
💻 20240423 진행내용
1. Stable diffusion
2. 포트폴리오 레퍼런스 리서치
3. stable diffusion 코드 활용 실습
4. 온라인 강의 : UX 리서치 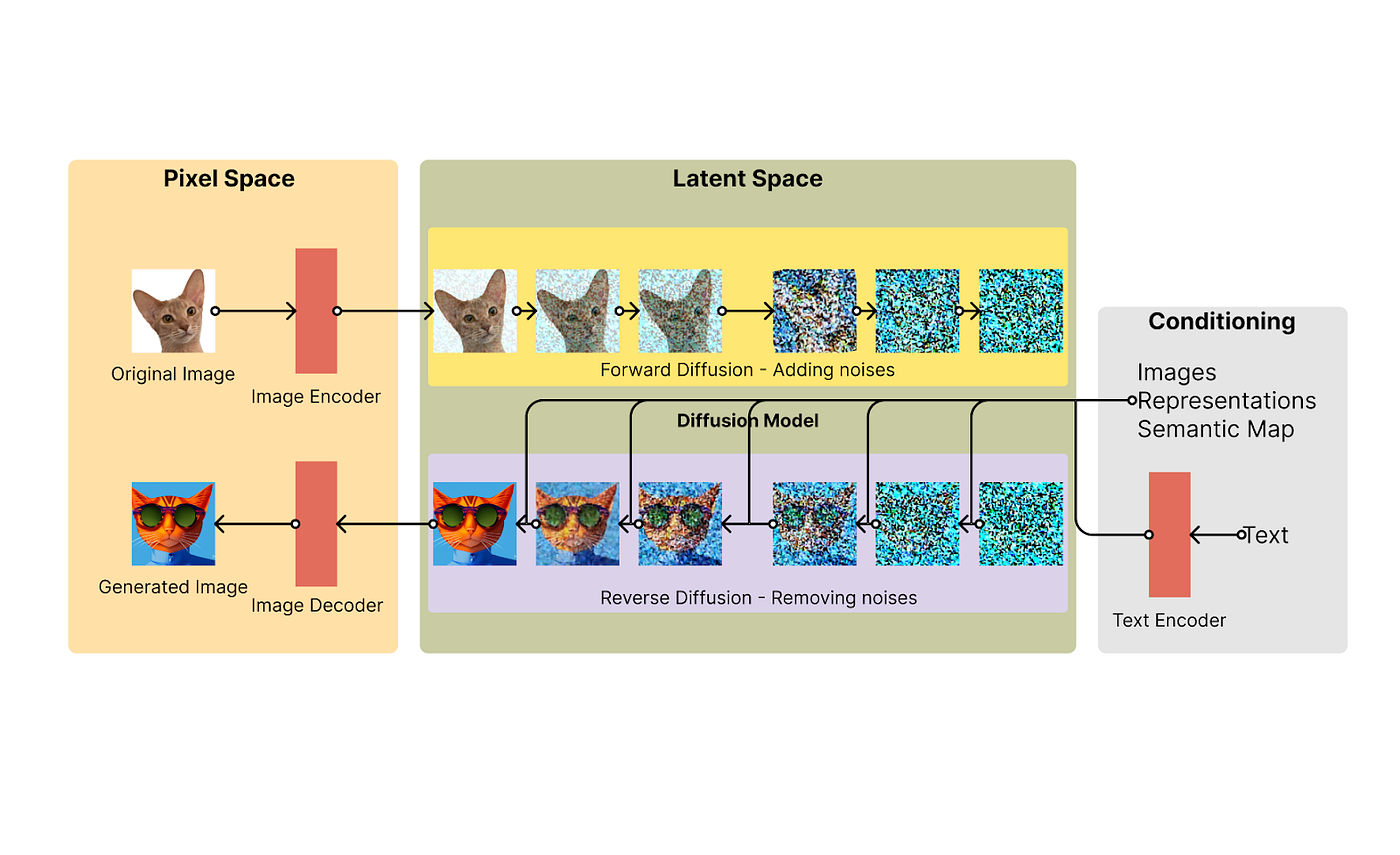
Diffusion 모델이란
최근 딥러닝 분야에서 대표적인 이미지 생성 모델로 Autoencoder, GAN, Diffusion 모델이 있다. Autoencoder는 학습 속도가 빠른 반면, 생성된 이미지의 품질이 낮다는 단점이 존재한다. GAN은 높은 품질의 이미지를 생성할 수 있지만, 원하는 다양한 결과를 얻기 어려운 단점이 있다. Diffusion 모델은 품질, 다양성 측면에서 모두 우수한 성능을 보이는 특징이 있다.

