팀원들을 통해 여러가지 기술들을 많이 익히고 고려해야될 사항들에 대해 더 공부를 많이 하게 됐다.
Data Leakage 고려
train data만 쓴다곤 하지만 그럼에도 Sequential한 부분이 포함돼 있을 수 있다면 test의 특정 상황보다 미래의 정보가 train에 들어있어 test의 특정 시간대 이상의 정보를 활용함으로써 data leakage가 있을 수 있다고한다..
(사실 어떤 말인지는 이해하지만 이렇게 치면 통계적인 방법으로 null값 처리라던지.. 그런 모든 부분은 사용할 수 없는건가 싶은데 팀원의 말이니까 나중에 좀 더 확인해봐야겠다.)
WANDB Sweep
WANDB에서 sweep이란 기능을 처음 알게됐다. 기본적으로 oputna와 유사한 기능이며 특정 하이퍼파라미터의 범위를 지정해주면 알아서 돌아가며 실행하고 최적의 파라미터를 찾을 수 있게끔 도와준다.
(일단 튜토리얼 사이트를 확인해보자)
Sweep Tutorial : https://docs.wandb.ai/guides/sweeps/quickstart
<실행결과>
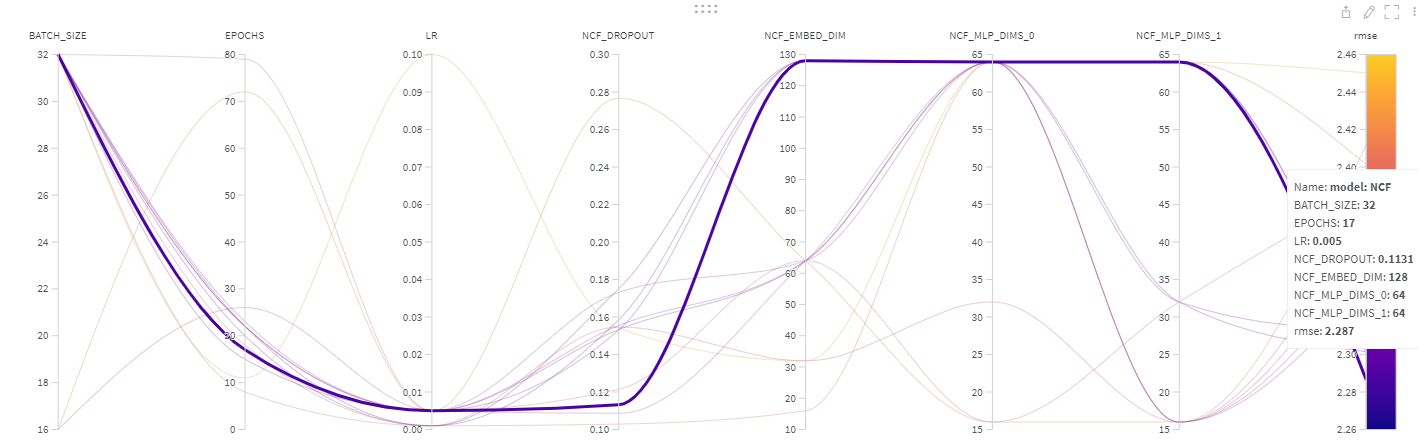
이런식으로 sweep내 만들어진 객체에서 원하는 파라미터의 최적값을 확인할 수 있다
<파일 구성 및 내용>
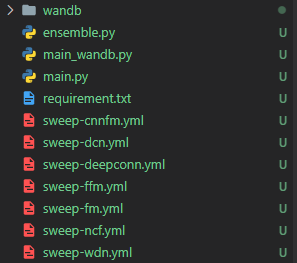
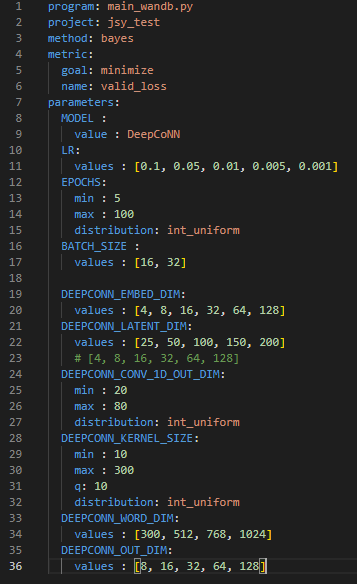
기본적으로 필요한 모델에 대한 yml파일을 생성해줘야하며 파일은 원하는 hyper parameter의 범위를 지정해주면 된다.
