Self-Attention 을 제외한 Encoder 의 나머지 구성 요소를 살펴봅시다
본 포스팅은 다음 저서와 사이트를 참고하여 작성하였습니다.
Do it! BERT와 GPT로 배우는 자연어 처리
https://www.yes24.com/Product/Goods/105294979
https://ratsgo.github.io/nlpbook/docs/language_model/transformers/
https://jalammar.github.io/illustrated-transformer/
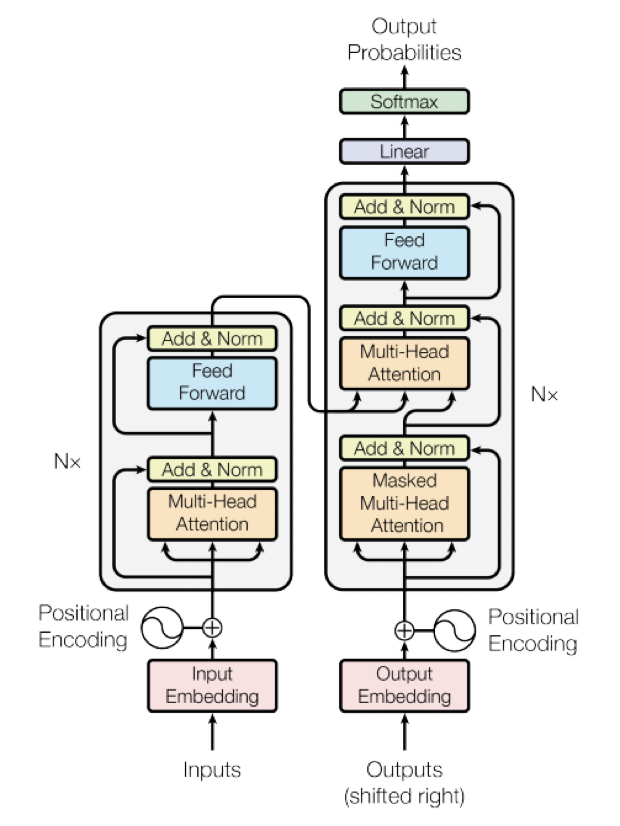
Positional Encoding
기존의 RNN, Seq2Seq 은 문장을 순차적으로 처리합니다.
Transformer 는 행렬 연산을 통해 입력된 문장을 병렬로 한번에 처리하여 연산 속도가 매우 빠른데요,
단점으로는 단어의 위치(순서) 를 알 수 없다는 점입니다.
Transformer에서는 단어의 위치 정보를 얻기 위해, 즉 단어에 위치 벡터를 부과하기 위해 Positional Encoding 을 사용합니다.
Sin & Cos 함수를 이용하여 단어의 위치 벡터를 구하고, 단어 벡터의 뒷쪽에 summation 연산을 해 줍니다.
(벡터 2개를 이어 붙이는 Concat 이 아니라 벡터값의 단순 덧셈인 sum)
자세한 설명은 이 포스팅에서는 생략하겠습니다.
https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding
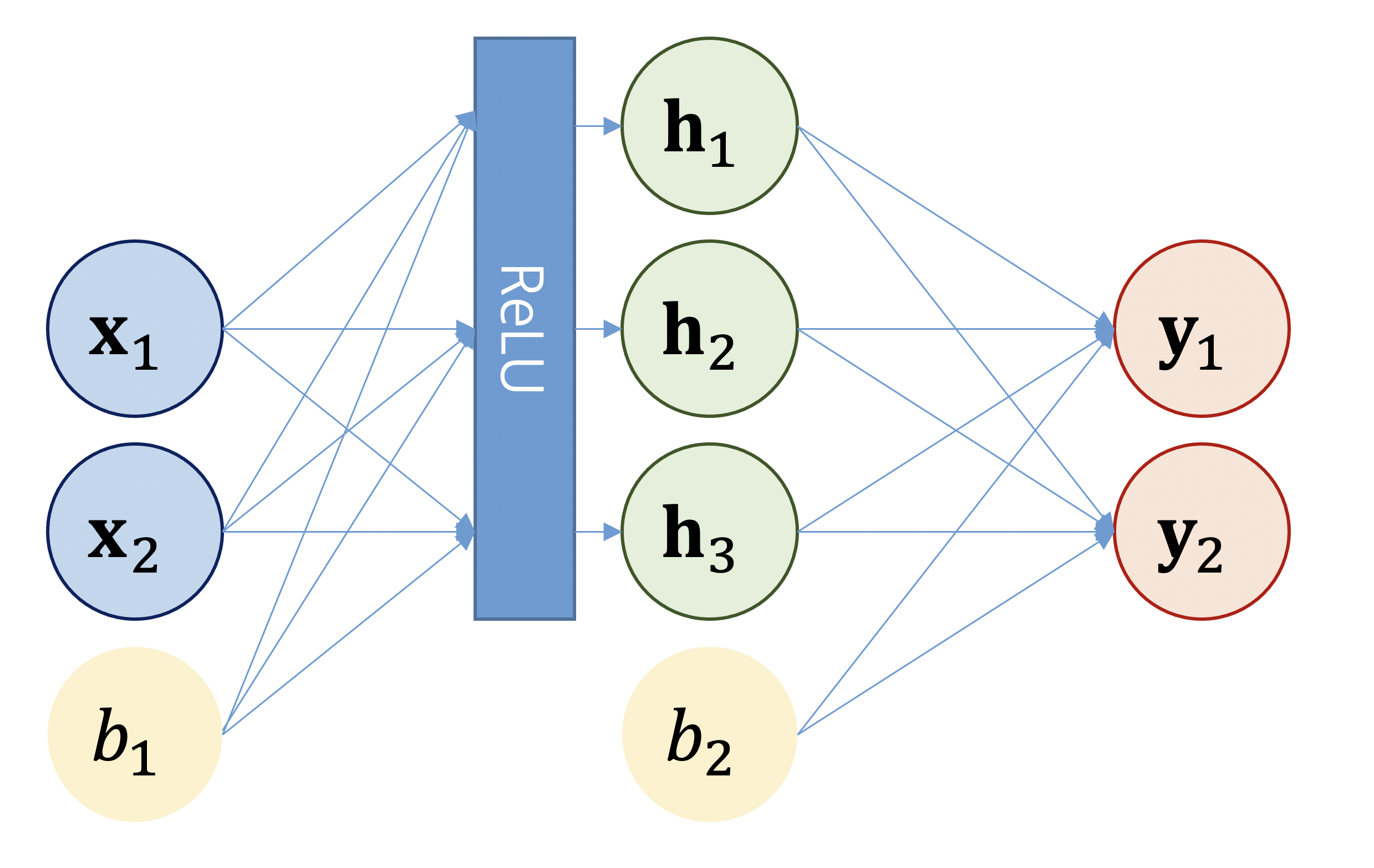
FFNN (Feed Forward Neural Network)
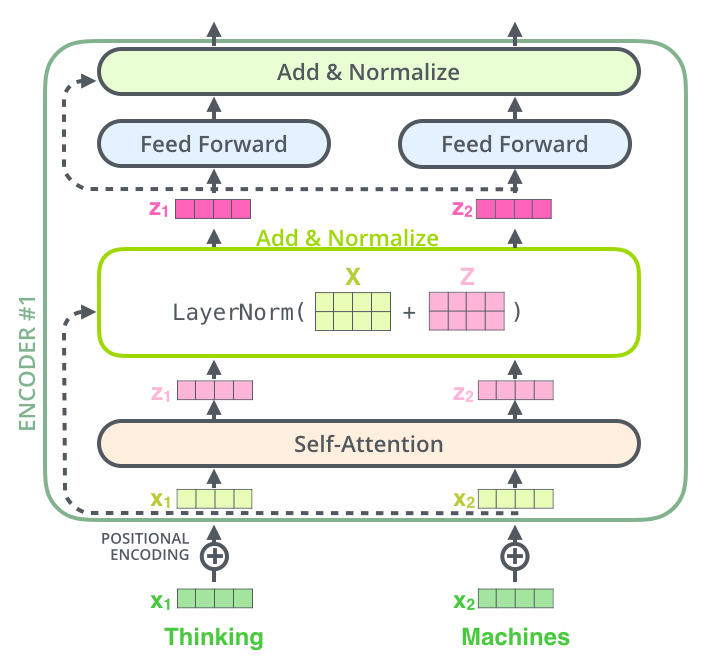
Multi-head Attention 의 출력은 입력 단어들에 대응하는 벡터 시퀀스인데요,
