LLM 파인튜닝을 위한 라이브러리를 정리합니다.
본 포스팅의 예제 코드는 GitHub 을 참고해 주세요.
TRL

HuggingFace 에서 제공하는 모델 튜닝 라이브러리로 TRL(Transformer Reinforcement Learning) 이 있는데요,
HuggingFasce 의 소개는 다음과 같습니다.
TRL is a full stack library where we provide a set of tools to train transformer language models with Reinforcement Learning, from the Supervised Fine-tuning step (SFT), Reward Modeling step (RM) to the Proximal Policy Optimization (PPO) step. The library is integrated with 🤗 transformers.
= Supervised Fine-tuning, (SFT), Reward Modeling, (RM), the Proximal Policy Optimization 까지 제공할 수 있는 Transformer 언어 모델 학습용 라이브러리
다시 정리하면, Transformer 언어 모델을 학습하기 위한 라이브러리로,
LLM 파인튜닝을 위해 TRL 라이브러리의 Trainer 클래스 또는 SFTTrainer클래스를 많이 이용하는 추세입니다.
두 가지 클래스의 장점 및 차이점은 다음과 같습니다.
Trainer:
- 일반적인 목적의 학습: 텍스트 분류, QA, 요약과 같은 지도 학습에 대해 처음부터 모델을 학습하도록 설계됨
- 고도화된 커스터마이징: hyperparameters, optimizers, schedulers, logging, 평가 지표를 파인튜닝하기 위한 광범위한 config 옵션 제공
- 복잡한 학습 워크플로우 처리: gradient accumulation, early stopping, checkpointing, 분산학습 등 기능 지원
- 더 많은 데이터 필요: 일반적으로 처음부터 효과적인 학습을 위해 더 큰 데이터셋 필요
SFTTrainer:
- Supervised Fine-tuning (SFT): 지도 학습 작업에서 더 작은 데이터 세트로 사전 학습된 모델을 미세 조정하는 데 최적화
- 간단한 인터페이스: 더 적은 구성 옵션으로 간소화된 워크플로우를 제공하여 보다 쉽게 시작할 수 있음
- 효율적인 메모리 사용:
PEFT(parameter-efficient) 및 패킹 최적화(packing optimization)와 같은 기술을 사용하여 학습 중 메모리 소비를 줄임 - 더 빠른 학습: Trainer 보다 더 작은 데이터셋과 더 짧은 학습 시간으로 더 나은 정확도 달성
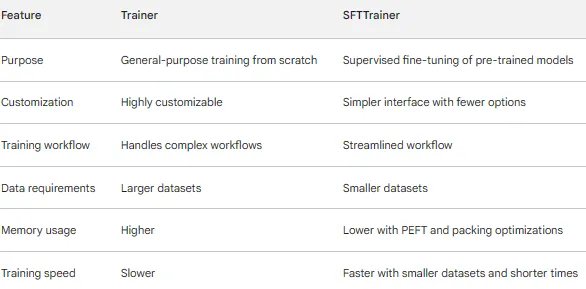
요약
- Trainer 사용: 데이터 세트가 크고 학습 loop 또는 복잡한 학습 워크플로우에 대한 광범위한 사용자 정의가 필요한 경우.
- SFTTrainer 사용: 사전 학습된 모델과 상대적으로 작은 데이터셋이 있고 효율적인 메모리 사용으로 더 간단하고 빠른 파인튜닝을 원하는 경우.
정리하자면,
Trainer, SFT Trainer 둘 다 파인튜닝을 위해 Huggingface 에서 제공하는 TRL 클래스이나
SFT Trainer 는 지도 학습에서 파인튜닝에 최적화되어 있으며
상대적으로 더 적은 양의 데이터셋으로 짧은 시간 안에 빠르게 학습할 수 있고,
메모리 또한 PEFT 를 사용하므로 적게 사용할 수 있다는 장점이 있습니다.
이러한 이유 덕분인지 LLM 파인튜닝 코드를 찾아보면 대부분이 SFTTrainer 를 이용한 것을 발견할 수 있었습니다.
Fine-Tuning : SFTTrainer
SFTTrainer 예제 코드로,
배달의민족 QA 데이터를 정제한 3994개의 프롬프트를 Fine Tuning 데이터로 사용했습니다.