이때 porject를 통해서 항상 본인이 실험할 sweep project를 명시적으로 적어두자.
<사용방법>
일단 wandb를 설치하고 & 공용 구글 계정으로 로그인하기!!
root@12a9e54cfaa5:~/input# pip install wandb --use-feature=2020-resolver
root@12a9e54cfaa5:~/input# wandb login.yml file이 있는 경로로 이동하기 : $cd code\본인 코드 디렉토리 ex) code\JSY_code
(base) root@12a9e54cfaa5:~/input/code# wandb sweep sweep-ncf.yml
wandb: Creating sweep from: sweep-ncf.yml
wandb: Created sweep with ID: yed9ouxf
wandb: View sweep at: [https://wandb.ai/recsys09lev1/baselineTest/sweeps/yed9ouxf](https://wandb.ai/recsys09lev1/baselineTest/sweeps/yed9ouxf)
wandb: Run sweep agent with: wandb agent recsys09lev1/baselineTest/yed9ouxf
(base) root@12a9e54cfaa5:~/input/code# wandb agent recsys09lev1/baselineTest/yed9ouxfwandb sweep <yml 파일명>으로 일단 yml 파일을 실행- 1번 코드를 실행했을 때 가장 밑에 줄에 ~~ with: 다음부분 복사+붙여넣기!!!
- baselineTest쪽 바꿔서 원하는 프로젝트에서 결과보기
서버 연결이나 터미널을 종료해도 알아서 잘 돌아가게 하고 싶다면? nohup 사용
nohup wandb agent recsys09lev1/baselineTest/yed9ouxf > sweep-ncf.out &- 코드 앞에
nohup붙여주고 / 맨 뒤에는&을 붙여줌 - 로그를 기록할 파일 이름을
>뒤에 써줌 :> sweep-ncf.out
nohup으로 실행했는데 중간중간 로그가 잘 기록되고 있는지 확인하고 싶다면? (파일을 까봐도 되지만..)
(base) root@12a9e54cfaa5:~/input/code# tail -f sweep-ncf.outModel
시도한 모델
여러 계열들의 모델들을 돌려봤다
- Bagging : Random Forest
- Boosting : lightGBM, catboost
- Context Aware : FM, FFM
- DL : WDN, DeepFM, NCF
- TextData : DeepCoNN
기본적인 생각은 추천을 하는데 있어 user와 item의 side information의 영향이 클것이라 생각해서 context Aware가 가장 높길 기대하고 나머지 모델들은 다른 모델들과 비교하고 앙상블하기 위해서 돌려본 감이 크다.
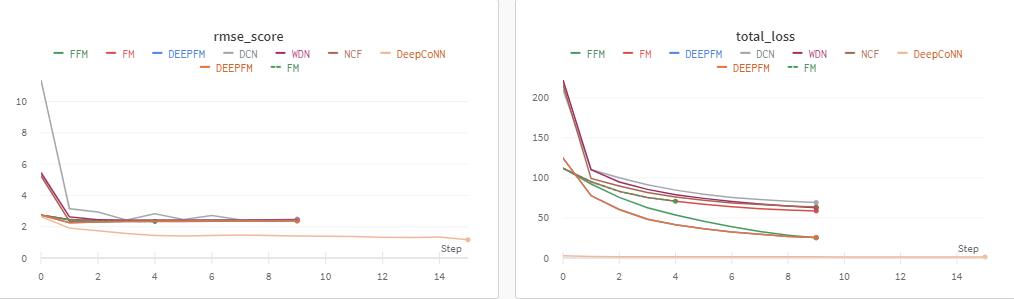
그러나 base line으로 하이퍼파라미터 튜닝없이 진행했을때 생각외로 DeepCoNN의 RMSE값이 가장낮고 학습이 잘되는 반면 다른 모델들은 epoch가 3이상만 되더라도 overfitting되는 경향이 보였다.
