최근 LLM이 가장 많이 쓰이는 태스크는 단연 '생성' 일 텐데요,
LLM과 함께 쓰이는 RAG 가 'Retrieval-Augmented Generation' 즉 '검색-증강 생성' 의 약자임을 보아도 알 수 있습니다.
예전부터 생성 태스크에서 가장 어려운 점은 '평가' 였고, LLM 기반 생성 모델 또한 그 성능을 평가하기란 쉬운 일이 아닙니다.
이번 스터디에서는 LLM 생성모델 평가 방법 4가지를 비교합니다.
본 포스팅은 테디노트 강의 'EP03. LLM의 답변을 평가할 수 있는 4가지 방법 [#AutoRAG 라이브 편집본]' 을 요약한 내용입니다.
Generation 지표 이해하기
AutoRAG 는 다음 4가지 지표 중 몇 가지를 함께 사용하여 성능을 평가합니다.
1. N-gram based metrics
- 전통적인 NLP 지표
- 모범 답안을 만들어두고 답안과 단어적으로 얼마나 비슷한지 비교
- 매우 싸고 빠름
- 긴 답변에서 정확하지 않은 편
- 응답이 짧을 때 좋음
- 제대로 활용하려면 많은 ground truth가 필요
- METEOR, BLEU, ROUGE
- LLM보다 훨씬 빠르고 싸고 나쁘지 않다 (특히 ROUGE)
- 그러나 METEOR, BLEU, ROUGE 3가지 모듈의 순위가 뒤죽박죽일 경우 (=의견이 갈릴 경우) LLM-based metric 을 써서 순위를 확실하게 하고 비용을 절감한다.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- 생성 태스크에서 주로 사용되는 평가 지표 (번역, 요약 등)
- n-gram recall
- 정답 문장의 n-gram이 생성 문장에 얼마나 포함되는지의 비율
[NLP]Rouge score - Summarization의 평가 Metric
Code (영어)
(Rouge score 는 알파벳과 숫자를 제외한 나머지 문자를 제거합니다.)
pip install rouge-scorefrom rouge_score import rouge_scorer
# 예시 요약 문장
candidate_summary = "I like ChaEunWoo"
# 예시 원본 요약 문장
reference_summary = "I love ChaEunWoo"
# ROUGE 스코어 계산을 위한 scorer 객체 생성
scorer = rouge_scorer.RougeScorer(['rouge1', 'rougeL'], use_stemmer=True)
# ROUGE 스코어 계산
scores = scorer.score(reference_summary, candidate_summary)
# 결과 출력
print(scores)[Output]
{'rouge1': Score(precision=0.6666666666666666, recall=0.6666666666666666, fmeasure=0.6666666666666666), 'rougeL': Score(precision=0.6666666666666666, recall=0.6666666666666666, fmeasure=0.6666666666666666)}
Code (한국어)
https://github.com/HeegyuKim/korouge
pip install korouge_scorefrom korouge_score import rouge_scorer
scorer = rouge_scorer.RougeScorer(["rouge1", "rouge2", "rougeL", "rougeLsum"])
ref = "나는 차은우를 좋아해"
pred = "나는 차은우를 사랑해"
print(scorer.score(ref, pred))[Output]
{'rouge1': Score(precision=0.6666666666666666, recall=0.6666666666666666, fmeasure=0.6666666666666666), 'rouge2': Score(precision=0.5, recall=0.5, fmeasure=0.5), 'rougeL': Score(precision=0.6666666666666666, recall=0.6666666666666666, fmeasure=0.6666666666666666), 'rougeLsum': Score(precision=0.6666666666666666, recall=0.6666666666666666, fmeasure=0.6666666666666666)}
