올해 내내 백엔드 개발에 치중했더니 NLP 지식을 많이 까먹었어요 😂
새 회사에서는 기계번역 이외의 도메인을 다루는지라 당장 내가 할 수 있는 게 없었고
특히 올 한 해 동안 ChatGPT, LlaMa 와 같은 LLM 이 쏟아져 나오면서
NLP러로서의 미래에 대해 많은 고민을 하게 되었고요.
오랫동안 자아성찰하고 고민한 끝에 찾은 저만의 답은
'변화무쌍하고 예측할 수 없는 때일수록 기초를 다지자' 입니다.
기계번역이든 문서분류든 BERT든 LLM 이든 모두 기반 지식과 기술은 동일하고
또 기초가 탄탄하면 응용 기술을 익히고 활용하기에 수월하더라고요.
그래서인지 NLP 기술 면접에서 Transformer 그림을 주고 구조를 설명하도록 하는 경우도 있었네요 😂
이번 기회에 Transformer 를 다시 한 번 정리해 보겠습니다!
❖ 이 포스팅은 이기창님의 'Do it! BERT와 GPT로 배우는 자연어 처리' 저서를 참고하여 작성하였습니다.
https://ratsgo.github.io/nlpbook/docs/language_model/transformers/
https://www.yes24.com/Product/Goods/105294979
History
태초에 RNN 이 있었다
언어 모델의 원조는 역시 RNN 이죠.
Recursive Neural Network 의 약자로,
아래 그림과 같이 순환 구조를 가지고 있어 'Recursive' 라는 이름이 붙었지요.



https://aikorea.org/blog/rnn-tutorial-1/
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
Seq2Seq
RNN 이나 LSTM 을 쌓아서 각각 encoder 와 decoder 를 만들고,
이를 이어 붙여 문장 단위 태스크를 해결하는 Seq2Seq 이 나왔습니다!
Sequence to Sequence 란 '특정 속성을 지닌 시퀀스를 다른 속성의 시퀀스로 변환하는 작업' 을 가리킵니다.
(특히 최종적으로 알아볼 Transformer가 이 Sequence to Sequence 작업에 특화된 모델이고요.
그래서 문장 단위 작업인 기계번역에서는 반드시 Transformer 를 이용하지요.)
Sequence to Sequence 는 대개 encoder 와 decoder 로 구성됩니다.
- encoder : source 정보를 압축해 decoder 로 전달
- decoder : encoder 로부터 받은 정보와 현재 decoder 입력을 모두 고려하여 target sequence 생성
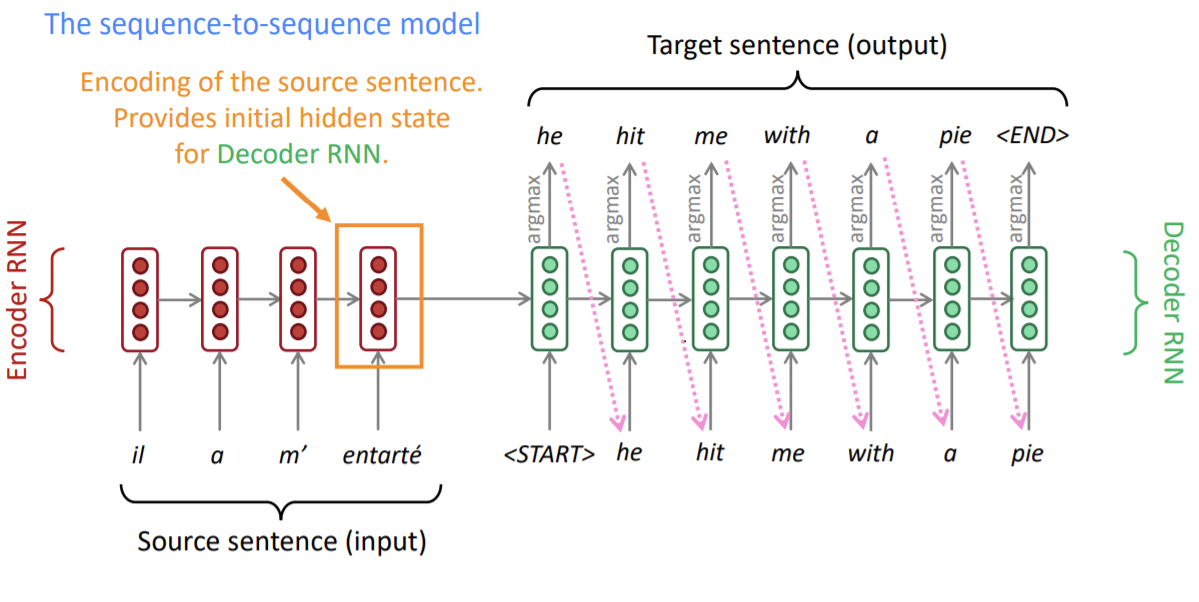
https://medium.com/analytics-vidhya/neural-machine-translation-using-bahdanau-attention-mechanism-d496c9be30c3
그러나 이 단순한 구조는 한계가 있었는데,
-
Long-term dependency (장기 의존성)
RNN 에서 발생하던 문제로, Seq2Seq 에서도 온전히 해결되지 않은 문제입니다.