Stable diffusion이란 ?
stable diffusion은 이미지 생성 분야에서 활용되는 AI기술이다. 이 기술은 텍스트를 이미지로 변환하는 "텍스트 이미지 변환(Text-to-Image Translation)" 기술 중 하나로, 사용자가 텍스트 프롬프트를 입력하여 원하는 이미지를 생성한다.
stable diffusion은 2022년 8월 22일에 공개되었고, 오픈 소스 라이선스로 배포되어 무료로 다운받아 사용할 수 있다.
디자이너가 Stable diffusion을 어떻게 활용할 수 있을까?
나는 예전에 학부 연구생 시절 선배들과 함께 딥러닝 스터디를 하면서 stable diffusion에 대해서 알게 되었다. 그런데 UXUI를 공부하면서 stable diffusion을 에이전시에서 활용하는 곳이 늘어나고 있다는 것을 알게 되어 더욱 흥미를 가지게 되었다. 그럼 stable diffusion을 어떻게 활용할 수 있을까?
미드저니,스테이블 디퓨전으로 컨텐츠 맞춤 이미지를 생성하고 이를 브랜드 컨텐츠로 활용할 수 있다. 즉, 생성AI를 활용해 브랜드 컨셉에 맞는 이미지를 제작하는데 주로 활용할 수 있다.
Diffusion의 원리는 무엇일까?
Diffusion 모델은 기본 이미지(시간 t=0)에 노이즈(랜덤 색상의 점)을 추가하는 원리이다. 이때, 다음의 원리로 노이즈를 추가해가는 것이 특징이다.
1. 분산은 무한대이며, 분포의 형태는 변하지 않는다.
2. 양의 값과 음의 값 모두를 가지며, 확률적으로 변동한다.
3. 정규분포와 유사하게 중심극한정리(Central limit theorem)가 성립한다. 
1000번 정도 반복하면 퓨어한 노이즈(t=1000)를 얻을 수 있다. 그리고는 이미지 픽셀 값을 확률적으로 역전파하는 방식으로 셀수없이 반복하면서 다시 원본 t=0시점의 사진을 구현한다. 이런 과정을 거친 모델이 OpenAI에서 발표한 DALL-E2 모델이다.
이미지 생성을 순차적인 단계로 진행하면서 생성된 이미지를 점차적으로 완성시키는 방식이다. 이 과정에서 생성된 이미지는 초기에는 낮은 품질을 보이지만, 점차적으로 높은 품질로 수렴하게 된다.
또한 이미지 생성 과정에서 모델이 생성한 이미지를 이전 단계의 이미지로부터 구분할 수 있도록 하는 Diffusion process를 사용한다. 이러한 과정을 통해 생성된 이미지의 다양성과 높은 품질을 유지할 수 있다.

stable diffusion이 엄청난 관심을 받고 있는 이유
-
비싼 리소스를 들여 학습한 모델과 코드 뿐 만 아니라, 사용한 데이터를 모으는 방법 등을 모두 공개했다. 누구나 사용 가능하며, 이를 기반으로 다양한 연구나 서비스 개발을 할 수 있도록 만들었다.
-
일반 GPU 1장으로도 충분히 inference 할 수 있을 정도로, 효율적이며 성능이 꽤 잘 나오는 모델이다.
