NLP
1.LLaMA, (Ko)Alpaca, Dalai (!)
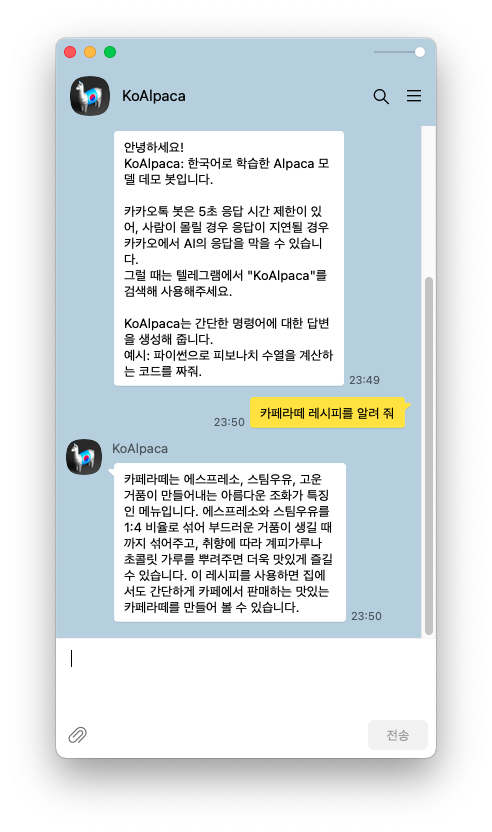
요즘 LLaMA 가 핫하길래 순전히 내 궁금증 해소 차원에서 메모를 남긴다.기술블로그 포스팅은 다른 사람이 정보를 이해하기 쉽도록 일목요연하게 쓰면 좋겠으나그러려면 글을 쓰는 수고가 많이 들 테고, 나는 내 궁금증만 해결하면 되는데 너무 input 이 크다.(사실 라마
2.[NLP] Transformer (1) : Background (RNN, Seq2Seq)

올해 내내 백엔드 개발에 치중하여 NLP 지식을 많이 까먹었어요 😂 또한 기계번역 이외의 도메인에 뛰어들었더니 당장 내가 할 수 있는 게 없었고 특히 올 한 해 동안 ChatGPT, LlaMa 와 같은 LLM 이 쏟아져 나오면서 NLP러로서의 미래에 대해 많은 고민을
3.[NLP] Transformer (2) : Overview & Encoder Input Embedding
이제 Transformer 를 살펴봅시다. 아래는 Transformer 구조를 그림으로 나타낸 것으로, NLP러라면 한번쯤 본 적이 있을 거에요. (저는 이 그림을 참고하여 Transformer 의 동작 원리를 설명하는 기술 면접을 치른 적이 있어요 😂) 이 포스팅
4.[NLP] Transformer (3) : Self-Attention & Multi-Head Attention
본 포스팅은 다음 사이트를 참고하여 작성하였습니다. https://ratsgo.github.io/nlpbook/docs/language_model/transformers/ Self-Attention? Attention 먼저 설명하겠습니다. Attention 은 '(문
