
오늘부터 ML 공부를 시작하려고 한다. 그 중 가장 유명한 도서인 [핸즈온 머신러닝]을 학습한 여정을 기록 할 것이다.
1장 한눈에 보는 머신러닝
1.1 머신러닝이란?
머신러닝은 데이터로부터 학습하도록 컴퓨터를 프로그래밍하는 과학(또는 예술)이다.
조금 더 일반적인 정의는 다음과 같다.
머신러닝은 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야다.
-
훈련 세트 (training set) : 시스템이 학습하는 데 사용하는 샘플
-
훈련 사례/샘플 (training instance) : 각 훈련 데이터
-
정확도 (accuracy) : 성능 측정에 사용
-
데이터 마이닝 (data mining) : 머신러닝 기술을 적용해서 대용량의 데이터를 분석하여 겉으로 보이지 않던 숨은 패턴을 발견하는 것
1.3 머신러닝 시스템의 종류
1.3.1 지도학습과 비지도학습
지도학습(Supervised learning)
지도학습에는 알고리즘이 주입하는 훈련 데이터에 레이블(label)이라는 원하는 답이 포함된다.
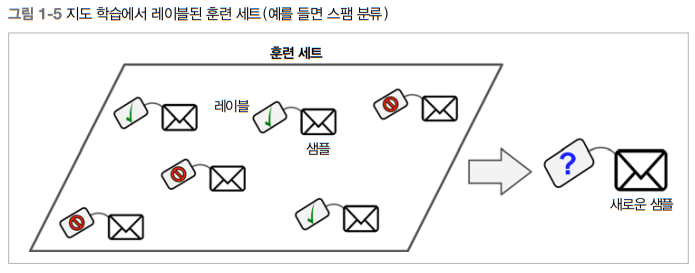
-
분류(classification) 가 전형적인 지도 학습 작업
스팸 필터가 분류의 좋은 예시 -
또 다른 전형적인 작업은 예측 변수(predictor variable)라 부르는 특성(feature) (주행 거리, 연식, 브랜드 등)을 사용해 중고차 가격 같은 타깃 수치를 예측하는 것
-
이런 종류의 작업을 회귀(regression) 라 부름
-
머신러닝에서 속성 (attribute)은 데이터 타입(ex: 주행거리)을 말한다.
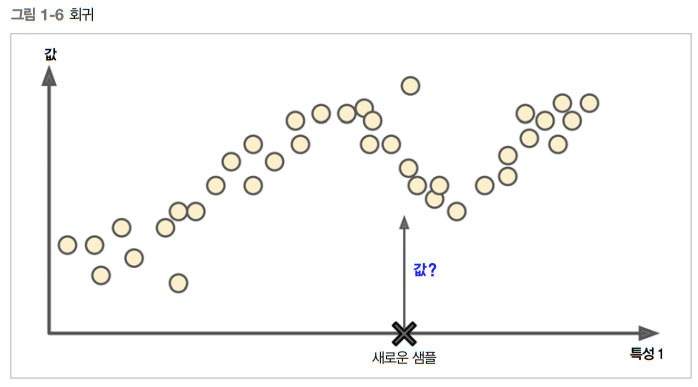
- 분류에 널리 쓰이는 로지스틱 회귀는 클래스에 속할 확률을 출력한다. (ex: 스팸일 가능성 20%)
지도학습 알고리즘들
-
K-최근접 이웃 (K-Nearest Neighbors)
-
선형 회귀 (Linear Regression)
-
로지스틱 회귀 (Logistic Regression)
-
서포트 벡터 머신 (Support Vector Machines:SVM)
-
결정 트리 (Decision Tress)와 랜덤 포레스트 (Random Forests)
-
신경망 (Neural networks)