이 모델이 효율적이라는 것이 중요한 점이다. 머신러닝 모델이 실제로 사용이 되려면 성능은 둘째치고 모델의 효율성이 굉장히 중요하다. Transformer 기반의 대규모 모델이며, 모델 크기가 곧 성능이라는 결과를 보여준 GPT3가 큰 인기를 얻은지 시간이 꽤 지났고, 더 좋은 성능을 내는 모델들이 많이 나왔지만, 아직도 현업 NLP 분야에서는 BERT 정도 규모 이상의 모델을 사용하기에는 부담스러운 상태이다. 모델의 크기가 너무 크고, inference 시간도 오래 걸리기 때문이다. 이런 경우 서비스화 시키기도 어렵고, 서비스화 하더라도 비용 문제가 너무 커지기 때문에 가성비가 나오지 않는 문제가 있다.
DALLE나 Google의 Imagen 등은 매우 큰 규모의 모델이기 때문에, 일반적인 GPU에서는 inference를 할 수 없다. 일반적으로 머신러닝용 고성능 GPU 여러개가 필요하다. 학습할 때도 수천장의 GPU를 사용하고 inference를 할 때도 4~8개 정도 필요하다 보니 비용적인 측면에서 어려운 부분이 존재한다.
하지만 stable diffusion은 prompt engineering을 조금만 진행하면 GPU 1대만 있는 그리 높지 않은 성능의 서버에서도 꽤 준수한 결과가 나오게 되며, 그렇기 때문에 누구나 쉽게 사용하는게 가능해졌다. NLP쪽에서 BERT 이후로 수 많은 응용 모델과 서비스가 탄생한 것 처럼, 앞으로 stable diffusion을 활용하여 서비스계의 혁신이 일어날 수도 있지 않을까 생각한다.
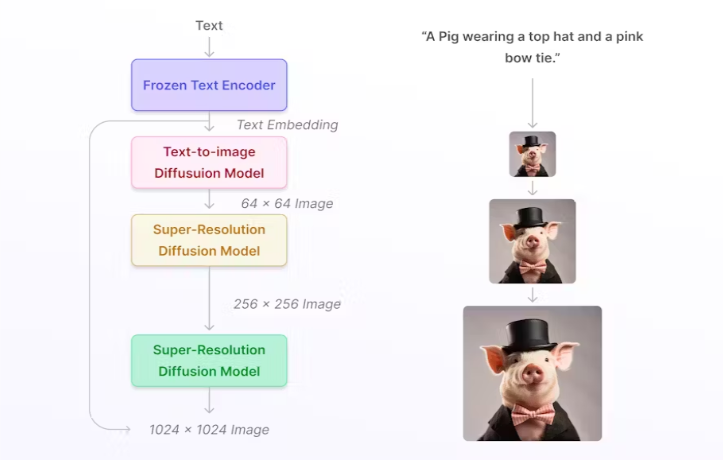
Google - Imagen의 기본 구조

Imagen은 입력 텍스트로부터 사실적인 이미지를 생성하는 AI 시스템이다.
