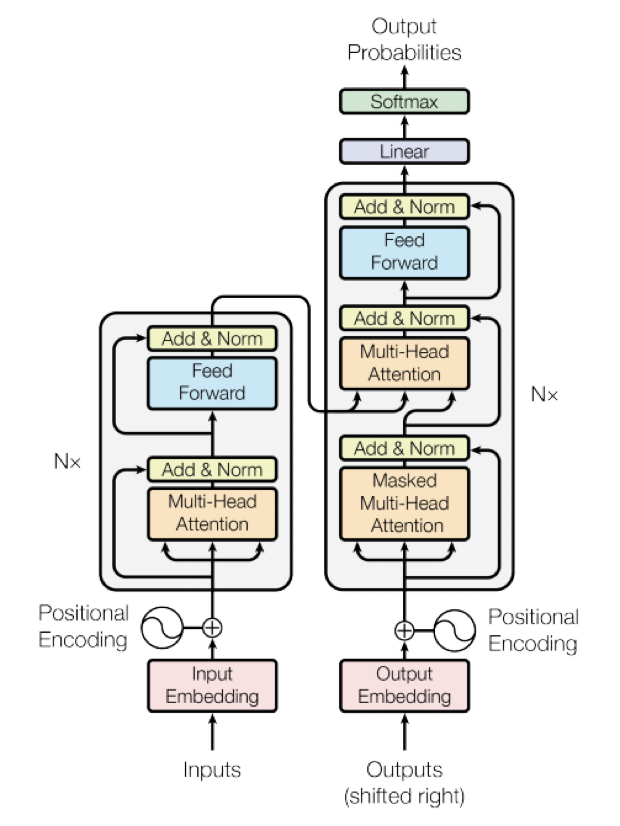
이제 Transformer 를 살펴봅시다.
아래는 Transformer 구조를 그림으로 나타낸 것으로, NLP러라면 한번쯤 본 적이 있을 거에요.
(저는 이 그림을 참고하여 Transformer 의 동작 원리를 설명하는 기술 면접을 치른 적이 있어요 😂)
이 포스팅은 아래 포스팅과 도서를 참고하여 작성하였습니다.
혹시 저작권에 문제가 있다면 알려주세요!
Do it! BERT와 GPT로 배우는 자연어 처리
https://www.yes24.com/Product/Goods/105294979
https://jalammar.github.io/illustrated-transformer/
Encoder - Decoder
트랜스포머는 크게 Encoder - Decoder 2개의 구조로 이루어져 있어요.