(bagging / boosting 등은 추후 새로 만든 모델..)
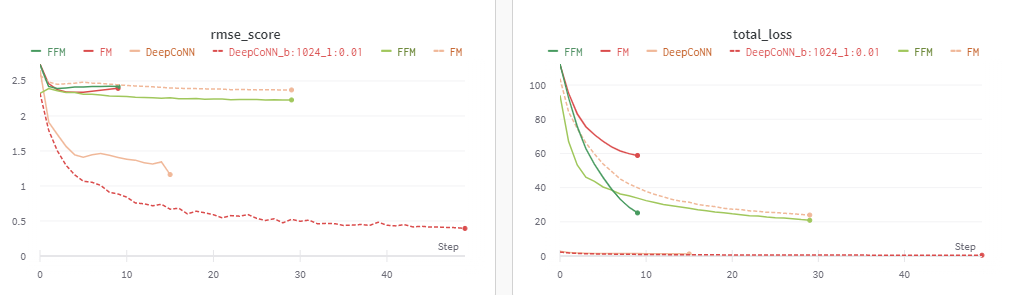
기존에 생각했던 Context Aware방식 2가지와 가장 성능이 좋았던 DeepCoNN에 대해 하이퍼파라미터 튜닝을 한 결과 성능차이가 크게 나타났으며 이때 주로 튜닝한 하이퍼 파라미터는 LR이었다
기존 baseline에서 LR=0.001이었던 반면 튜닝한 LR=0.01이었고 이 때 결과가 더 잘나오는 것이 잘 이해가 안됐으나 멘토님께서 아마 start지점의 차이로 인해 운좋게 LR가 높음에도 불구하고 성능이 잘 찍힌것 처럼 보이지 않았을까 하는 답변을 들었다.
답변은 이해는 했지만 그럼에도 정확한 원인은 아직 잘 모르겠다...
이후 WDN과 DeepFM과 같은 Hybrid System에서도 성능이 잘 나오길 기대했으나 WDN은 Baseline 코드에서 전처리만 바꾸고 DeepFM은 내가 직접 구현했는데 모두 성능이 좋게 나오진 않았다..
아마 MultiLayer를 쌓는 부분에서 과적합이 나는 것 같아 Embedding Dimension / Multilayer dim / drop rate / LR / EPOCH/ Batch size 를 바꿔가며 다양한 시도를 해봤지만 overfit에서 벗어나지 못해 사용하지 않았다.
최종 사용 csv
최종적으로 단일 모델에 대한 성능이 가장 높은 모델들을 사용했고, 각 계열들이 서로 다른 outlier를 잡아주길 원해 계열들에서 대표적인 것들을 사용함으로써
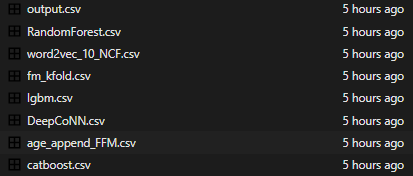
이러한 파일들을 사용하게 됐다
- output.csv : [FM(0.35) / FFM(0.35) / DeepCoNN(0.3)] ensemble file
- Randomforest.csv : random forest
- word2vec_10_NCF.csv : NCF
- fm_kfold.csv : fm을 kfold를 통해서 얻은 csv
- lgbm.csv : lgbm
- DeepCoNN.csv : DeepCoNN epoch100
- age_append_FFm.csv : 나이를 다른 방식으로 처리한 FFM모델
- catboost.csv : catboost
Ensemble
위에서 나온 csv들에 대해 앙상블을 진행하여 점수를 내기로 결정했다
그전에 각각의 분포와 앙상블 했을 때의 분포를 확인하기로 했다.
