이번 포스팅에서는 아래 도서 및 포스팅을 많이 참고했습니다.
Do it! BERT와 GPT로 배우는 자연어 처리
https://www.yes24.com/Product/Goods/105294979
https://jalammar.github.io/illustrated-transformer/
https://zorba-blog.tistory.com/28
https://wikidocs.net/31379
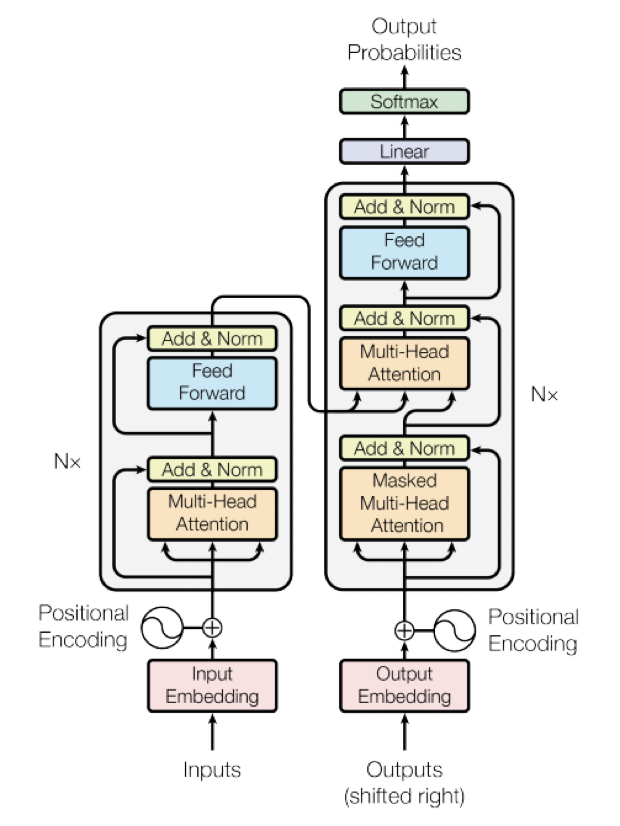
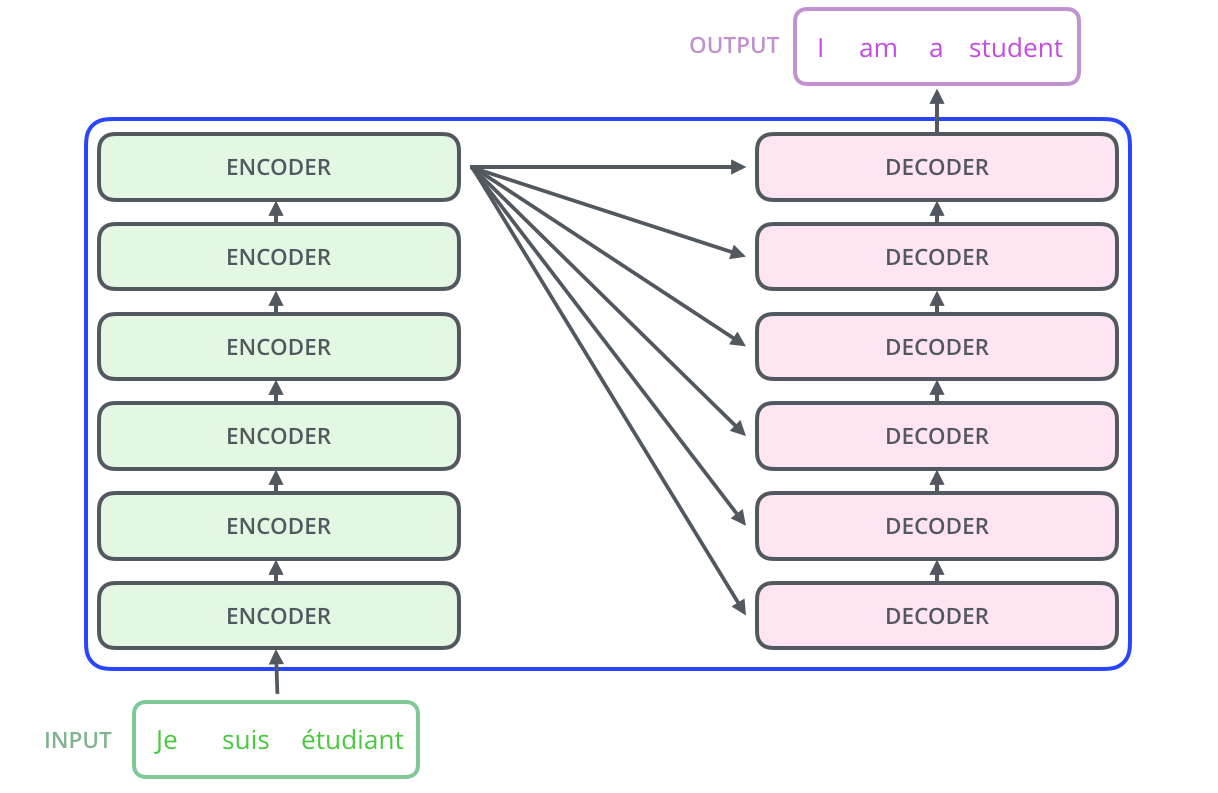
- 인코더는 총 레이어 갯수만큼 순차적으로 연산을 한 후에 마지막 인코더 레이어의 출력을 디코더로 전달.