Gradient descent 즉 기울기 소실로부터 나타나는 현상으로,
문장이 길어질 경우 앞 단어의 정보를 잃어버리는 현상입니다. -
Bottleneck (병목 현상)
인코더는 디코더로 정보(context) 를 전달할 때 하나의 문맥 벡터(context vector) 를 이용하는데,
결과적으로 하나의 벡터가 전체 문장을 인코딩 해야하는 부담을 가지게 됩니다.
이것이 병목현상입니다.
Attention
이 문제를 개선하기 위해 Attention Mechanism 이 등장하였으며
디코더가 인코더 입력 문장의 특정 범위(단어, 토큰)에 집중할 수 있도록 합니다.
좀더 쉽게 풀어서 설명하자면,
attention 은 디코더가 타깃 시퀀스를 생성할 때 인코더의 입력값인 소스 시퀀스 전체에서 어떤 요소에 주목해야 할지 알려주는 역할을 합니다.
(Attention은 디코더에서 출력 단어를 예측하는 매 시점마다 인코더에서의 전체 입력 문장을 다시 한 번 참고한다. 다만, 전체 입력 문장을 전부 동일한 비율로 참고하지 않고 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분에 더 집중(attention)해서 참고한다.)
https://cashew-nut.tistory.com/90
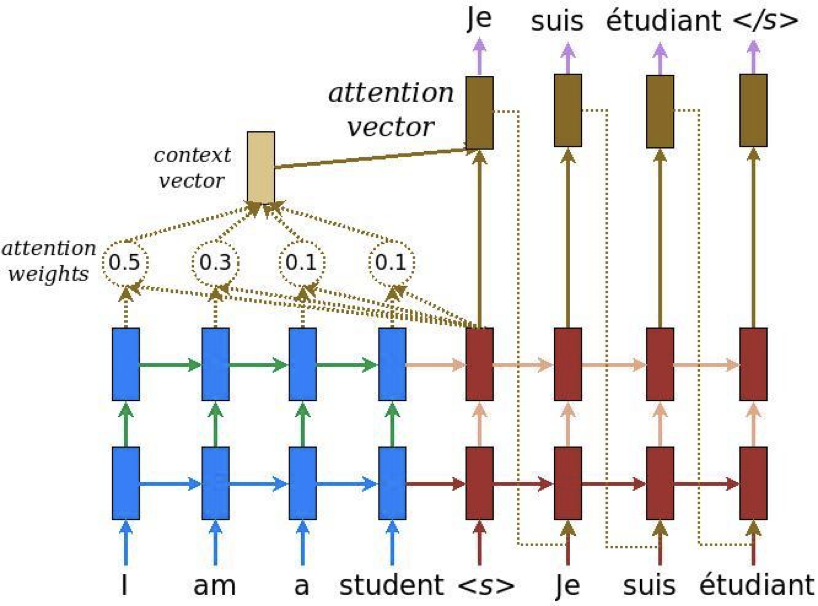
https://www.tensorflow.org/text/tutorials/nmt_with_attention
Transformer 는 이 attention 을 이용하여 만들어진 매우 혁신적인 모델입니다.
Transformer 의 가장 큰 특징은 'Self-Attention' 인데요,
어디에 어떻게 쓰였고, 일반 attention 과 비교하여 무엇이 다른지
다음 포스팅에서 살펴보겠습니다.
