이번 후기에서는 두번째 세션, 즉 이 강의의 메인 세션의 내용을 정리합니다.
풍부한 예시와 디테일한 설명 중에서 내용을 간추리려니 결코 쉽지 않은데요,
이번 세션은 그만큼 빼놓을 것이 하나도 없는, 정말 실전에서 바로 쓸 수 있는 내용으로만 꽉 채운 세션입니다.
개인적으로 현재 제가 회사에서 수행중인 프로젝트에서 많은 시행착오를 거쳤는데
이번 세션을 듣고 나니 왜 시행착오를 많이 겪을 수밖에 없었는지 이해할 수 있었습니다.
이번 세션에서는 '데이터셋 구축 PM' 의 역할에 대해 설명하지만, 저는 NLP Engineer 이기 때문에
세션 내용 중 개인정보 보호, 작업자 관리 등의 매니징 작업에 대한 내용은 제 역할 밖의 업무(권한) 이기 때문에 다소 생략합니다.
제가 수강한 <실전 AI 서비스 기획> 강의는 Upstage AI 의 이활석 CTO님 직강인데요,
실전 AI서비스를 만드신 CTO님의 모든 경험이 강의에 아낌없이 녹아 있습니다.
강의 URL : https://www.udemy.com/course/upstage-jump-into-the-ai-world/
Session 2. 제품 개발 A to Z
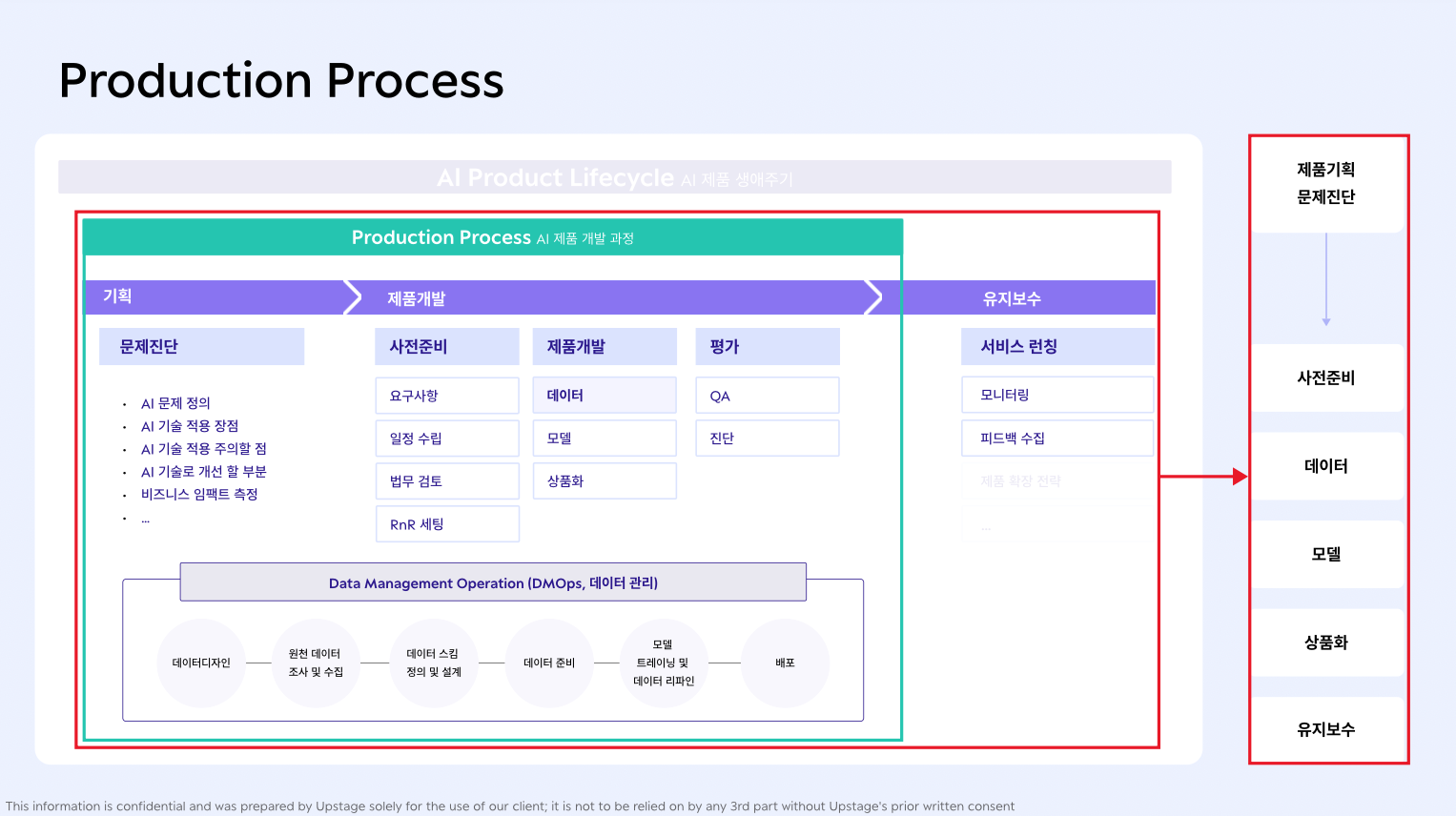
[2-1] 제품 기획, 어떻게 정의하고 진단할 것인가
- 문제 정의
- 해결하고자 하는 문제는 무엇인가?
- 어떻게 해결할 것인가?
- AI 역할 정의
- AI기술이 현재 문제를 해결하는 데 적합한가? (=적정 기술성을 체크하라)
- AI 대신 자동화, 예측, 패턴 인식과 같은 상대적으로 리소스가 덜 드는 작업으로 대체할 수 있다면 대체한다
- 비즈니스 임팩트 측정