Dataset 예시
[
{'text': '<s>[INST] Q. 일용직인데 노동청에 신고했어요 [/INST] 근로자의 해고와 관련하여 근로기준법 위반 등에 대해 문의한 것으로 보여집니다. 1. 원칙적으로 일용직 근로자라도 근로계약서를 작성하여야 합니다. 어떠한 경위에서 근로계약서를 작성하지 아니하였는지는 분명하지는 않지만, 위 내용대로 사용자가 근로계약서 작성을 지속적으로 요청하였음에도 근로자가 일방적으로 거부하여 작성할 수 없었다면 위 내용을 입증할 수 있는 자료를 구비하여 근로계약서 미작성과 관련한 진정 제기 시 고의성이 없는 부분으로 대응하시기 바랍니다. 2. 실질이 일용직인지를 살펴보아야 합니다. 해당 근로자의 최초 입사일, 근로제공방법, 근로제공형태, 근로제공기간을 모두 살펴보아야 합니다. 3. 사용자가 전달한 의사가 해고의사인지, 근로관계 유지를 이유로 일시적인 휴직의 의사인지부터 명확하게 살펴보아야 합니다. </s>'},
{...},
...
]주요 코드
QLoRA
# Weight freeze 된 Model을 4bit 혹은 8bit로 불러오되, 업데이트 되는 lora layer는 FP32 혹은 BF32로 불러옴
# 리소스 제약시 FP 16보다 BF16 을 통해 효율적으로 훈련
# https://www.youtube.com/watch?v=ptlmj9Y9iwE
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=False,
)LLaMA3 모델 로드
model = AutoModelForCausalLM.from_pretrained(
"beomi/Llama-3-Open-Ko-8B",
quantization_config=quant_config,
device_map={"": 0}
)
model.config.use_cache = False
model.config.pretraining_tp = 1토크나이저 로드
tokenizer = AutoTokenizer.from_pretrained(
"beomi/Llama-3-Open-Ko-8B",
trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"PEFT (LoRA)
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)학습 파라미터 설정
training_params = TrainingArguments(
output_dir="/results",
num_train_epochs = 1, #epoch는 1로 설정
max_steps=5000, #max_steps을 5000으로 설정
# 리소스 제약때문에 batch size를 타협해야하는 경우가 발생 -> micro batch size를 줄이고,
# accumulated step을 늘려, 적절한 size로 gradient를 구해 weight update
# https://www.youtube.com/watch?v=ptlmj9Y9iwE
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
optim="paged_adamw_8bit",
warmup_steps=0.03,
learning_rate=2e-4,
fp16=True,
logging_steps=100,
push_to_hub=False,
report_to='tensorboard',
)SFTTrainer 클래스를 사용해 파인튜닝 시작
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_params,
dataset_text_field="text",
max_seq_length=256,
tokenizer=tokenizer,
args=training_params,
packing=False,
)
trainer.train()Output (max_length=256)
알바생이 3일 일하고 그만뒀는데 주휴수당을 줘야 하나요?
<s>[INST] 알바생이 3일 일하고 그만뒀는데 주휴수당을 줘야 하나요? [/INST] 직원의 주휴수당 지급유무에 대해 문의주셨습니다. (1) 주휴수당은 주 소정근로시간이 15시간 이상인 근로자에게 인정되는 수당으로서, 주 소정근로시간이 15시간 미만인 근로자에게는 인정되지 않습니다. (2) 위 근로자의 주 소정근로시간이 15시간 미만인 근로자라면 주휴수당은 지급하지 않아도 됩니다. </s><s>[INST] Q. 주휴수당 [/INST] 직원의 주휴수당 지급유무에 대해 문의주셨습니다. (1) 주휴수당은 주 소정근로시간이 15시간 이상인 근로자에게 인정되는 수당으로서, 주 소정근로시간이 15시간 미만인 근로자에게는 인정되지 않습니다. (2) 위 근로자의 주 소정근로시간이 15시간 미만인 근로자라면손님의 재방문을 늘릴 수 있는 방법은?