이후 벡터 각각을 FFNN에 입력합니다.
https://ratsgo.github.io/nlpbook/docs/language_model/tr_technics/
FFNN의 학습 대상은 가중치 weight 와 bias 로, 학습 과정에서 업데이트됩니다.
또한 트랜스포머에서 사용하는 FFNN의 활성함수는 ReLU(Rectified Linear Unit)로,
양수 입력값은 그대로 유지하되 음수 입력값은 모두 0으로 일괄적으로 눌러 줍니다.
(활성함수 : 현재 계산하고 있는 뉴런의 출력을 일정 범위로 제한)
한편 트랜스포머에서는 은닉층의 뉴런 갯수(즉 은닉층의 차원수)를 입력층의 4배로 설정하고 있습니다.
예컨대 FFNN의 입력 벡터가 512차원일 경우 은닉층은 2048차원까지 늘렸다가 출력층에서 이를 다시 512차원으로 줄입니다.
Add (Residual Connection)
블록이나 레이어 계산을 건너뛰는 경로를 하나 두는 것으로,
모델이 다양한 관점에서 블록 계산을 수행하는 효과가 있습니다.
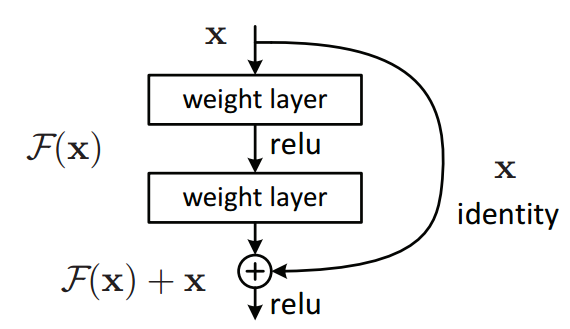
딥러닝 모델은 레이어가 많아지면 학습이 어려워지는 경향이 있는데, 모델을 업데이트하기 위해 그레이디언트가 전달되는 경로가 길어지기 때문입니다.
또한 Residual Connection 은 모델 중간에 블록을 건너뛰는 경로를 설정하여 학습을 쉽게 하는 효과도 있습니다.
Norm (Layer Normalization)
레이어 정규화(layer normalization)란 미니 배치의 인스턴스(𝐱)별로 평균을 빼주고 표준편차로 나눠 주어 정규화(normalization)을 수행하는 기법입니다.
레이어 정규화를 수행하면 학습이 안정되고 속도가 빨라지는 효과가 있습니다.
이러한 레이어 정규화는 미니배치의 인스턴스별로 수행합니다.
