실무에서 RAG 서비스를 개발할 때 RAG 및 LLM 의 성능을 개선하는 것만큼 중요한 점은
서비스에 사용할 문서에서 RAG가 질의에 맞는 내용을 검색하고
검색 결과 데이터를 LLM에 적합한 형태와 크기로 제공하는 것인데요.
다시 말해, 문서 데이터 또는 문서 파일을 Vector DB에 적당한 크기의 텍스트로 분할하여 넣어야 합니다.
문서 파일은 pdf 인 경우가 많고, (ex : 메뉴얼, 보험서류 등)
이 때문에 pdf 문서 파일의 내용이 변형되거나 누락되지 않게 텍스트로 추출할 필요가 있는데요,
이번 포스팅에서는 널리 쓰이는 pdf 변환 오픈소스의 성능을 비교합니다.
- 비교 기준
- 텍스트, 표, 이미지 추출 가능 여부 및 품질
비교 기준을 이와 같이 정한 이유는, 현업에서 PDF 문서는 텍스트와 표, 이미지로 구성된 경우가 많고
이 3가지를 얼마나 깨지지 않게 '잘' 추출하는지 고려해야 하기 때문인데요,
특히 RAG 성능과 직결되고, 표와 이미지와 같이 LLM이 인식하기 어려운 형태의 경우
표는 LLM 이 처리할 수 있는 텍스트 즉 Markdown 형태로 변환한다던지,
혹은 검색 결과를 사용자에게 제시할 때 출처 혹은 참고자료로서의 이미지를 정확하게 제시해야 하기 때문입니다.
예제 코드 : GitHub
Sample
샘플로 사용한 문서 파일 중 표가 존재하는 페이지(10p) 위주로 비교합니다.
표의 텍스트만을 추출할 경우, 표를 Markdown 으로 추출할 경우를 주로 비교하기 위함이며
이미지의 경우 텍스트로 온전히 추출하기 어렵기 때문에
이미지를 추출하는 코드만 따로 비교합니다.
(Tip : 표를 Markdown 으로 추출하면 텍스트가 되기 때문에 vector DB에 바로 임베딩하여 넣을 수 있지만
표 구조가 복잡하면 (행/열이 중첩되면) 추출이 잘 되지 않고,
또는 표가 이미지 형태인 경우 OCR 을 활용하기도 합니다.)

PyPDF
LangChain 튜토리얼에서 가장 흔하게 사용하는 라이브러리입니다.
속도가 다른 라이브러리에 비해 상대적으로 느리고,
표와 이미지를 추출할 수 없다는 단점이 있습니다.
Code
PDF File Load
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(file_name)
docs = loader.load()
docs텍스트 추출
print(docs[9].page_content)보험용어 해설
보험용어 용어 해설
보험약관보험계약에 관하여 보험계약자와 보험회사 상호간에 이행하여야 할 권리
와 의무를 규정한 것
보험증권보험계약의 성립과 그 내용을 증명하기 위하여 보험회사가 보험계약자에
게 교부하는 증서
...Fitz (PyMuPDF)
사용 결과 속도가 빠르고, 표 및 이미지 추출을 모두 지원합니다.
Code
PDF File Load
from langchain_community.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader(file_name)
docs = loader.load()
docs텍스트 추출
print(docs[9].page_content)
# 또는
import fitz
result_text = []
# fitz.open 을 사용할 수도 있고
docs = fitz.open(file_name)