[ Imagen의 시각화 ]
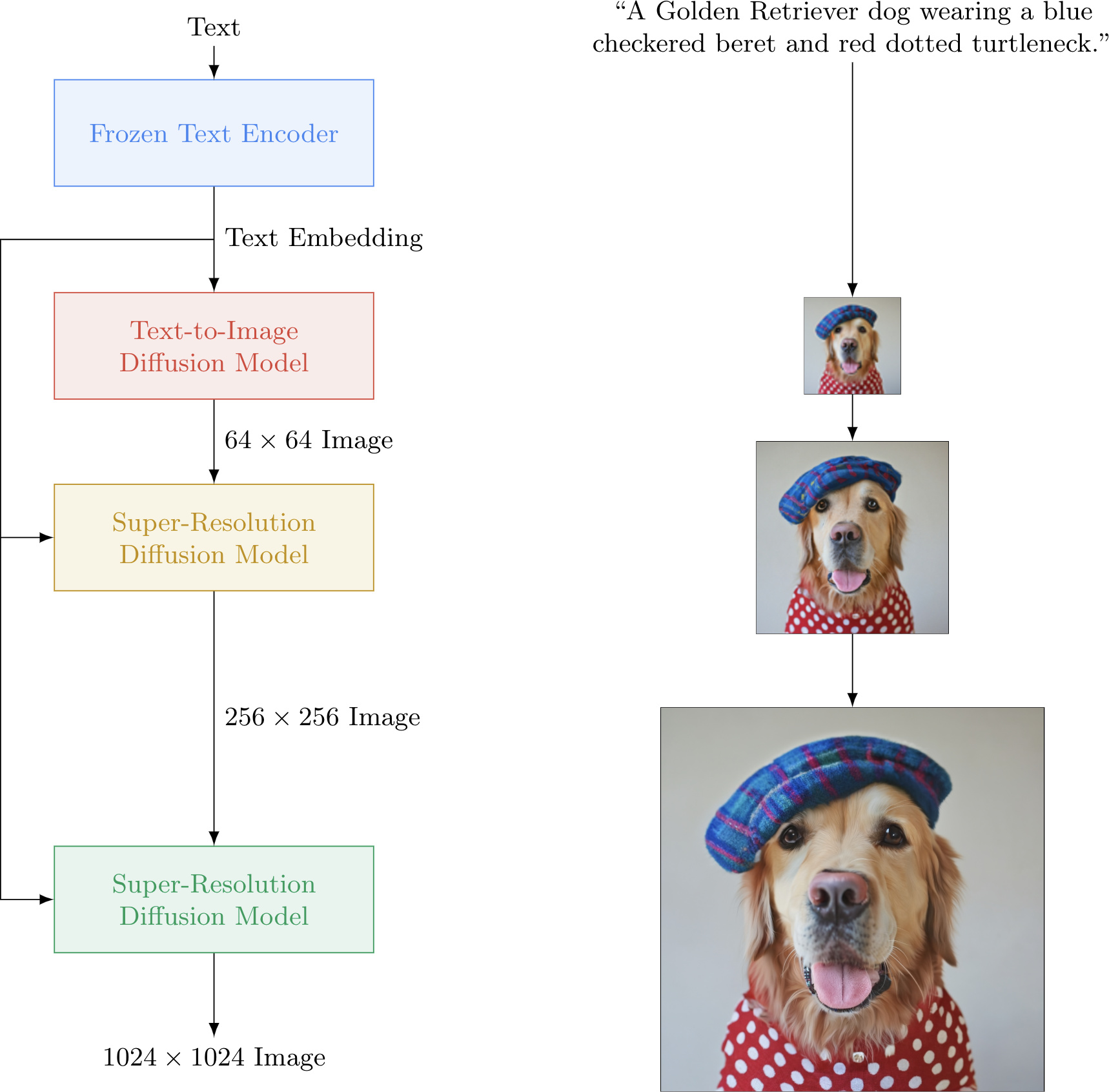
Imagen의 기본 구조이다. 사용자가 입력하는 캡션은 text encoder로 들어가고 이것이 numerical representation으로 변경이 된다. 이 text encoding 값을 활용해서 Image generation model에서는 샘플 노이즈로부터 output을 생성해내게 되는데, 이때의 이미지의 크기는 아주 작다. 이걸 두 번의 Super resolution을 거쳐서 최종적으로 1024 X 1024 크기의 이미지를 생성해낸다. (Super resolution 과정 중에도 text encoding 값을 활용해서 성능을 향상시키는 형태)
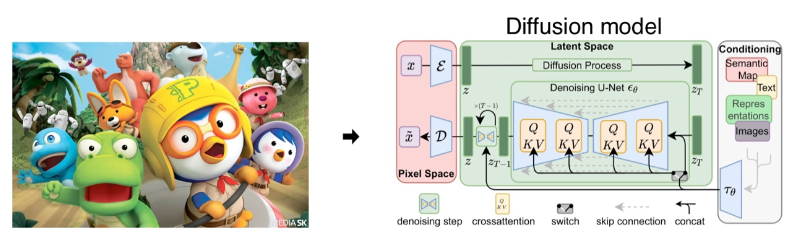
Diffusion model

Diffusion model은 training dataset과 비슷한 데이터를 생성하는 방법이다. 학습 과정에서 training data에 지속적으로 noise를 추가해서 데이터를 망가뜨리는데, 이걸 원상복구 하는 과정을 학습하게 된다.