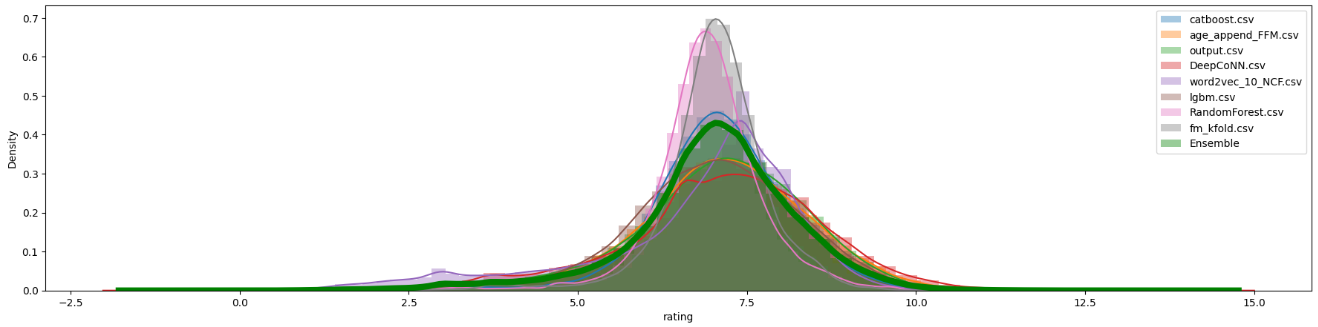
결과값에서 regression으로 진행해서인지 평점이 1점이하부터 10점 이상인 평점들이 있었다.
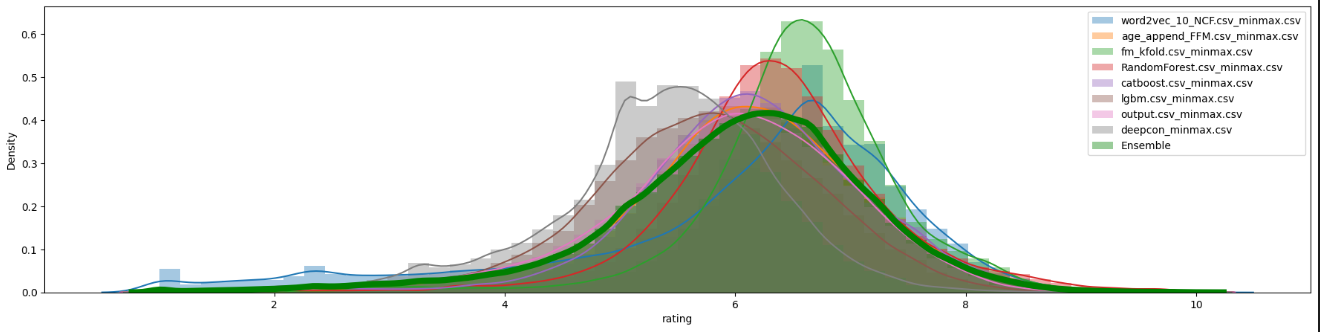
이상치가 있는 파일들을 minmax()를 진행해줌으로 rating을 올바르게 정리해준 후에 다시한번 분포를 확인해보니 위와 같았다.
결과적으로 leader board의 public 점수는 조금 떨어진 결과를 얻었지만 무시할 수는 없는 발견인 것 같아 시간이 된다면 여러가지 방법으로 다시 돌려봤으면 좋겠다. 그러나 이걸 발견한게.. 대회 종료 3시간 전이여서.. public 점수를 높일 수는 없을 것 같다..