# Get only 10p
print(docs[9].get_text())보험용어 해설
보험용어
용어 해설
보험약관
보험계약에 관하여 보험계약자와 보험회사 상호간에 이행하여야 할 권리
와 의무를 규정한 것
...표 추출 + Markdown 변환
# import package PyMuPDF
import fitz
import pandas as pd
# Open some document, for example a PDF (could also be EPUB, XPS, etc.)
docs = fitz.open(file_name)
# Load 10p & Look for tables on this page and display the table count
tabs = docs[9].find_tables()
# Select the first table
table = tabs[0]
# 표가 추출되었는지 확인
if table:
# pandas DataFrame으로 변환
df = table.to_pandas()
# DataFrame을 Markdown 형식으로 변환
markdown_table = df.to_markdown(index=False) # 인덱스를 제외하려면 index=False
print(markdown_table)
# 명시적으로 파일 닫기
docs.close()| 보험용어 | 용어 해설 |
|:-------------|:---------------------------------------------------------------------|
| 보험약관 | 보험계약에 관하여 보험계약자와 보험회사 상호간에 이행하여야 할 권리 |
| | 와 의무를 규정한 것 |
| 보험증권 | 보험계약의 성립과 그 내용을 증명하기 위하여 보험회사가 보험계약자에 |
| | 게 교부하는 증서 |
...이미지 추출
import fitz # PyMuPDF
import io
import os
from PIL import Image
# 'fitz_image' 폴더가 없으면 새로 생성합니다.
output_folder = "fitz_image"
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Open the file
pdf_file = fitz.open(file_name)
# Iterate over PDF pages
for page_index in range(len(pdf_file)):
# Get the page itself
page = pdf_file[page_index]
# Get the image list for the page
image_list = page.get_images(full=True)
# Printing the number of images found on this page
if image_list:
print(f"[+] Found a total of {len(image_list)} images in page {page_index + 1}")
# else:
# print("[!] No images found on page", page_index + 1)
# Extract images from the page
for image_index, img in enumerate(image_list, start=1):
xref = img[0]
base_image = pdf_file.extract_image(xref)
image_bytes = base_image["image"]
image_ext = base_image["ext"]
# Save the image to a file
image_filename = f"{output_folder}/page_{page_index + 1}_image_{image_index}.{image_ext}"
with open(image_filename, "wb") as img_file:
img_file.write(image_bytes)
# Close the PDF document
pdf_file.close()PdfPlumber
표 및 이미지 추출을 모두 지원하지만, 속도는 Fitz 에 비해 느립니다.
하지만 Fitz 에 비해 다양한 옵션을 제공합니다.
Code
PDF File Load
from langchain.document_loaders import PDFPlumberLoader
loader = PDFPlumberLoader(file_name)