- AI 기술 도입에 필요한 예산, 리소스, 시간이 충분한가?
- AI 기술을 적용하여 얻을 수 있는 이익이 충분한가?
[2-2] 모델 개발 과제 요구사항 구체화
- 데이터 요구사항
- 데이터의 종류 / 양, 다양성 / 라벨링 작업 필요 여부 / 시간, 예산 고려
- 평가방식 요구사항
- 서비스 평가 시 어떤 기준으로 정량 & 정성 평가를 할 것인가?
- 모델 성능 평가, 이에 필요한 평가 지표, 테스트 데이터 고려
- 모델 성능 개선을 위한 반복적인 평가 방식 고려
- 모델 요구사항
- 모델 반응속도 / 정확도 / qps (초당 처리해야 할 사용량) / 서빙 방식
- 서비스 윤리 검토
- 활용할 수 있는 개인정보인가?
- 서비스 운영 과정에서 수집하는 데이터 관리
- 외부 API 사용 가능한가?
[2-3] 중요한 것은 양질의 데이터
- 데이터 디자인
- 데이터셋 구축 목표와 요구사항 정의
- 데이터 종류, 형식, 크기 고려
- 원천데이터 조사 및 수집
- 수집 원천 / 수집을 위한 도구 선택 / 수집에 필요한 권한, 동의서 등 준비
- 데이터 스킴 정의 및 설계
- 데이터 제작 계획에 일정이 충분히 반영되었는가?
- 라벨링 체계는 데이터셋의 정보를 모두 담을 수 있도록 설계되었는가?
- 라벨링 작업 중 발생하는 특이 케이스 (edge case) 대처 방안이 마련되었는가?
- 데이터 준비
- 데이터 정제 수행
- 이상치, 결측치 등을 적절하게 처리하여 일관성 있는 데이터셋을 구축하였는가?
- 데이터의 크기를 고려한 적절한 저장 장치와 처리 방법을 선택하였는가?
- 데이터 정제 수행
- 모델 트레이닝 & 데이터 리파인
- 데이터 추가 수집이 필요한 경우는?