2. LM-based metrics
- 빠르고 쌈 => BERT 모델 이용
- BERT-score
- BERT 같은 작은 LM을 이용해 의미론적으로 얼마나 비슷한지 측정
- LLM 이용이 힘든 경우 대안으로 사용 가능
BERT-Score
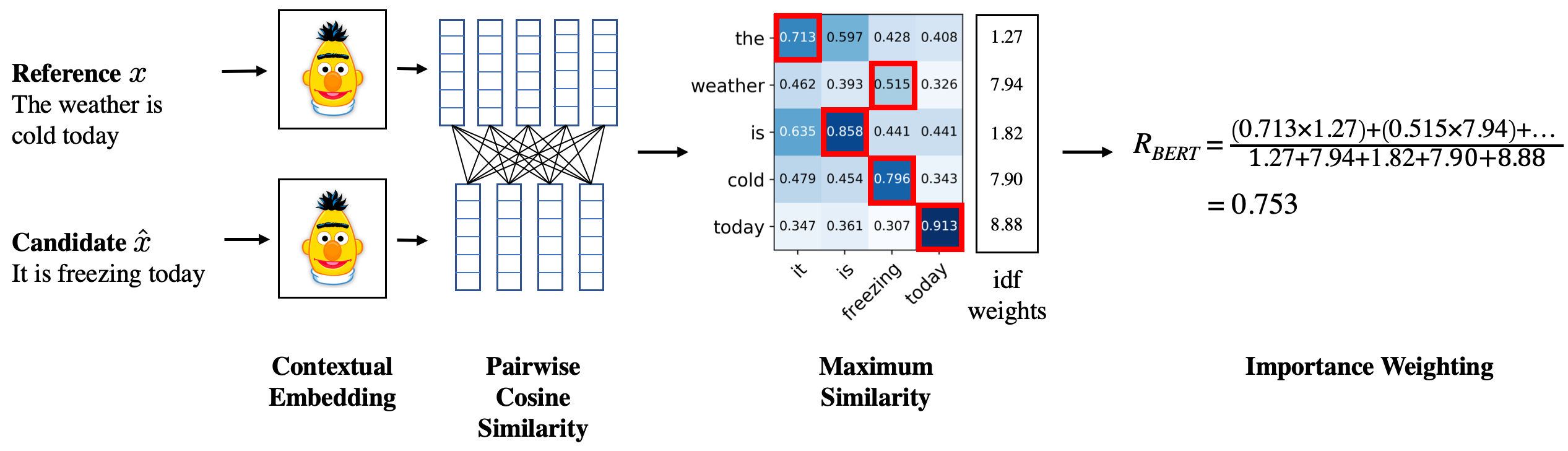
- BERT의 Contexutal Embedding을 활용해 두 문장의 유사도 측정
Code
from transformers import BertTokenizer, BertModel
import torch
from scipy.spatial.distance import cosine
# BERT 모델과 토크나이저 불러오기
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
model = BertModel.from_pretrained('bert-base-multilingual-cased')
def get_bert_embeddings(sentence, tokenizer, model):
# 문장을 토큰화하고 BERT 입력 형식으로 변환
inputs = tokenizer(sentence, return_tensors='pt', padding=True, truncation=True)
# BERT 모델을 통해 문장의 임베딩 얻기
with torch.no_grad():
outputs = model(**inputs)
embeddings = torch.mean(outputs.last_hidden_state, dim=1).squeeze(0)
return embeddings.numpy()
def calculate_bert_score(sentence1, sentence2, tokenizer, model):
# 각 문장의 BERT 임베딩 벡터 얻기
embedding1 = get_bert_embeddings(sentence1, tokenizer, model)
embedding2 = get_bert_embeddings(sentence2, tokenizer, model)
# 코사인 유사도 계산 (1 - cosine distance)
score = 1 - cosine(embedding1, embedding2)
return score
# 입력 문장 받기
sentence1 = "나는 차은우를 좋아해"
sentence2 = "나는 차은우를 사랑해"
# BERT-score 계산
bert_score = calculate_bert_score(sentence1, sentence2, tokenizer, model)
print(f"두 문장의 BERT-score: {bert_score}")
두 문장의 BERT-score: 0.8905486464500427
참고로 위 코드와 같이 Multilingual BERT 를 사용할 경우 언어가 달라도 score 를 구할 수 있다.
sentence1 = "I love 차은우"
sentence2 = "J'aime 차은우"두 문장의 BERT-score: 0.942416250705719
BERT_score 라이브러리 사용 예제
https://github.com/Tiiiger/bert_score
이미 공개된 BERT-score 를 이용하면 다량의 텍스트 파일도 한번에 BERT-score 를 구할 수 있다.
pip install bert-score영어 텍스트 파일 BERT-score 예제
bert-score -r example/refs.txt -c example/hyps.txt --lang en1:1 문장 쌍 BERT-score 예제
!bert-score --lang ko -r "나는 차은우를 좋아해" -c "나는 차은우를 사랑해"[Output]
bert-score-show --lang en -r "There are two bananas on the table." -c "On the table are two apples." -f out.png
3. Sem Score
- 의미론적 유사성을 비교하기 위해 임베딩 모델 사용
- LLM 이 생성한 답변과 원래 모범 답안 2개를 임베딩하여 Cosine similarity 비교
- 영어 데이터에서 높은 성능
- 영어 기반의 경우 LLM 메트릭보다도 사람과의 유사성이 더 높았다 (더 인간의 평가에 가까웠다)
- LLM-based metric 을 제외하면 가장 괜찮은 평가 방법.