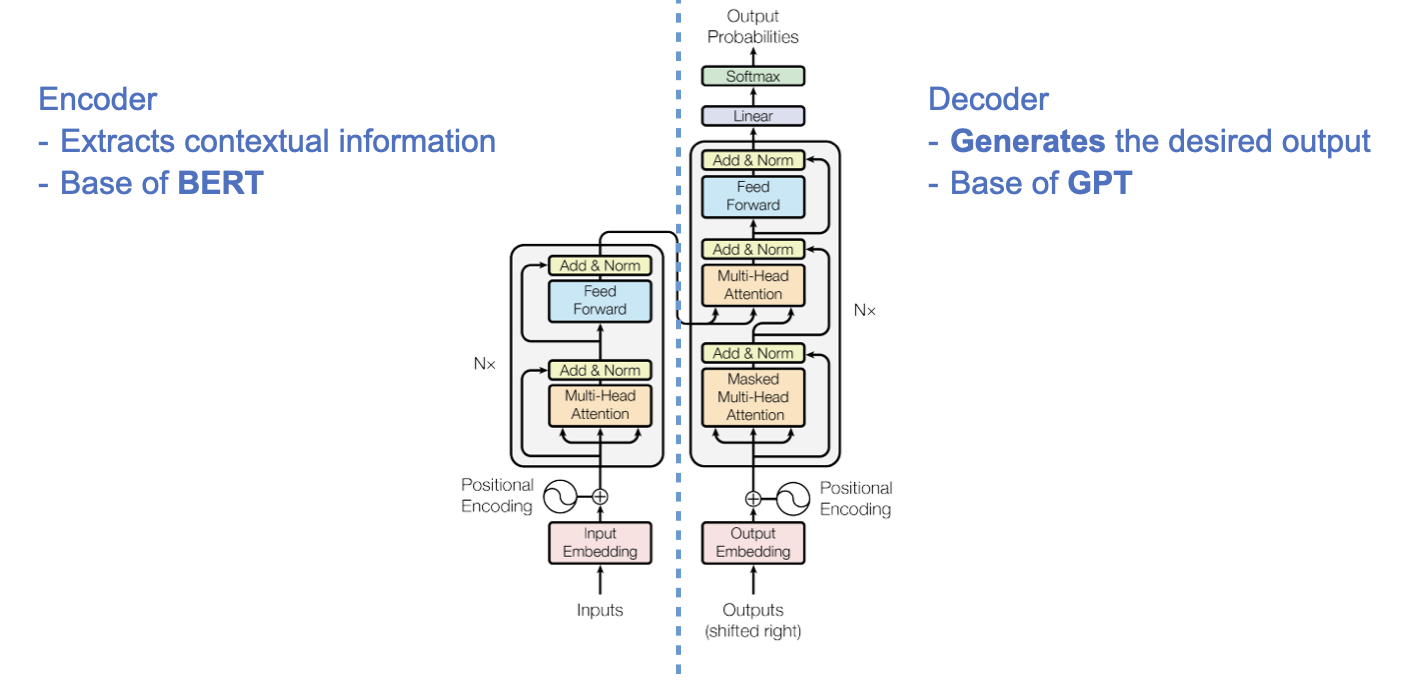
인코더는 입력 문장을 다차원 공간으로 임베딩하고, 문맥 정보(Context) 를 추출하는 역할을 합니다.
입력 문장의 단어나 토큰을 임베딩하고, 다양한 어텐션 메커니즘을 사용하여 단어 간의 상관 관계를 파악합니다.
이후 마지막 인코더 레이어의 출력은 디코더로 전달됩니다.
이 점을 이용해 Transformer 의 Encoder 로부터 BERT 가 만들어졌습니다.
디코더는 인코더의 출력과 디코더의 입력값을 이용해 이전 스텝에서 생성된 결과를 활용하여 target 을 생성하는 작업을 수행합니다.
다시 말해, 주어진 문제에 맞는 출력을 생성하지요.
이 점을 이용해 Transformer 의 Decoder 로부터 GPT 가 만들어졌습니다.
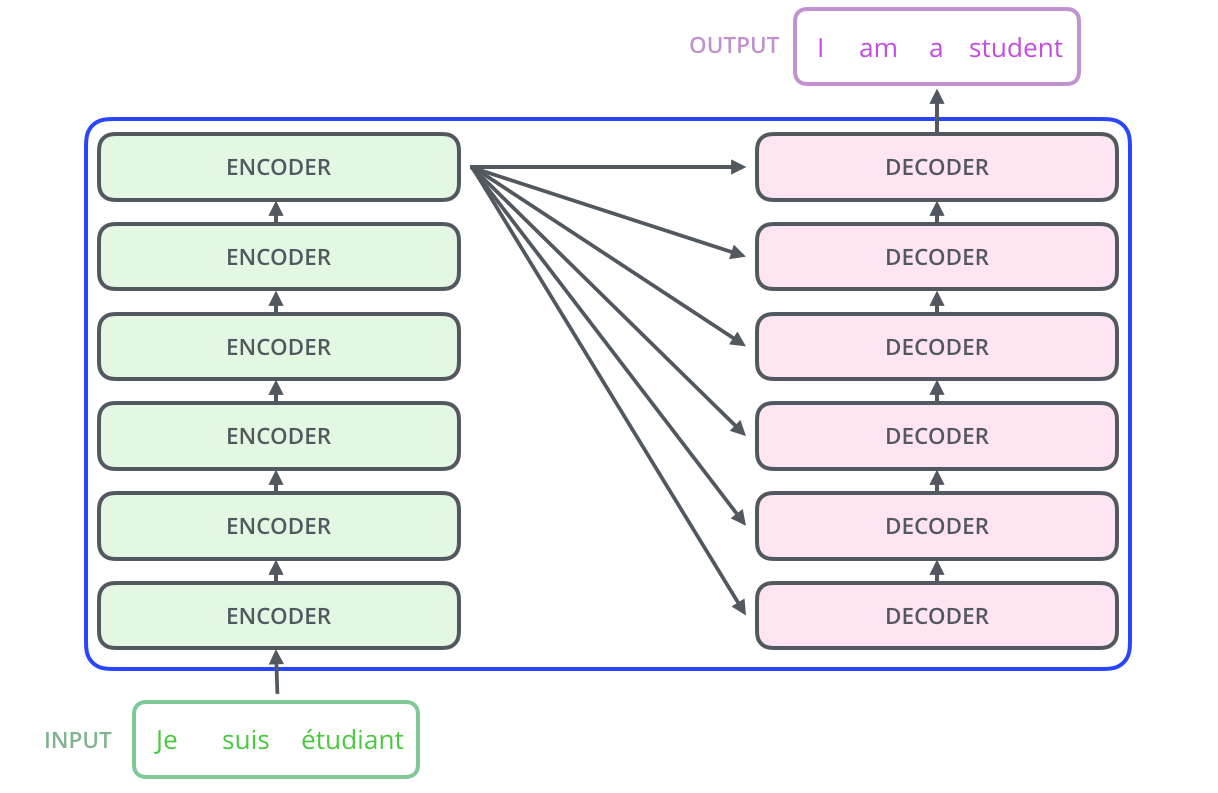
