음성으로부터 화자를 인식할 때 (Speaker Recognition), 다음과 같은 단계를 거칩니다.
speaker embedding 을 만든 후,각 임베딩 값을 더욱 잘 분류하기 위해 metric learning 을 사용하는데요,
이 논문에서는 metric learning 에 사용되는 개선된 objective (목적함수) 'Angular prototypical' 를 소개합니다.
In defence of metric learning for speaker recognition
Abstract
- an extensive evaluation of most popular loss functions for speaker recognition on the VoxCeleb dataset.
- the vanilla triplet loss (metric learning) shows competitive performance compared to classification- based losses, and those trained with our proposed metric learning objective outperform state-of-the-art methods. (= Angular Prototypical)
= 우리는 새로운 objective (목적함수) 'Angular Prototypical' 을 소개합니다.
Training functions
🤖 ChatGPT
- 분류(Classification):
- 분류는 주어진 입력 데이터를 미리 정의된 클래스 레이블로 분류하는 작업입니다.
- 분류 문제에서 모델은 주어진 입력 데이터에 대해 해당 클래스 레이블을 예측하는 방법을 학습합니다.
- 각 입력 데이터는 하나의 클래스 레이블에 속하며, 모델의 목표는 정확한 클래스 레이블을 예측하는 것입니다.
- 분류 작업은 지도 학습(Supervised Learning)의 일반적인 형태로, 주로 이미지, 텍스트, 음성 등의 데이터에서 적용됩니다.
- 메트릭 러닝(Metric Learning): 입력 데이터 간의 거리를 이용해 판단
- 메트릭 러닝은 데이터 간의 유사성을 측정하거나 유사한 항목들을 클러스터링하는 작업에 중점을 둡니다.
- 주로 비지도 학습(Unsupervised Learning) 방법 중 하나로 사용되며, 데이터 간의 거리나 유사성을 측정하는 메트릭을 학습합니다.
- 메트릭 러닝은 주로 얼굴 인식, 이미지 검색, 개체 추적 등과 같이 유사성 기반 작업에서 사용됩니다.
- 주요 목표는 고차원 공간에서 데이터 포인트 간의 거리나 유사성을 보존하고 잘 정의된 유사성 메트릭을 학습하는 것입니다.
2.1. Classification objectives
- C = 5, 994 speakers or classes (of VoxCeleb2 development set)
- mini-batch contains
- N : utterances each from different speakers
- Speaker’s (embedding, label) : (, )
- 1 ≤ i ≤ N, 1 ≤ y ≤ C.
Softmax
🤖 ChatGPT
Softmax 함수는 대부분의 경우 지도 학습(Supervised Learning)에서 주로 사용됩니다. 이 함수는 일반적으로 분류(Classification) 문제에서 출력을 클래스 확률로 변환하는 데 사용됩니다.
(참고) Softmax
The softmax loss consists of a softmax function followed by a multi-class cross-entropy loss
AM-Softmax(CosFace)
클래스간 각도를 통해 차이를 주어 서로 다른 클래스간에는 더 큰 격차를 만드는 방법
https://velog.io/@gtpgg1013/논문리뷰-ArcFace-Additive-Angular-Margin-Loss-for-Deep-Face-Recognition
- (Releated work) SphereFace?
- wx + b → cos(θ)
- 얼굴 분류 문제의 한계
-
데이터가 라벨당 몇 장 없고 (사람 얼굴일테니까요), 레이블도 무지막지하게 많습니다. (학습에 사용한 사람 명수)
-
softmax function을 사용하게 되면 같은 클래스 내에서(for intra-class)는 비슷하게 Embedding이 형성되고, 다른 클래스 끼리(for inter-class)는 다르게 Embedding이 형성된다는 말입니다.
🤔 그러나, 얼굴 인식 task 같은 경우 실제 사람은 다르지만, "사람" 들로만 구성된 데이터셋이기 때문에 intra-class와 같은 성질을 띄게 됩니다.
😢 위의 이유때문에 성능 저하(performance gap)이 발생할 수 있다고 이야기합니다.
-
- 위의 문제들을 해결하기 위해 bias는 없애고, 벡터간 각도에 집중하는 방법을 사용했습니다.