docs = loader.load()
docs텍스트 추출
print(docs[9].page_content)
# 또는
import pdfplumber
with pdfplumber.open(file_name) as pdf:
# Get only 10p
print(pdf.pages[9].extract_text())보험용어 해설
보험용어 용어 해설
보험계약에 관하여 보험계약자와 보험회사 상호간에 이행하여야 할 권리
보험약관
와 의무를 규정한 것
...표 추출 + Markdown 변환
import pdfplumber
import pandas as pd
# PDF 파일 열기
with pdfplumber.open(file_name) as pdf:
# Load 10p & Look for tables on this page and display the table count
table = pdf.pages[9].extract_table()
# 표가 추출되었는지 확인
if table:
# pandas DataFrame으로 변환
df = pd.DataFrame(table[1:], columns=table[0]) # 첫 번째 행은 컬럼명
# DataFrame을 Markdown 형식으로 변환
markdown_table = df.to_markdown(index=False) # 인덱스를 제외하려면 index=False
print(markdown_table)| 보험용어 | 용어 해설 |
|:-------------|:---------------------------------------------------------------------|
| 보험약관 | 보험계약에 관하여 보험계약자와 보험회사 상호간에 이행하여야 할 권리 |
| | 와 의무를 규정한 것 |
| 보험증권 | 보험계약의 성립과 그 내용을 증명하기 위하여 보험회사가 보험계약자에 |
| | 게 교부하는 증서 |
...이미지 추출
import pdfplumber
import io
from PIL import Image
def extract_images_from_pdf(file_name, output_folder):
# PDF 파일 열기
with pdfplumber.open(file_name) as pdf:
image_index = 0 # 이미지 인덱스 초기화
# 각 페이지에서 이미지 추출
for page_num, page in enumerate(pdf.pages, start=1):
# 페이지에서 이미지 추출
images = page.images
# 페이지에 이미지가 있다면
for img_index, image in enumerate(images, start=1):
# 이미지 정보 가져오기
image_bytes = image['stream'].get_data() # 이미지 바이트 데이터
image_filename = f"{output_folder}/page_{page_num}_img_{img_index}.png"
# 이미지 파일 저장
with open(image_filename, "wb") as img_file:
img_file.write(image_bytes)
print(f"Saved image {image_filename}")
# 이미지 바이트를 이미지 객체로 변환할 경우 사용
# image = Image.open(io.BytesIO(image_bytes))
# # 이미지 저장
# image.save(image_filename)
# print(f"Image saved: {image_filename}")
# 사용 예시
output_folder = "plumber_images" # 이미지가 저장될 폴더
if not os.path.exists(output_folder):
os.makedirs(output_folder)
extract_images_from_pdf(file_name, output_folder)결과 비교
텍스트 추출 결과

표 추출 결과 (MarkDown)
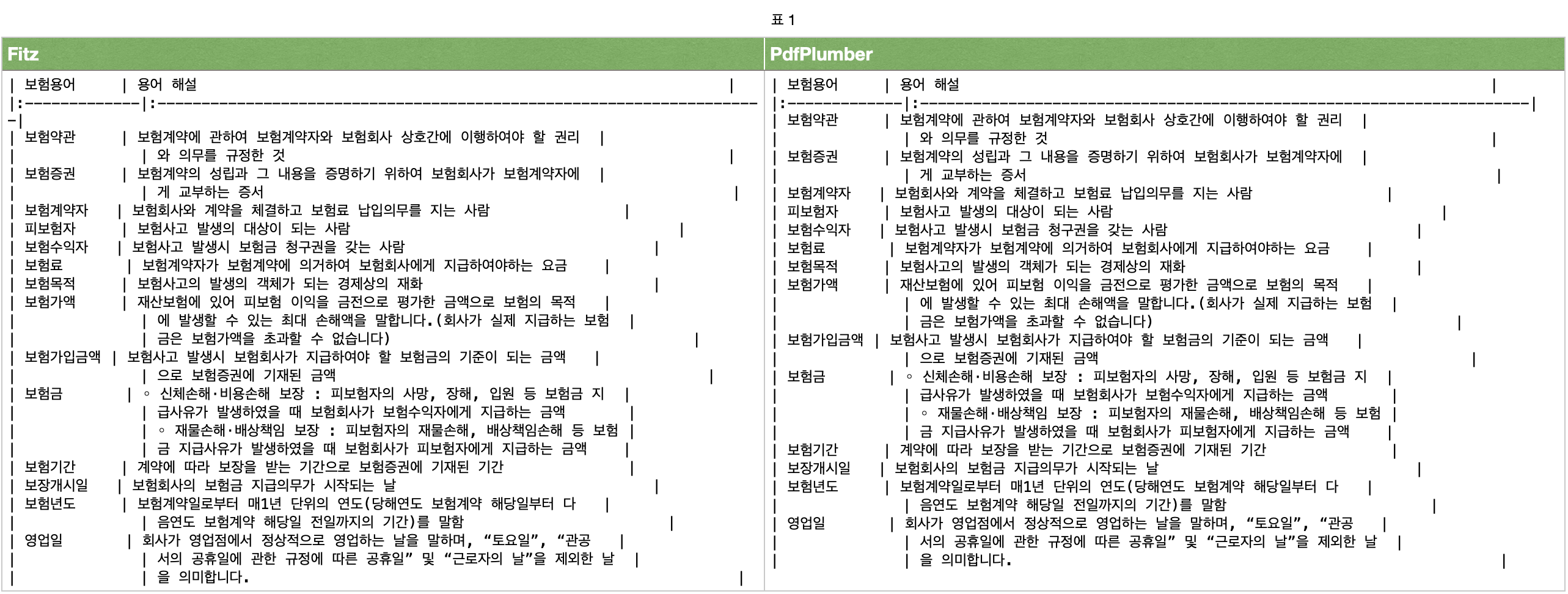
이미지 추출 결과는 Fitz, PdfPlumber 모두 동일하므로 생략합니다.
추출 속도

참고
https://velog.io/@alswjd404/랭체인에서-PDF-Load하기실패
https://digitalbourgeois.tistory.com/356
https://github.com/microsoft/markitdown
