[글또] RAG 시리즈
1.[RAG 시리즈] PGVector 와 프롬프트를 이용한 RAG 고도화

기본 튜토리얼 가장 기본적이고 유명한 Teddy Note 튜토리얼을 먼저 실행해 보겠습니다. Code VectorDB 로 ChromaDB 를, retriever 로 기본 retriever 를 사용합니다. 프롬프트 템플릿 또한 기본 템플릿을 이용했습니다. 프롬프트
2.[RAG 시리즈] LangChain VectorStore DB구조와 활용
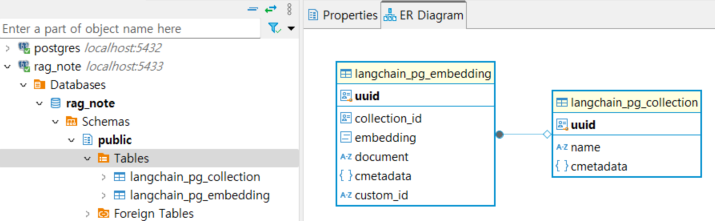
[RAG 시리즈] PGVector 와 프롬프트를 이용한 RAG 고도화 포스팅에서 PDF 파일 로드 -> 청킹 -> vector store 에 저장하는 과정을 다루었는데요, 이번 포스팅에서는 vector store DB에 데이터가 어떤 형태로 저장되어 있는지 살펴보고,
3.[RAG 시리즈] Hybrid Search 와 재순위화 알고리즘 (RRF 를 곁들인..)

Hybrid Search 설명을 위해 다음 포스팅 글 중 일부를 발췌하여 재구성했습니다. [우아한 스터디] RAG 성능을 끌어올리는 Pre-Retrieval (Ensenble Retriever) 와 Post-Retrieval (Re-Rank) 하이브리드 검색 구현하기
4.[RAG 시리즈] Multi-Query 와 Fusion 기법

RAG(Retrieval-Augmented Generation)에서 retrieve 단계에서 사용하는 multi-query와 fusion 기법은 질의의 정확성을 높이고 더 풍부한 정보를 얻기 위해 사용됩니다. 두 기법은 주로 검색 결과의 질을 높이고, 다양한 정보 조합
5.[RAG 시리즈] PDF 로부터 데이터를 추출하는 라이브러리 비교 (PyPDF, Fitz, PdfPlumber)

실무에서 RAG 서비스를 개발할 때 RAG 및 LLM 의 성능을 개선하는 것만큼 중요한 점은 서비스에 사용할 문서에서 RAG가 질의에 맞는 내용을 검색하고 검색 결과 데이터를 LLM에 적합한 형태와 크기로 제공하는 것인데요. 다시 말해, 문서 데이터 또는 문서 파일을
6.[RAG 시리즈] RAGAS 를 이용한 실전 RAG 평가
RAGAS 는 RAG 의 평가지표 중 특히 Rule Base 지표들을 자동으로 계산하기 위해 만들어진 프레임워크입니다.쉽게 말해 RAG 파이프라인을 구축한 후,파이프라인의 input / output 을 이용해 평가 지표 계산에 필요한 데이터셋 (question, ans
7.[RAG 시리즈] 임베딩 모델별 RAG 성능 비교
지난 포스팅에서 다음과 같은 고찰을 했는데요, 따라서 이번 포스팅에서는 embedding 모델별 RAG 품질을 비교합니다. 또한 유료로 사용하는 OpenAI 모델뿐만 아니라 무료(속도는 느리지만) HuggingFace 모델도 함께 비교합니다. 튜토리얼 코드 : Gi
8.[RAG 시리즈] ChatBot 구축하기 : Rule Base 부터 LangGraph 까지
보험사, 금융사, 사내 메뉴얼 등 문서를 참조하는 챗봇에서 RAG가 사용되는 경우가 많은데요,다시 말해, 좋은 챗봇을 구축하는 일 또한 RAG개발에 수반되는 업무입니다.이번 포스팅에서는 Rule Base 로 챗봇을 구축한 경험을 공유하고,최근 AI Agent 개발에 쓰