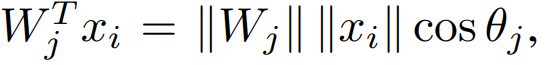
By normalising the weights and the input vectors(= |W| 값은 L2 norm 에 의해 1로 제한, |x| 도 L2 norm 에 의해 제한됨.) , softmax loss can be reformulated such that the posterior probability only relies on cosine of angle between the weights and the input vectors
Normalized Softmax Loss (NSL) function:
However, embeddings learned by the NSL are not sufficiently discriminative because the NSL only penalises classification error. In order to mitigate this problem, cosine margin m is incorporated into the equation:
s : fixed scale factor to prevent gradient from getting too small in training phase.
Face Recognition - CosFace (1)
AAM-Softmax (ArcFace)
This is equivalent to CosFace except that there is additive angular margin penalty m between
xi and Wyi → margin 을 아예 cos() 안에 넣어버림.
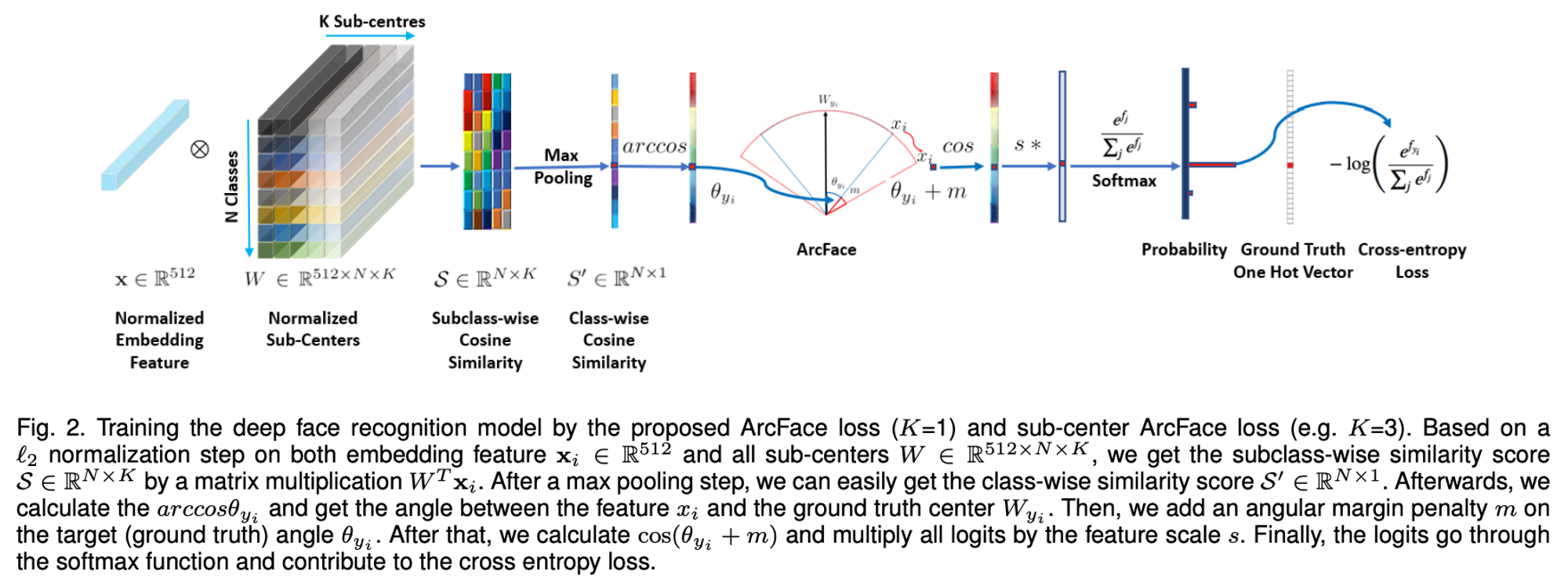
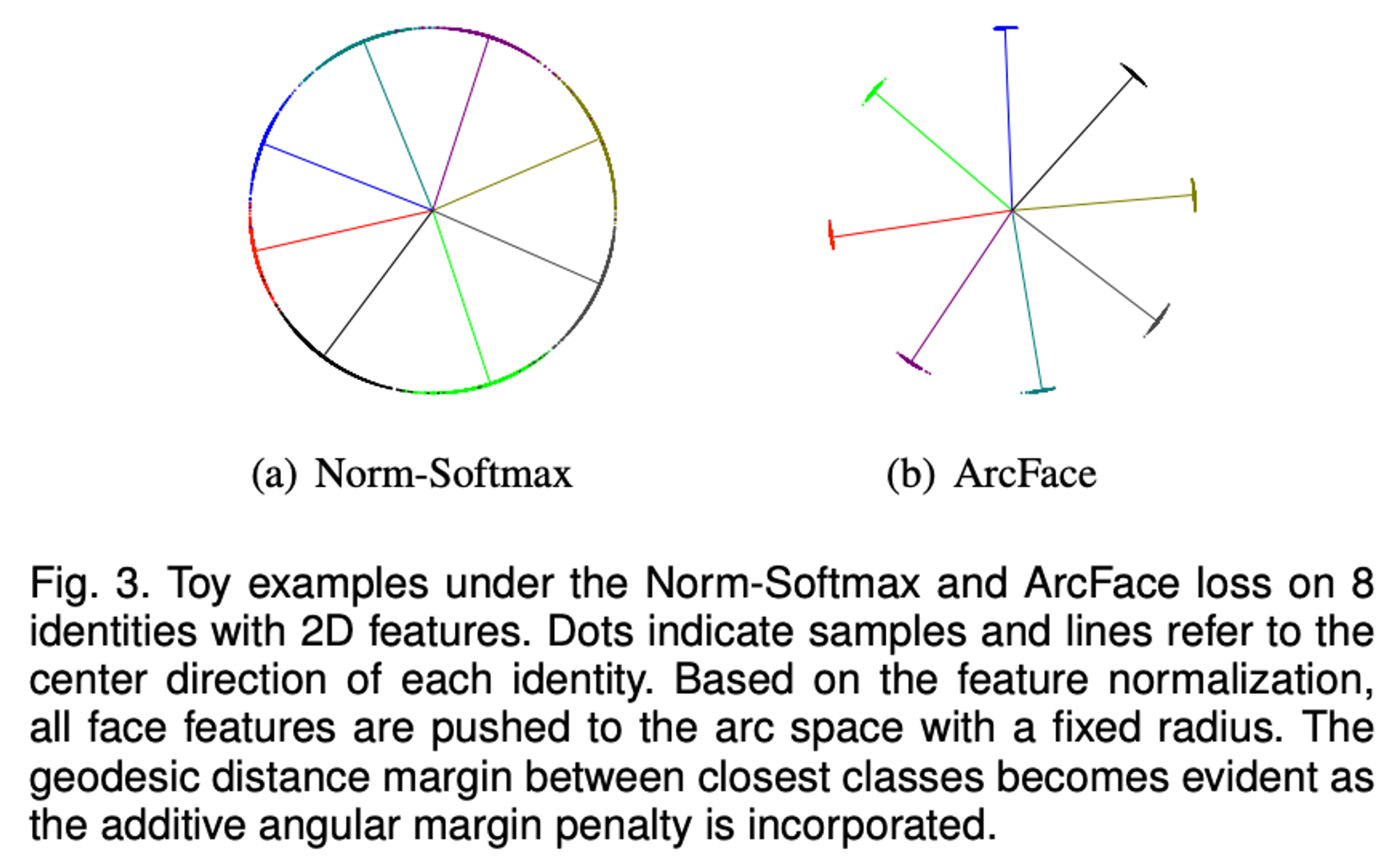
→ 각도를 이용하면 클래스 사이의 경계값이 좀더 명확해짐!
2.2. Metric learning objectives
For metric learning objectives, each mini-batch contains M utterances from each of N different speakers, whose embeddings
are where 1 ≤ j ≤ N and 1 ≤ i ≤ M.
- mini-batch contains
- M : utterances from each of N different speakers
- Speaker’s embedding :
- 1 ≤ j ≤ N, 1 ≤ i ≤ M.
Triplet
ChatGPT
트리플렛 손실은 주로 다음과 같은 세 가지 요소로 구성됩니다:
- 앵커(Ancor) 샘플: 손실을 계산할 기준이 되는 샘플입니다.
- 긍정(Positive) 샘플: 앵커 샘플과 같은 클래스에 속하는 유사한 샘플입니다.
- 부정(Negative) 샘플: 앵커 샘플과 다른 클래스에 속하는 샘플입니다.