또한 이 Encoder 및 Decoder 는 N개의 layer 를 쌓아서 만드는데요,
Baseline 모델은 각각 6개의 layer 를 쌓습니다.
(인코더의 경우 구조가 모두 동일하지만 보시다시피 layer 간 가중치를 공유하지는 않습니다.)
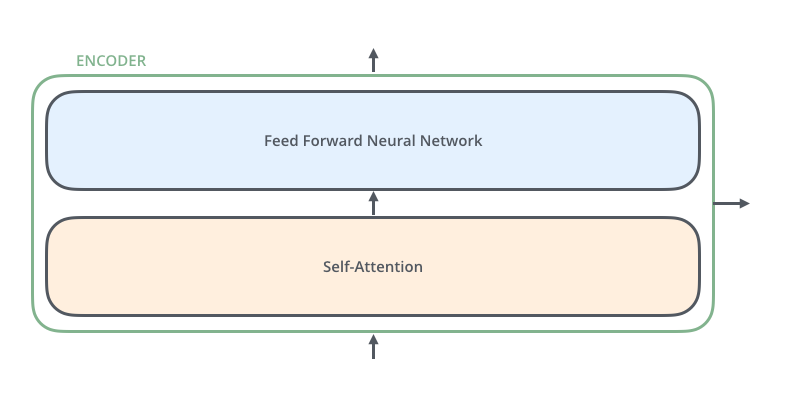
An Encoder Layer
Encoder layer 를 살펴보면 크게 2개의 부분으로 나뉘는데요,
Self-Attention layer 와 Feed-Forward Neural Network 입니다.
Inputs & Input Embedding
우선 Encoder layer 에 input 이 어떻게 들어가는지 살펴볼까요?

우선 Tokenizer 를 이용해 문장을 token 단위로 쪼개고,
임베딩 알고리즘을 사용하여 각각의 token 을 벡터로 변환하는 것으로 시작합니다.