- 디코더 또한 레이어 갯수만큼 연산을 하는데, 연산을 할 때마다 인코더가 보낸 출력을 각 디코더 레이어의 연산에 사용.
Masked Multi-head Self-Attention
디코더의 Attention 은 인코더와 비교하여 어떤 점이 다를까요?
Look-ahead Mask
-
seq2seq의 디코더에 사용되는 RNN 계열의 신경망은 입력 단어를 매 시점마다 순차적으로 입력 받으므로 다음 단어 예측에 현재 시점을 포함한 이전 시점의 단어들만 참고.
-
반면, 트랜스포머는 학습 과정에서 번역할 문장 행렬을 한번에 입력받아 행렬로 병렬처리하는데,
입력을 한 번에 받으므로 현재 시점의 단어를 예측하고자 할 때 미래 시점의 단어까지도 참고할 수 있는 현상이 발생. -
이를 위해 트랜스포머의 디코더에서는 현재 시점의 예측에서 미래 시점의 단어들을 참고하지 못하도록 룩-어헤드 마스크(look-ahead mask)를 도입.
-
룩-어헤드 마스크(look-ahead mask)는 디코더의 첫 번째 서브층에서 이루어짐.
-
디코더의 첫 번째 서브층인 멀티 헤드 셀프 어텐션 층은 인코더의 첫 번째 서브층인 멀티 헤드 셀프 어텐션 층과 동일한 연산 수행.
-
차이점은 어텐션 스코어 행렬에서 마스킹을 적용한다는 점.
-
아래와 같이 셀프 어텐션을 통해 어텐션 스코어 행렬을 얻음.
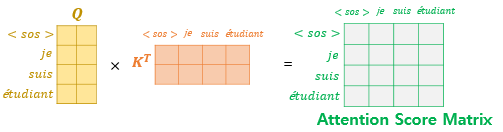
-
그리고 아래와 같이 자신보다 미래에 있는 단어들을 참고하지 못하도록 마스킹.
-
마스킹 된 후의 어텐션 스코어 행렬의 각 행을 보면 자기 자신과 그 이전 단어들만을 참고.
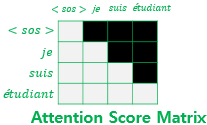

https://deeppago.tistory.com/43 -
트랜스포머에는 총 세 가지 어텐션이 존재하며, 모두 멀티 헤드 어텐션을 수행하고, 함수 내부에서 스케일드 닷 프로덕트 어텐션 함수를 호출하는데 각 어텐션 시 함수에 전달하는 마스킹은 아래와 같음.
- 인코더의 셀프 어텐션 : 패딩 마스크를 전달
- 디코더의 첫번째 서브층인 마스크드 셀프 어텐션 : 룩-어헤드 마스크, 패딩 마스크를 전달
- 디코더의 두번째 서브층인 인코더-디코더 어텐션 : 패딩 마스크를 전달
Multi-head Attention
Encoder 의 어텐션과 같으나, 엄밀히 말해 Self-Attention 이 아닙니다!
Self-Attention 은 Query, Key, Value 모두 같은 경우인데
Decoder 의 경우 Query 는 디코더 첫번째 레이어의 output,
Key 와 Value 는 encoder 의 output 이기 때문입니다.