- 구축된 데이터의 품질을 평가하였고, 모델 학습에 적합한지 확인하였는가?
- 실제 데이터 유입
- 데이터 유입 시 모니터링, 오류 처리, 로깅 등 고려
- 개인정보 보호
- 데이터 저장 및 전송 과정에서 암호화 적용
- 데이터 (아마도 raw data 를 말하는 듯함) 를 필요 이상으로(필요한 기간 이상으로) 보관하지 않는다
- 편향성 대응
- 데이터 수집 시 발생할 수 있는 편향성을 인지하고 최소화한다
- 모델 개발 시 편향성을 고려하고, 다양성과 공정성을 확보하는가?
- 결과 해석 과정에서 또한 편향성을 인지하고 보정하는가?
[2-4] 모델 개발 단계에서 미리 정해야 할 것들
- 목표에 따른 평가 메트릭 선택
- 정성적 목표, 정량적 목표 모두 설정한다
- 모델 성능을 측정할 평가 메트릭을 정한다
- 비즈니스 요구사항과 관련된 메트릭은?
- 평가 및 결과 해석
- 평가 데이터 준비
- 비교 대상 준비 (이전 모델 또는 기준 모델)
- 평가 실험 계획 수립 및 평가 결과 해석
- 결과를 바탕으로 모델 개선
[2-5] 잘 만든 모델, 그 다음은 어떻게 되나요?
- Cloud AI - Edge AI
- Latency 응답 속도 (대기 시간) 이 서비스에 영향을 끼치는가?
- 인터넷 연결 여부
- 데이터 전송 여부
- Offline Learning - Online Learning
- 처리할 데이터가 대량/소량인가?
- 추론 작업에 긴 시간이 소요되는지 / 추론 주기가 즉각적으로 완료되어야 하는가?
- 실시간으로 변화하는 추론 결과 또는 데이터에 대한 실시간 응답이 필요한가?
- 작업 환경이 대규모 데이터 처리에 적합한가 / 실시간 처리에 적합한가?
- Batch Inference - Online Inference
- 모델 학습 데이터가 대량의 정적 데이터인가 / 실시간으로 변화하는가?
- 실시간 데이터 수집 및 전처리가 가능한가?
- 모델 계산에 리소스가 많이 드는가?
- 모델이 새로운 데이터에 적응해야 하는가? (실시간 데이터 업데이트가 필요한가)
[2-6] 서비스가 기대만큼 작동하지 않는 이유는?
실제로 개발한 서비스가 기대만큼 작동하지 않는 경우 다음 항목들을 고려할 수 있음.
- 도메인 이해
- 사용자 행동 모니터링
- 피드백 수집 및 분석
- 데이터 시각화 등을 통한 분포 변화 확인
- 데이터 품질 변화 확인
- 데이터 변화 원인 분석
- 성능 평가 및 모니터링
- 특정 시점에서의 성능과 초기 모델 성능을 비교하여 차이가 있는가?
- 모델 및 데이터의 변화를 실시간으로 모니터링하는 시스템이 있는가?
- 모델 업데이트와 출시 관리
- 비즈니스 목표와 모델 성능 조율
[2-7] 우리 서비스는 계속해서 발전하고 있어요
서비스 출시 이후의 개선에 대해 다음 항목들을 고려할 수 있음.
- 기대치 설정
- AI가 할 수 있는 것과 할 수 없는 것 명시
- Explainability AI (설명 가능한 AI)
- 서비스에 적합한 멘탈모델 형성 돕기
- 시스템에 대해 충분히 설명하여 사용자가 시스템의 예측을 신뢰해야 하는 때와 자신의 판단을 신뢰해야 하는 때를 알 수 있는가?
- 오류 대응
- 문제가 발생했음을 알리고, 해결 방법을 제공하거나 사용자가 직접 복구할 수 있는 권한을 부여하는가?
- 피드백 수집
해당 콘텐츠는 유데미로부터 강의 쿠폰을 제공받아 작성되었습니다.

NLP Researcher, AI Engineer