- 특정 도메인 데이터에 사용하기 어려움
- 한국어 임베딩 모델이 없다면 사용하기 힘들다
- LLM을 사용할 수 없는 한국어 평가의 경우 한국어 BERT 사용 추천
- (한국어) BERT-score + ROUGE/METEOR 결합하여 사용 추천
Cosine Similarity
- 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도
- -1 부터 1 이하의 값을 가짐
- 두 벡터의 방향이 완전히 동일한 경우에는 1
- 즉, 두 문장이 완전히 일치하면 cosine similarity = 1
- 두 벡터의 방향이 180°로 반대의 방향을 가지면 -1
- 두 벡터의 방향이 완전히 동일한 경우에는 1
Code
from transformers import AutoTokenizer, AutoModel
import torch
from sklearn.metrics.pairwise import cosine_similarity
# KoBERT 모델과 토크나이저 불러오기
tokenizer = AutoTokenizer.from_pretrained("kykim/bert-kor-base")
model = AutoModel.from_pretrained("kykim/bert-kor-base")
def get_sentence_embedding(sentence, tokenizer, model):
# 문장을 토크나이즈하고 토큰 ID로 변환
input_ids = tokenizer.encode(sentence, return_tensors='pt')
# KoBERT 모델에 입력하고 문장 임베딩 얻기
with torch.no_grad():
outputs = model(input_ids)
sentence_embedding = torch.mean(outputs.last_hidden_state, dim=1)
# 평균 풀링을 통해 문장의 임베딩 벡터를 얻습니다.
return sentence_embedding.numpy()
def cosine_similarity_two_sentences(sentence1, sentence2, tokenizer, model):
# 각 문장의 임베딩 벡터를 얻습니다.
embedding1 = get_sentence_embedding(sentence1, tokenizer, model)
embedding2 = get_sentence_embedding(sentence2, tokenizer, model)
# 코사인 유사도 계산
similarity = cosine_similarity(embedding1, embedding2)[0][0]
return similarity
# 입력 문장 받기
sentence1 = "나는 차은우를 좋아해"
sentence2 = "나는 차은우를 사랑해"
# 코사인 유사도 계산
similarity_score = cosine_similarity_two_sentences(sentence1, sentence2, tokenizer, model)
print(f"두 문장의 코사인 유사도: {similarity_score}")두 문장의 코사인 유사도: 0.8624602556228638
4. LLM-based metrics
- 비쌈 => LLM 모델을 사용
- 도메인 데이터에 프롬프트를 직접 작성해 커스텀해서 사용 가능
- (한국어 가능 LLM 사용 시) 한국어에 적용 용이
- GPT-4 급의 성능을 가진 LLM 을 사용하면 높은 성능
- (사용할 여유가 되면) 가장 정확한 성능
- g-Eval
g-Eval (Gist-Based Evaluation Metric)
- Chain-of-Thought(CoT)와 양식 채우기(form-filling) 패러다임을 활용하여 대규모 언어모델을 통해 생성 결과물의 품질을 평가
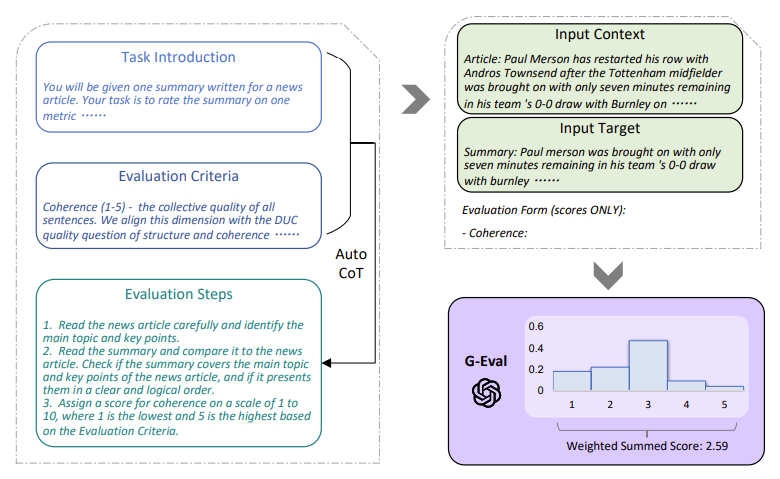
- 주요 구성요소 (3가지)
- 1) 평가하고자 하는 태스크에 대한 설명과 평가 기준에 대한 프롬프트
- 2) CoT - LLM이 생성한 세부 중간 평가 단계
- 3) Scoring function - 아웃풋 확률 값에 기반하여 최종 평가 점수를 계산
Reference