Stable diffusion 실습해보기
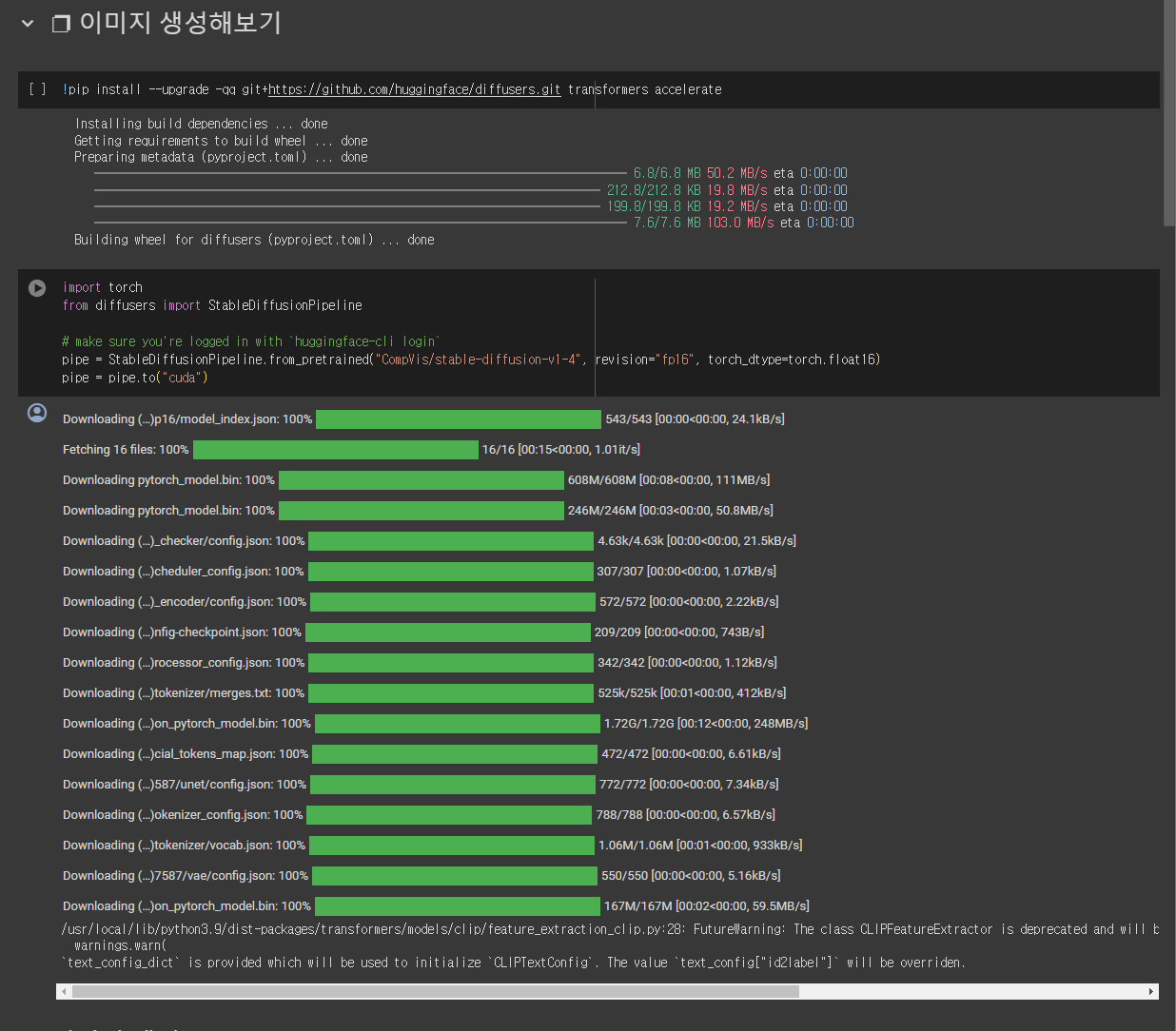
- 메뉴 ➡️ 런타임 ➡️ 런타임 유형 변경 ➡️ GPU 선택
!pip install --upgrade -qq git+https://github.com/huggingface/diffusers.git transformers accelerate- 모듈 import
import torch
from diffusers import StableDiffusionPipeline
# make sure you're logged in with `huggingface-cli login`
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to("cuda")- 생성하고 싶은 이미지에 대해 프롬프트 작성
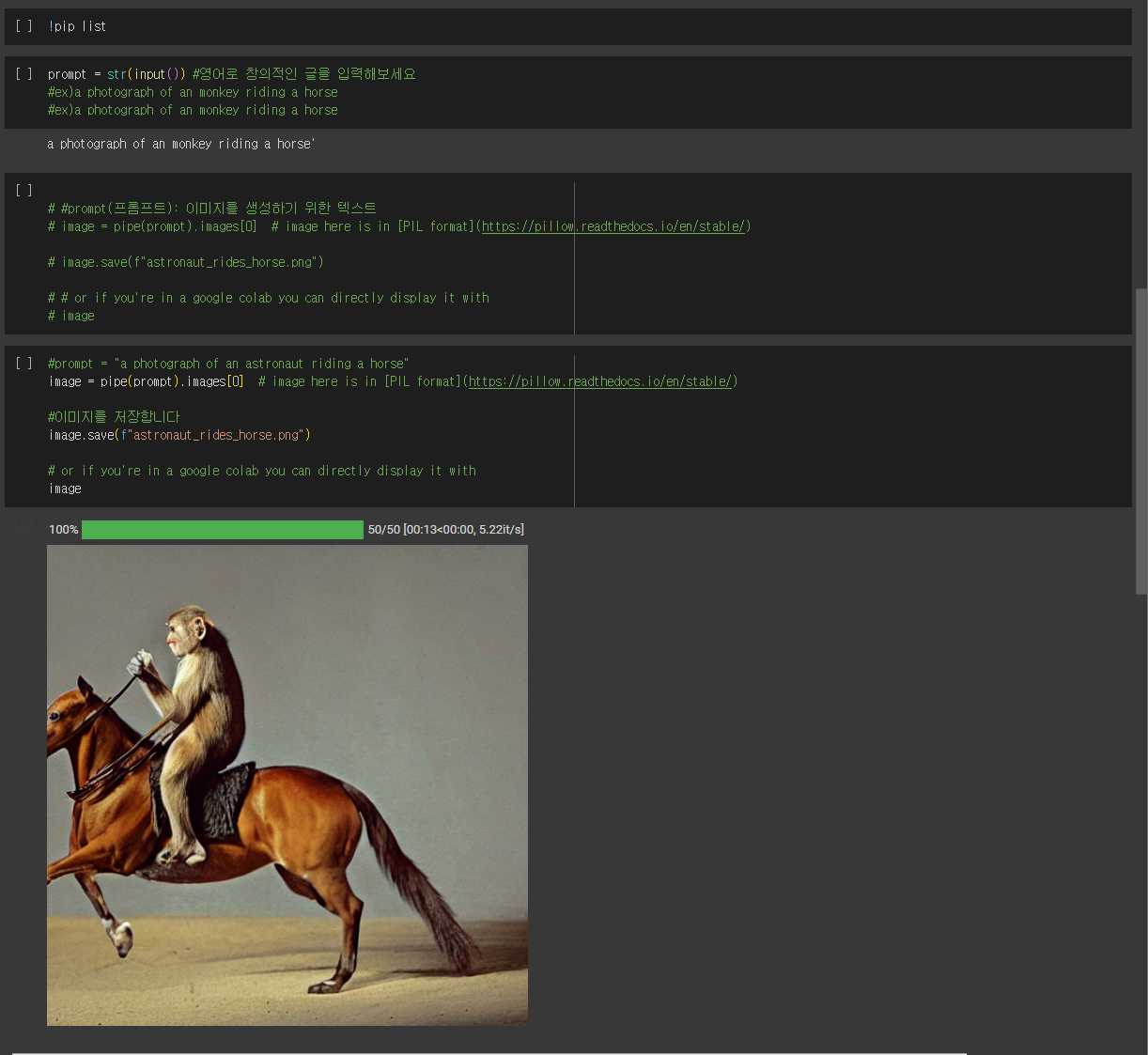
prompt = str(input()) # 영어로 창의적인 글을 입력해보세요
#ex)a photograph of an monkey riding a horse#prompt(프롬프트): 이미지를 생성하기 위한 텍스트