다음과 같은 Query, Key 벡터를 이용해 셀프 어텐션 계산을 수행합니다.
- Query = 디코더 입력값 = Target
- Key = 인코더 입력값 = Source

https://ratsgo.github.io/nlpbook/docs/language_model/tr_self_attention/#%EB%94%94%EC%BD%94%EB%8D%94%EC%97%90%EC%84%9C-%EC%88%98%ED%96%89%ED%95%98%EB%8A%94-%EC%85%80%ED%94%84-%EC%96%B4%ED%85%90%EC%85%98
Query, Key, Value 가 개인적으로 너무 헷갈리네요 😂
- Query = Decoder의 은닉상태(현재 우리가 유추해야하기 위한 정보에 대한 은닉상태)
- Key = Encoder의 은닉상태들(Query와 얼마나 연관되어있는지 체크해야할 Encoder의 LSTM셀의 은닉벡터들)
- Value = Encoder의 은닉상태들(Key로 꺼내온 Encoder의 은닉벡터 값들)
https://cnu-jinseop.tistory.com/192
저 나름대로는 이렇게 이해했는데요, 정확하진 않습니다 😅
- Encoder : 커피 마시다
- Decoder : Drink Coffee
커피 를 { } 로 번역하면 Coffee
- 커피 = Key 🔑
- { } = Query ❓
- Coffee = Value 💡
Linear & Softmax
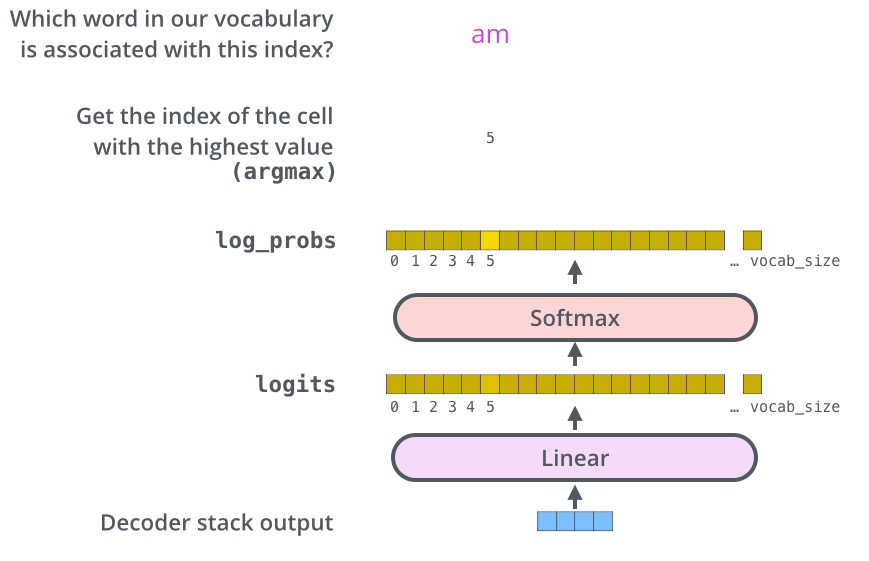
Decoder 의 최종 output vector는 마지막으로 linear와 softmax layer를 차례대로 통과하여 타깃 시퀀스 벡터를 출력합니다.
Linear layer
단순한 fully connected layer 입니다.
마지막 decoder 의 output vector를 logit vector로 변환해주는 역할을 합니다.
다시 말하면,
decoder 의 output vector 를 그보다 훨씬 더 큰 사이즈인 logit vector 로 투영시킵니다.
- 모델이 training 데이터에서 총 10,000개의 영어 단어를 학습하였다고 가정 (이를 모델의 “output vocabulary”라고 부름)
- 이 경우, logits vector의 크기는 10,000
- 벡터의 각 셀은 그에 대응하는 각 단어에 대한 점수
Softmax layer
Linear layer 에서 변환된 logit vector를 각 token이 될(?) 확률로 바꿔줍니다.
다시 말해, 가장 높은 확률 값을 가지는 셀에 해당하는 단어가 바로 해당 스텝의 최종 output 입니다.
https://better-tomorrow.tistory.com/entry/Transformer-Decoder-Linear-Softmax-Layer
https://www.ohsuz.dev/nlp-cookbook/transformer