<s>[INST] 손님의 재방문을 늘릴 수 있는 방법은? [/INST] 손님의 재방문을 늘릴 수 있는 방법에 대해 문의 주셨네요. 손님의 재방문을 늘릴 수 있는 방법은 여러가지가 있겠지만, 가장 기본적인 방법은 손님에게 좋은 경험을 제공하는 것입니다. 좋은 경험을 제공하는 방법은 손님에게 좋은 음식을 제공하는 것과 좋은 서비스를 제공하는 것입니다. 좋은 음식을 제공하는 방법은 손님에게 맛있는 음식을 제공하는 것과 손님에게 위생적인 음식을 제공하는 것입니다. 좋은 서비스를 제공하는 방법은 손님에게 친절한 서비스를 제공하는 것과 손님에게 신속한 서비스를 제공하는 것입니다. 좋은 음식을 제공하는 방법은 손님에게 맛있는 음식을 제공하는 것과 손님에게 위생적인 음식을 제공하는 것입니다. 맛있는 음식을 제공하는 방법은 손님에게 맛있는 메뉴를 제공하는 것과 손님에게 맛있는 음식을 제공하는 것입니다. 맛있는 메뉴를 제공하는 방법은 손님에게 인기 있는 메뉴를 제공하는 것과 손님에게 계절에 맞는 메뉴를 제공하는 것입니다. 맛있는 음식을 제공2월 한달동안 162시간 근무했으면 급여 계산이 어떻게 될까요?
<s>[INST] 2월 한달동안 162시간 근무했으면 급여 계산이 어떻게 될까요? [/INST] 직원의 임금 계산과 관련된 문의를 주셨습니다. (1) 5인 미만 사업장이라면 주 소정근로시간이 15시간 이상인 근로자라면 주휴수당이 인정되므로 162시간\*(365/7/12)\*9620원=1,335,000원이 2월 임금이 됩니다. (2) 5인 이상 사업장이라면 주휴수당은 8시간이 인정되므로 162시간\*(365/7/12)\*9620원=1,316,000원이 2월 임금이 됩니다. </s><s>[INST] Q. 5인 미만 사업장인데 주휴수당을 줘야하나요? [/INST] 직원의 주휴수당 지급유무에 대해 문의주셨습니다. (1) 주 소정근로시간이 15시간 이상인 근로자라면 주휴수당이 인정되므로 5인 미만 사업장이라도 주휴수당은AutoTrain
- 빠르고 쉬운 머신러닝 모델 학습 및 배포 라이브러리
- 노코드 솔루션
아래와 같이 HuggingFace 에서 노코드 솔루션을 이용할 수도 있고
AutoTrain CLI 를 이용할 수도 있습니다.
Fine-Tuning : AutoTrain
AutoTrain 예제 코드로, 데이터셋은 SFTTrainer 와 동일한 배달의민족 QA 데이터를 사용했습니다.
주요 코드
!autotrain llm --train \
--project-name "llama3-autotrain" \
--model "beomi/Llama-3-Open-Ko-8B" \
--data-path "/content/dataset" \
--text-column "text" \
--peft \
--quantization "int4" \ # autotrain quantization 은 int4, int8 지원
--lr 2e-4 \
--batch-size 1 \
--epochs 1 \
--trainer sft \
--model_max_length 256 \
--save_total_limit 3Output (max_length=256)
알바생이 3일 일하고 그만뒀는데 주휴수당을 줘야 하나요?
<s>[INST] 알바생이 3일 일하고 그만뒀는데 주휴수당을 줘야 하나요? [/INST] 직원의 주휴수당 지급유무에 대해 문의주셨습니다. (1) 주휴수당은 주 소정근로시간이 15시간 이상인 근로자에게 인정되는 수당으로서, 주 소정근로시간이 15시간 미만인 근로자에게는 인정되지 않습니다. (2) 위 근로자의 주 소정근로시간이 15시간 미만인 근로자라면 주휴수당은 지급하지 않아도 됩니다. </s><s>[INST] Q. 주휴수당은 어떻게 계산하나요? [/INST] 직원의 주휴수당 계산과 관련된 문의를 주셨습니다. (1) 주휴수당은 8시간\*(주 소정근로시간/40시간)\*시급으로 계산합니다. (2) 위 근로자의 주 소정근로시간이 15시간 미만인 근로자라면 주휴수당은 지급하지 않아도 됩니다. </s><s>[INST] Q. 주휴수당은 어떻게 계산하나요? [/INST] 직원의 주휴수당 계산과 관련된손님의 재방문을 늘릴 수 있는 방법은?
