[우아한 스터디] RAG 성능을 끌어올리는 Pre-Retrieval (Ensenble Retriever) 와 Post-Retrieval (Re-Rank)
[우아한 스터디] 2024 여름시즌
RAG (Retrieval-Augmented Generation)
RAG 는 'Retrieval-Augmented Generation' 즉 '검색-증강 생성' 의 약자로,
검색과 생성의 특성을 모두 갖습니다.
가장 간단한 예시로는 PDF 문서 파일을 읽어들인 뒤, LLM에 문서에 대한 질의를 하면 문서 내용을 참고하여 답변하는 챗봇이 있습니다.
Pre-Retrieval (Ensenble Retriever)
EnsembleRetriever는 여러 retriever를 입력으로 받아 get_relevant_documents() 메서드의 결과를 앙상블하고, Reciprocal Rank Fusion 알고리즘을 기반으로 결과를 재순위화합니다.
서로 다른 알고리즘의 장점을 활용함으로써, EnsembleRetriever는 단일 알고리즘보다 더 나은 성능을 달성할 수 있습니다.
가장 일반적인 패턴은 sparse retriever (예: BM25)와 dense retriever (예: embedding similarity)를 결합하는 것인데, 이는 두 retriever의 장점이 상호 보완적이기 때문입니다. 이를 "hybrid search" 라고도 합니다.
Sparse retriever는 키워드를 기반으로 관련 문서를 찾는 데 효과적이며, dense retriever는 의미적 유사성을 기반으로 관련 문서를 찾는 데 효과적입니다.
출처 : 03. 앙상블 검색기(EnsembleRetriever)
일단, Retriever는 크게 두 가지 유형으로 나눌 수 있습니다:
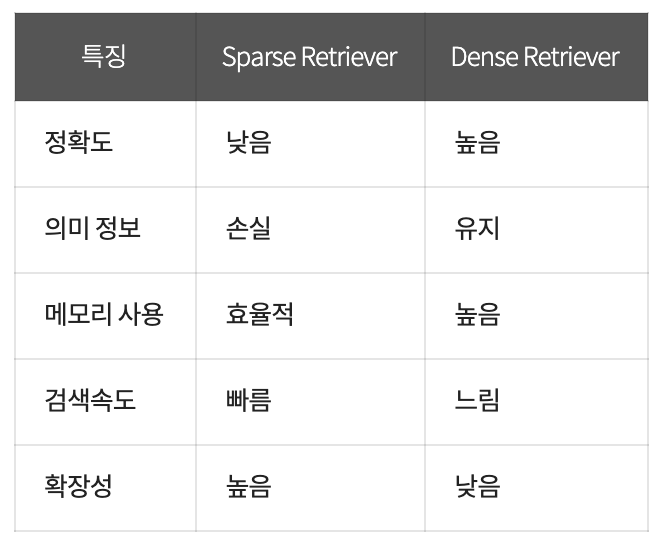
- Sparse Retriever:
TF-IDF와 같은 기술을 사용하여 텍스트 데이터를 희소 벡터로 변환하고, 질의 벡터와의 유사성에 따라 문서를 검색합니다. - Dense Retriever:
BERT와 같은 신경망 모델을 사용하여 텍스트 데이터를 밀집 임베딩 벡터로 변환하고, 질의 벡터와의 유사성에 따라 관련 문서를 검색합니다.
두 가지 Retriever 유형은 각각의 장단점이 있으며, 검색 작업의 요구에 따라 선택해야 합니다.
Sparse와 Dense Retriever를 결합하여 각 방식의 장점을 모두 활용한 Ensenble Retriever 방법을 사용하여 검색 효율성을 최적화할 수 있습니다.
[Sparse Retriever와 Dense Retriever 비교]
Sparse와 Dense Retriever를 결합하여 각 방식의 장점을 모두 활용한 Ensenble Retriever 방법을 사용하여 검색 효율성을 최적화할 수 있습니다.
출처 : [OpenLLM] Pre-Retrieval (Ensenble Retriever) , Post-Retrieval 기반의 Gemma Chatbot
Code
def setup_pdf_retriever(self, pdf_file_path: str):
"""PDF 파일을 읽어들여 리트리버를 설정합니다."""