image = pipe(prompt).images[0] # image here is in [PIL format](<https://pillow.readthedocs.io/en/stable/>)
image.save(f"astronaut_rides_horse.png")
# or if you're in a google colab you can directly display it with
imageimage = pipe(prompt).images[0]
# image here is in [PIL format](<https://pillow.readthedocs.io/en/stable/>)
image.save(f"astronaut_rides_horse.png")
# or if you're in a google colab you can directly display it with
image이미지 여러개 생성
from PIL import Image
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid- 프롬프트에 원하는 이미지 내용 입력하기
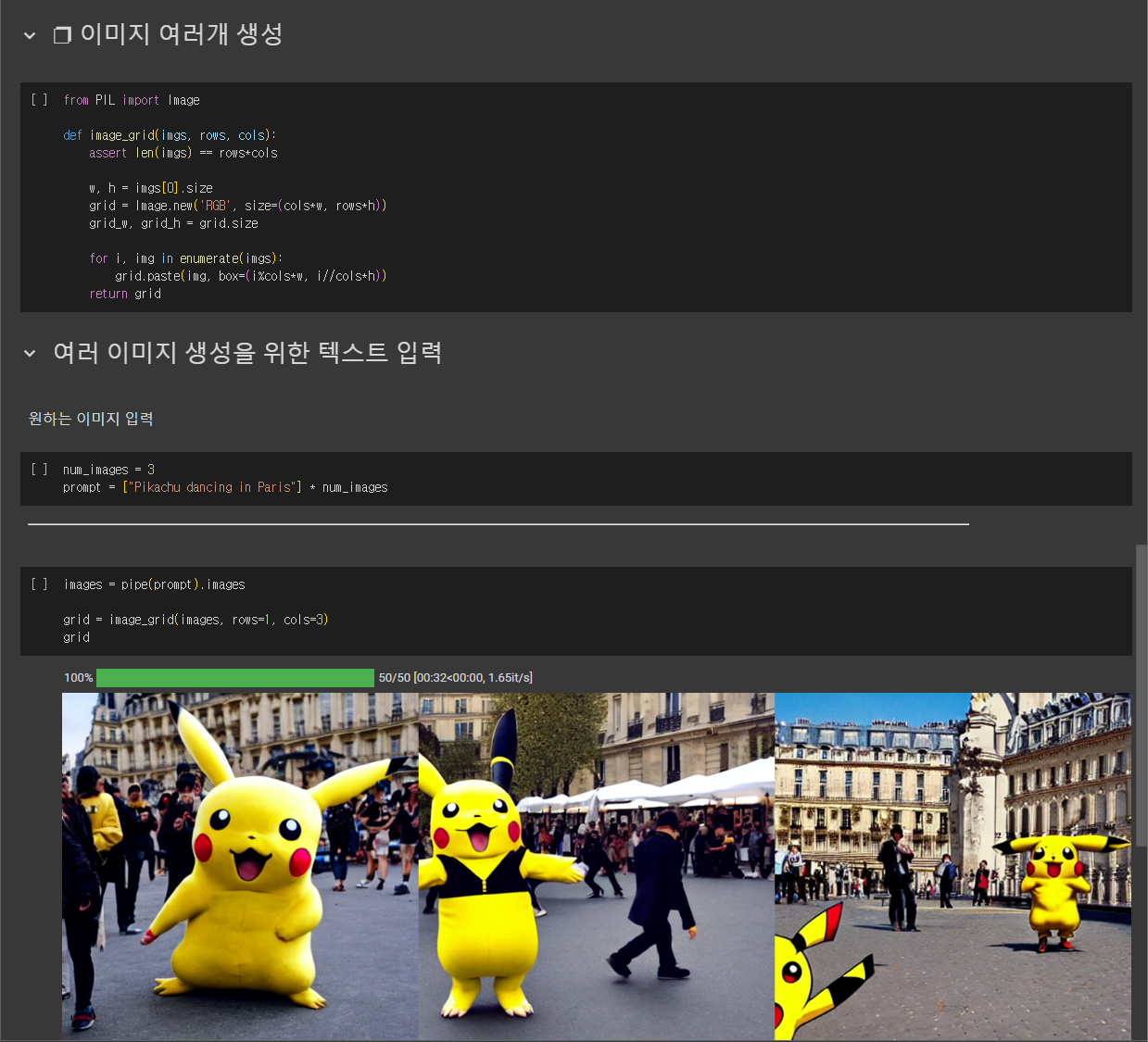
num_images = 3
prompt = ["Pikachu dancing in Paris"] * num_imagesimages = pipe(prompt).images
grid = image_grid(images, rows=1, cols=3)
gridnegative_prompt : 이미지에 묘사되지 말아야 하는 텍스트
seed : 시드에 따라 다양한 이미지 생성 (같은 프롬프트여도 시드가 다르면 이미지가 조금 달라짐)
num_inference_steps : 추론 단계의 수, 일반적으로 사용하는 단계가 많을수록 품질이 좋아지지만 단계가 많을수록 생성 시간이 길어진다. (기본=50)
guidance_scale : 프롬프트에 비슷한 정도, 보통 7~15를 씀, 너무 올리면 깨기도 함
gfpgan : 얼굴 보정웹툰, 애니메이션 등 주제 확장이 쉬운 Stable Diffusion
Stable Diffusion의 장점으로는 AI 주제 변경이 용이하다는 것. 미리 학습된 기계 학습 모델을 새로운 데이터셋에 맞게 조정하여 높은 성능을 내는 Fine Tuning기법을 적용하면 주제 확장에 용이하다. 추가적인 사진을 포함하여 모델을 학습시키면 해당 주제를 생성하는 데 이용할 수 있다.
마치며
오늘은 stable diffusion의 간단한 원리와 많이 활용되는 이유 등에 대해 학습해보았다. 또한 코드를 통해 이미지를 생성하는 실습도 해보았는데, 앞으로 프롬프트 엔지니어링에 대해 더 공부해서 좋은 퀄리티의 이미지를 뽑아내보고 싶다.

좋은 정보 감사합니다! Stable Diffusion 관심많았는데 큰 도움이 되었어요!
저 질문드릴 게 하나 있습니다 ㅎㅎ
블로그에 아래 내용은 코드 어디서 설정하는 건가요?!
negative_prompt : 이미지에 묘사되지 말아야 하는 텍스트
seed : 시드에 따라 다양한 이미지 생성 (같은 프롬프트여도 시드가 다르면 이미지가 조금 달라짐)
num_inference_steps : 추론 단계의 수, 일반적으로 사용하는 단계가 많을수록 품질이 좋아지지만 단계가 많을수록 생성 시간이 길어진다. (기본=50)
guidance_scale : 프롬프트에 비슷한 정도, 보통 7~15를 씀, 너무 올리면 깨기도 함
gfpgan : 얼굴 보정