5.[NLP] Transformer (4) : Encoder etc
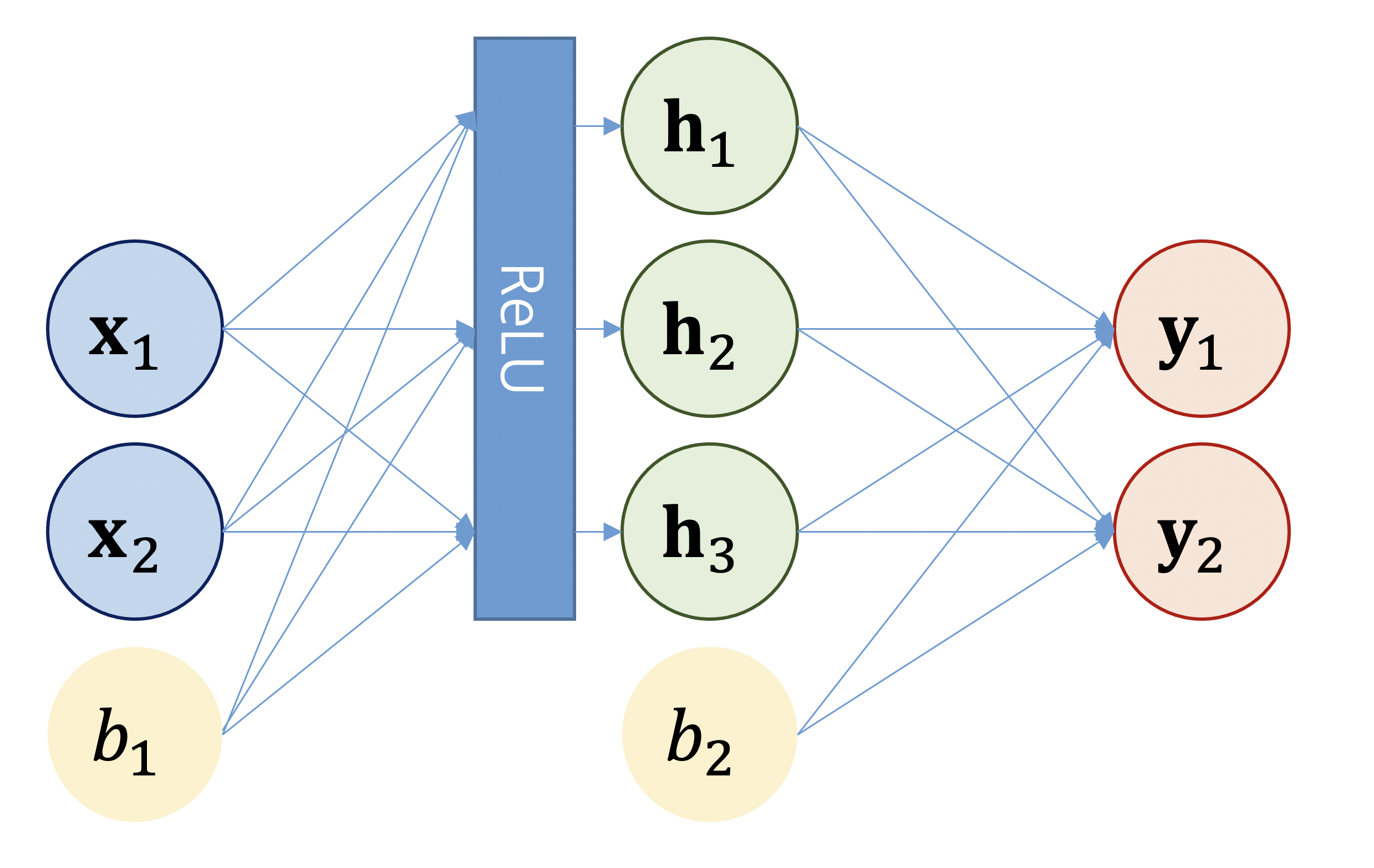
Self-Attention 을 제외한 Encoder 의 나머지 구성 요소를 살펴봅시다 본 포스팅은 다음 저서와 사이트를 참고하여 작성하였습니다. Do it! BERT와 GPT로 배우는 자연어 처리 https://www.yes24.com/Product/Goods/10
6.[NLP] Transformer (5) : Decoder
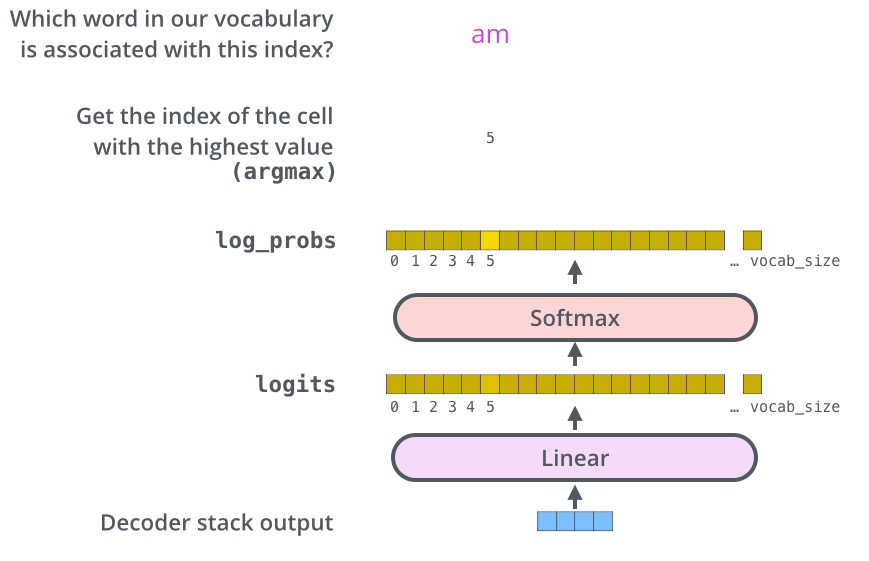
이번 포스팅에서는 아래 도서 및 포스팅을 많이 참고했습니다. Do it! BERT와 GPT로 배우는 자연어 처리 https://www.yes24.com/Product/Goods/105294979 https://jalammar.github.io/illustrated-t
7.LangCon2024 후기

이번 LangCon 의 주제는 '생성 모델 튜닝(LLM)' 으로,학계 및 업계의 다양한 시각과 시도에 대해 전해 들을 수 있었던 시간이었습니다.(개인적으로 Langcon2020 에서 발표한 후, 첫 랭콘 참석이었습니다 😊)LangCon2024 안내 페이지발표자 및 발
8.[NMT] COMET : 신경망 기반 번역 품질 평가 지표
부제 : ChatGPT 를 이용해 10분만에 이해하는 COMETCrosslingual Optimized Metric for Evaluation of Translation최근 몇 년간 주목받고 있는 신경망 기반 번역 품질 평가 지표기존의 BLEU, METEOR, TER처