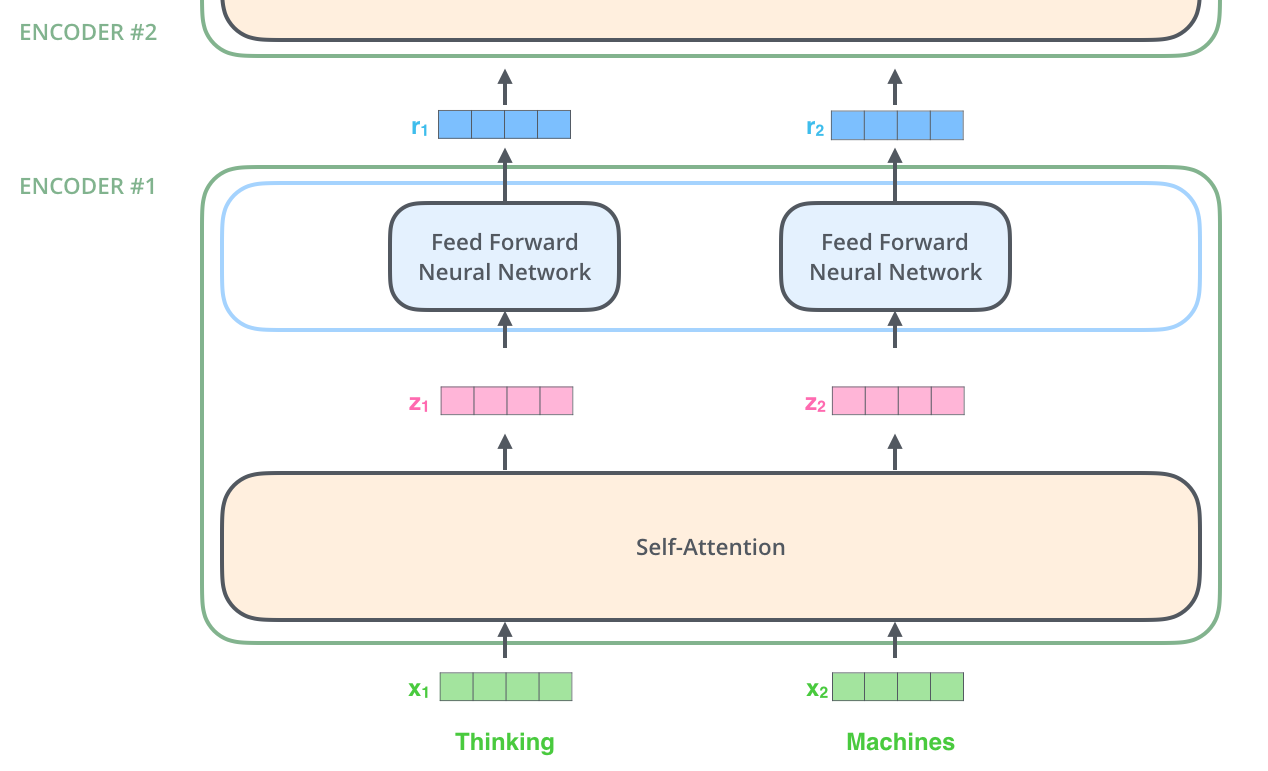
각각의 token 은 512 크기의 벡터로 변환되며, 그림의 초록색 상자 X가 벡터로 변환된 token 입니다.
이러한 임베딩은 맨 아래(첫번째) 인코더 레이어에서만 발생합니다.
After Embedding..
임베딩 즉 토큰을 벡터로 변환하는 과정이 끝나면 벡터 리스트가 생성되겠지요?
이 벡터 리스트를 인코더에 넣어 줍니다.
인코더는 입력받은 벡터 리스트를 Self-Attention 계층으로 전달하고,
Self-Attention 의 출력값 Z벡터들을 FFNN (Feed Forward Neural Network) 레이어로 전달합니다.
FFNN 은 어텐션의 결과를 취합하여 전달하는 역할을 하지요.
FFNN 의 출력 r은 다음 인코더 레이어로 전달됩니다.
이 과정을 인코더 레이어의 갯수만큼 반복합니다.
다음 포스팅에서 Transformer 의 핵심적인 부분인 Self-Attention 을 다루겠습니다.
