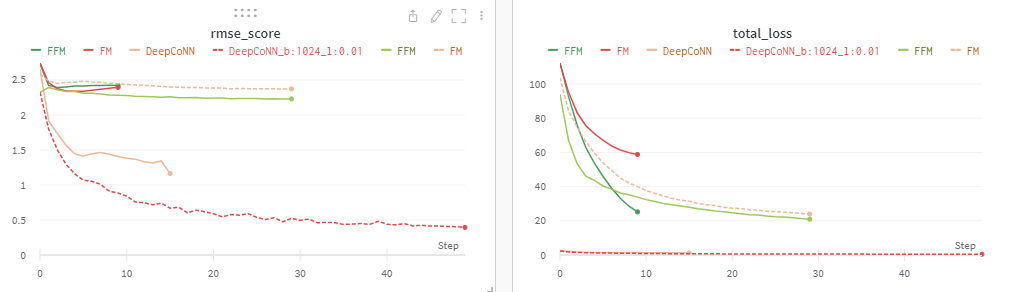
다시 LR을 0.01로 취했을 때 대부분 성능이 좀 더 좋게 나온 것을 확인했고 이후 epoch을 늘림으로써 Learning Rate를 0.01로 default를 잡았다.
( LR이 0.001보다 0.01에서 더 잘 학습되는 이유는 아마 start 지점에서 운좋게 minima되는 부분을 한번 피해서 진행할 수 있었기 때문이 아닌가 싶다... )
진행하면서... 난 뭘 했고... 뭘 느꼈나..
AI BoostCamp를 시작하고 나서 첫 Team Project이다. 그러다보니 git도 wandb도 잘 사용하지 않고 기존처럼 local에서 하려는 습관들이 있었다. 난 대회의 성적보다 우선시할 것이 왜 이 모델을 썻고 협업은 어떻게 하는지에 대한 base를 쌓는 기간이라 생각해서 팀원들에게 적극적으로 git과 wandb사용을 하자고 얘기했다.
wandb의 경우 내가 계정을 파고 초기 설정부터 관련 코드 및 로그를 남길지 아닐지에 대한 args지정 등 제안했고 이를 모두 잘 활용했지만 git의 경우 협업으로써는 아직 다들 익숙한 느낌은 아닌것 같다. git의 baseline 업데이트 역시 도움을 받으며 내가 올려놓긴 했지만 이후 brach update도 생각보다 자주 있지 않았고 (나 포함) 코드 공유는 회의할 부분 부분적으로 필요한 부분만 서로 보여주며 진행해서 조금 아쉬웠다.
추후 프로젝트에선 좀 더 적극적으로 git을 사용할 필요가 있음을 느낀다.