# PDF 파일 로드
pages = PyMuPDFLoader(file_path=pdf_file_path).load()
# 문서 분할
docs = self.text_splitter.split_documents(pages)
# 문장을 임베딩으로 변환하고 벡터 저장소에 저장
embeddings = HuggingFaceEmbeddings(
model_name='jhgan/ko-sroberta-nli',
model_kwargs={'device':'cpu'},
encode_kwargs={'normalize_embeddings':True}
)
# FAISS 벡터 스토어 생성
vectorstore_faiss = FAISS.from_documents(docs, embeddings)
# BM25 리트리버 생성 (Sparse Retriever)
bm25_retriever = BM25Retriever.from_documents(docs)
# FAISS 리트리버 생성 (Dense Retriever)
faiss_retriever = vectorstore_faiss.as_retriever(search_kwargs={'k': 5})
# 앙상블 리트리버 생성
self.retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever],
weights=[0.5, 0.5] # 가중치 설정 (가중치의 합은 1.0)
)
# 답변 생성을 위한 프롬프트 템플릿 설정
template = '''Answer the question based only on the following context:
{context}
Question: {question}
'''
self.prompt = ChatPromptTemplate.from_template(template)
self.rag_chain = (
{"context": self.retriever | self.format_docs, "question": RunnablePassthrough()}
| self.prompt
| self.model
| StrOutputParser()
)
self.rag_chain.invoke(query)
Post-Retrieval (Re-Rank)
최근 RAG 에는 'Lost in Middle' 문제가 있는데요,
질문에 대한 관련 문서가 컨텍스트 중간에 위치할 경우, LLM 응답 정확도가 낮아지는 현상입니다.
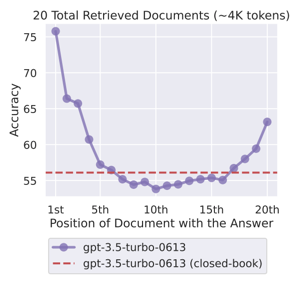
따라서 RAG의 성능을 향상 시키기 위해서는 질문에 대한 관련 문서가 컨텍스트에 존재 할 뿐만 아니라, 컨텍스트 내에서 그 순서 또한 상위권에 위치하고 있어야 함을 알 수 있었습니다. 이에 대한 해결책으로 Reranker를 사용할 수 있습니다.
Reranker는 질문과 문서 사이의 유사도를 측정하는 것을 목표로 합니다. 이것은 기존의 벡터 검색의 목적과 동일합니다. 하지만 질문과 문서에 대한 독립적인 임베딩을 활용하는 Bi-encoder 형태 (그림 2-a)의 벡터 검색과는 다르게 Reranker는 질문과 문서를 하나의 인풋으로 활용하는 Cross-encoder 형태 (그림 2-b)라는 점에서 차이를 보이고 있습니다. 즉, Reranker는 질문과 문서를 동시에 분석 (Self-attention) 함으로써, 독립적인 임베딩 벡터 기반의 Bi-encoder 방식에 비해 더욱 정확한 유사도 측정이 가능하다는 장점을 가지고 있습니다. 우리는 이러한 장점을 활용하여 질문-문서 사이의 관련성을 더욱 정교하게 측정할 수 있습니다.
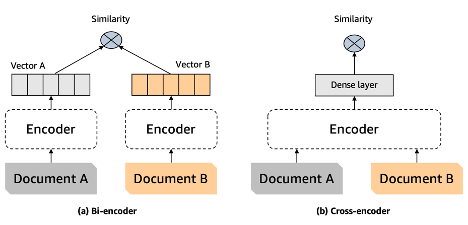
출처 : 한국어 Reranker를 활용한 검색 증강 생성(RAG) 성능 올리기
Code
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, similarity_retriever], weights=[0.5, 0.5])
rerank_model = HuggingFaceCrossEncoder(model_name="Dongjin-kr/ko-reranker") #reranker모델 로드
compressor = CrossEncoderReranker(model=rerank_model, top_n=3) # 가져오고자 하는 청크의 갯수를 top_n에 기입
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=ensemble_retriever)
compressed_docs = compression_retriever.invoke("What is the plan for the economy?")
pretty_print_docs(compressed_docs)출처 : [OpenLLM Study] LLama3 기반 RAG 및 Chatbot(Streamlit) 구축 (Ensemble + ReRank)
출처 : Cross Encoder Reranker
Reference
https://devocean.sk.com/internal/board/viewArticleForAjax.do?id=166148