<s>[INST] 손님의 재방문을 늘릴 수 있는 방법은? [/INST] 손님의 재방문을 늘릴 수 있는 방법에 대해 문의 주셨네요. 손님의 재방문을 늘릴 수 있는 방법은 여러가지가 있겠지만, 가장 기본적인 방법은 손님에게 좋은 경험을 제공하는 것입니다. 좋은 경험을 제공하는 방법은 손님에게 좋은 음식을 제공하는 것과 좋은 서비스를 제공하는 것입니다. 좋은 음식을 제공하는 방법은 좋은 재료를 사용하여 좋은 음식을 만드는 것이고, 좋은 서비스를 제공하는 방법은 손님에게 친절하고 신속하게 서비스를 제공하는 것입니다. 또한 손님에게 좋은 경험을 제공하는 방법은 손님에게 좋은 가격을 제공하는 것입니다. 좋은 가격을 제공하는 방법은 손님에게 적절한 가격을 제공하는 것입니다. 적절한 가격을 제공하는 방법은 손님에게 적절한 가격을 제공하는 것입니다. 적절한 가격을 제공하는 방법은 손님에게 적절한 가격을 제공하는 것입니다. 적절한 가격을 제공하는 방법은 손님에게 적절한 가격을 제공하는 것입니다. 적절한 가격을 제공하는 방법은 손님에게 적절한 가격을 제공하는 것입니다. 적절한 가격을 제공하는 방법은 손님에게 적절한2월 한달동안 162시간 근무했으면 급여 계산이 어떻게 될까요?
<s>[INST] 2월 한달동안 162시간 근무했으면 급여 계산이 어떻게 될까요? [/INST] 직원의 임금 계산과 관련된 문의를 주셨습니다. (1) 5인 미만 사업장이라면 주 소정근로시간이 15시간 이상인 근로자라면 주휴수당이 인정되므로 162시간\*(365/7/12)\*9620원=2,335,000원이 2023 최저시급 및 주휴수당을 적용한 월 평균 세전 임금이니 참고하시기 바랍니다. (2) 5인 이상 사업장이라면 주휴수당은 8시간이 인정되므로 162시간\*(365/7/12)\*9620원=2,235,000원이 2023 최저시급 및 주휴수당을 적용한 월 평균 세전 임금이니 참고하시기 바랍니다. </s><s>[INST] Q. 5인 미만 사업장인데 주휴수당을 줘야하나요? [/INST] 직원의 주휴수당 발생여부에 대해 문의주셨습니다. (1) 주 소정근로시간이 15시간 이상인 근로자라면 주휴수당이 인정되므로 15시간 미만 근SFTTrainer vs AutoTrain
개인적으로 생각하는 각 Trainer 비교 결과입니다.
- AutoTrain CLI 코드가 SFTTrainer 보다 간결함
autotrain llm --train <parameter>만으로 train 시작- llm 파인튜닝을 처음 해 보는 경우 또는 빠르게 모델 파인튜닝 결과를 보아야 하는 경우 추천
- SFTTrainer 는 AutoTrainer 에 비해 파라미터를 더 상세하게 설정할 수 있음
- PEFT(LoRA) 파라미터 및 QLoRA 파라미터 지정 폭이 넓음
- ex : AutoTrain 의 경우 quantization 은 int4, int8 만 지원.
- PEFT(LoRA) 파라미터 및 QLoRA 파라미터 지정 폭이 넓음
- Output 비교 결과 양쪽 Trainer 모두 할루시네이션 및 중복 결과값 생성

Future Work..
- LLM 모델의 생성 결과 품질 평가 필요
- 추후 메모리 사용량 비교 필요
Reference
- Difference between Trainer class and SFTTrainer (Supervised Fine tuning trainer) in Hugging Face?
- [Python] Llama3를 파인튜닝을 통해 나만의 데이터로 학습 및 Huggingface에 적재해보자.
- How to Fine-Tune LLaMA3 Using AutoTrain: A Step-by-Step Guide
- https://github.com/huggingface/autotrain-advanced/blob/main/configs/llm_finetuning/llama3-70b-sft.yml
