[우아한 스터디] 2024 여름시즌
1.[우아한 스터디] Kick-OFF

운 좋게 올해 여름 시즌 '우아한 스터디' 에 합격했다!나는 '기술 블로거 모여라' 스터디를 함께 하게 되었는데프론트엔드, 백엔드, 데이터분석 등 다양한 백그라운드를 가진 분들과 함께 스터디를 하게 되어다른 직군의 이야기를 듣고 시야를 넓힐 수 있는 기회가 될 것 같고
2.[우아한 스터디] LLM(LLaMA3) Fine-Tuning 방법 정리

LLM 파인튜닝을 위한 라이브러리를 정리합니다. 본 포스팅의 예제 코드는 GitHub 을 참고해 주세요. TRL Huggingface TRL Document HuggingFace 에서 제공하는 모델 튜닝 라이브러리로 TRL(Transformer Reinforceme
3.[우아한 스터디] LLM 생성모델 평가방법
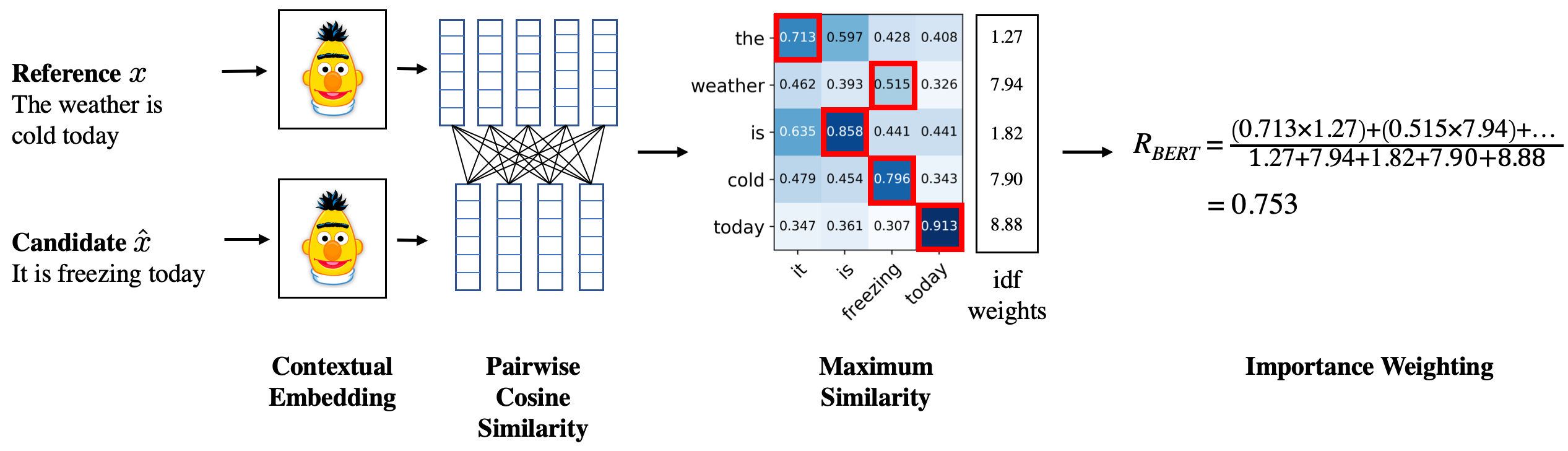
최근 LLM이 가장 많이 쓰이는 태스크는 단연 '생성' 일 텐데요, LLM과 함께 쓰이는 RAG 가 'Retrieval-Augmented Generation' 즉 '검색-증강 생성' 의 약자임을 보아도 알 수 있습니다. 예전부터 생성 태스크에서 가장 어려운 점은 '평
4.[우아한 스터디] RAG 성능을 끌어올리는 Pre-Retrieval (Ensenble Retriever) 와 Post-Retrieval (Re-Rank)

RAG 는 'Retrieval-Augmented Generation' 즉 '검색-증강 생성' 의 약자로,검색과 생성의 특성을 모두 갖습니다.가장 간단한 예시로는 PDF 문서 파일을 읽어들인 뒤, LLM에 문서에 대한 질의를 하면 문서 내용을 참고하여 답변하는 챗봇이 있
5.[우아한 스터디] OpenAI Chat Completions API 로 Ollama 사용하기
가장 먼저 ollama 홈페이지에 방문하여 ollama 를 설치합니다. https://ollama.com/ Setup ollama 에서 사용할 모델을 pull 합니다. ` Basic Code 다음은 Ollama 공식 블로그에서 제공하는 Ollama 와 OpenAI
6.[우아한 스터디] Unsloth 를 이용한 Fine-Tuning
🦥Unsloth makes fine-tuning of LLMs 2.2x faster and use 80% less VRAM! 본 튜토리얼 포스팅은 테디노트 튜토리얼 위주로 설명하며, Unsloth 공식 튜토리얼 중 Llama3 와 비교하여 차이점을 주석으로 달았습니
7.[우아한 스터디] (작성중) AutoRAG : 자동으로 RAG 최적화 파이프라인을 찾아주는 툴
🤷♂️ 왜 AutoRAG인가?수많은 RAG 파이프라인과 모듈들이 존재하지만, "자신의 데이터"와 "자신의 사용 사례"에 적합한 파이프라인이 무엇인지 알기란 쉽지 않습니다.모든 RAG 모듈을 만들고 평가하는 것은 매우 시간이 많이 걸리고 어렵습니다. 그러나 이렇게 하
8.[우아한 스터디] RAGAS : RAG 파이프라인 평가 프레임워크
공식문서GitHubRagas 주요 성능 메트릭을 살펴보면 크게 Retrieval, Generation 각 카테고리 별 측면에서 메트릭을 정의할 수 있습니다.Retrieval 은 정확하고 일관성 있는 답변 생성을 위해 정확성, 정밀성, 관련성 측면에서 좋은 품질의 Con