여기서, 는 두 샘플 간의 거리(논문에서는 L2 distance) 를 나타내며, 는 마진(margin)이라고 불리는 하이퍼파라미터입니다. 이 함수는 앵커 샘플과 긍정 샘플 간의 거리를 최소화하고, 앵커 샘플과 부정 샘플 간의 거리를 최대화하면서 마진(m) 값을 유지하도록 학습합니다.
[ancher - positive 거리] - [ ancher - negative 거리] + [margin]
Prototypical
Centroid 를 이용하는 Clustering:
- Centroid(Prototype) 를 구함
- query x의 데이터 클래스 예측 시 x와 c간의 거리를 이용해 유사도를 구함
Each mini-batch contains a support set S and a query set Q.
For simplicity, we will assume that the query(=x) is M-th utterance from every speaker.
Then the prototype (or centroid) is:
Squared Euclidean distance (x(query) - centroid(prototype) 의 거리):
During training, each query example is classified against N speakers based on a softmax over distances to each speaker prototype:
ex) 5-shot learning 하고 싶다면 M = 5+1 즉 5-shot(s) + 1 query(x) 개로 mini-batch 구성.
Generalized end-to-end(GE2E)
Centroid 를 생성할 때, x가 query 라면 제외하고 생성한다.
The similarity matrix is defined as scaled cosine similarity between the embeddings and all centroids:
Squared Euclidean distance → Cos sim 으로 변경
Angular(cos sim) Prototypical
The angular prototypical loss uses the same batch formation as the original prototypical loss, reserving one utterance from every class as the query. → 모든 class 에 query 존재.
This has advantages over GE2E-like formation since every centroid is made from the same number of utterances in the support set, therefore it is possible to exactly mimic the test scenario during training.
We use a cosine-based similarity metric with learnable scale and bias, as in the GE2E loss.
Using the angular loss function introduces scale invariance, improving the robustness of objective against feature variance and demonstrating more stable convergence
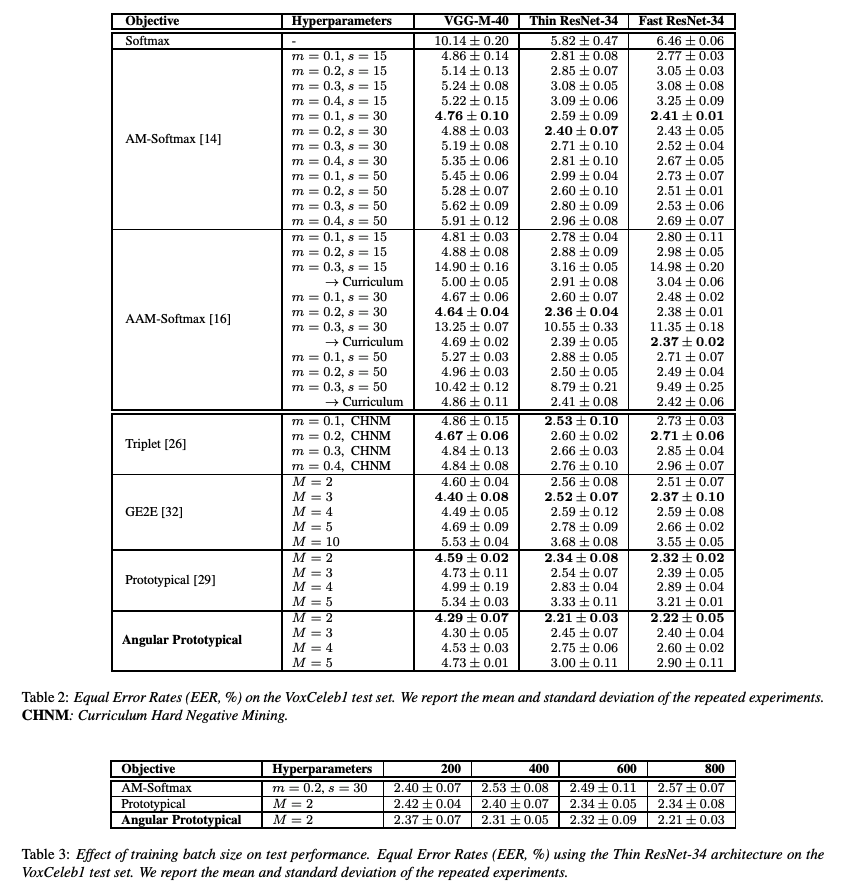
3. Experiments
Reference
Review (그림으로 수식 설명)
[화자인식] Metric Learning in Speaker Recognition
