🦥Unsloth makes fine-tuning of LLMs 2.2x faster and use 80% less VRAM!
본 튜토리얼 포스팅은 테디노트 튜토리얼 위주로 설명하며,
Unsloth 공식 튜토리얼 중 Llama3 와 비교하여 차이점을 주석으로 달았습니다.
또한 본 포스팅에 사용한 코드와 추가 응용 코드는 GitHub 에 올려두었습니다.
Introduction
Unsloth 공식 블로그에서 말하는 주요 장점은 다음과 같습니다.
- 30배 더 빠릅니다. 알파카는 85시간 대신 3시간이 걸립니다.
- 메모리 사용량이 60% 줄어들어 배치 크기가 6배 더 커졌습니다.
- Manual(수동) autograd 와 chained matrix multiplication 최적화
- 50% 적은 메모리로 2배 빠른 파인튜닝
자세하고 친절한 소개는 🚀Unsloth-메모리-60-절약-훈련-속도-30배-향상-나만의-LLM-만들기 를 참조해 주세요.
영어 원문은 Unsloth 공식 블로그 소개 에서 확인하실 수 있습니다.
개인적으로 Unsloth 의 가장 편했던 점은 쉽고 빠른 파인튜닝뿐만이 아니라
파인튜닝이 끝난 후 모델의 GGUF 변환까지 한번에 지원한다는 것이었습니다.
llama.cpp 에서 convert.py 를 이용한 gguf 변환을 지원하지만
변환에 필요한 파일이 없거나 조건이 맞지 않는 경우에는 변환되지 않았는데
Unsloth 를 이용하면 한번에 GGUF 파일 형식으로 변환한 후에 Ollama 에서 구동할 수 있다 보니
컴퓨팅 자원이 부족한 저에게는 노트북에서 LLM을 사용할 수 있는 점이 유용했습니다.
Installation
# 공식문서
%%capture
# Installs Unsloth, Xformers (Flash Attention) and all other packages!
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
!pip install --no-deps "xformers<0.0.27" "trl<0.9.0" peft accelerate bitsandbytesTeddyNote 의 경우 패키지 충돌을 막기 위해 Cuda 버전을 나누어 Unsloth 를 설치합니다.
# Teddynote
%%capture
# Colab에서 torch 2.2.1을 사용하고 있으므로, 패키지 충돌을 방지하기 위해 별도로 설치해야 합니다.
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
if major_version >= 8:
# 새로운 GPU(예: Ampere, Hopper GPUs - RTX 30xx, RTX 40xx, A100, H100, L40)에 사용하세요.
!pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes
else:
# 오래된 GPU(예: V100, Tesla T4, RTX 20xx)에 사용하세요.
!pip install --no-deps xformers trl peft accelerate bitsandbytes
passTutorial
Base Model 설정
Base Model, 최대 시퀀스 길이, 데이터 타입, 4bit 양자화 로드 여부를 설정합니다.
from unsloth import FastLanguageModel
import torch
# 최대 시퀀스 길이를 설정합니다. 내부적으로 RoPE 스케일링을 자동으로 지원합니다!
max_seq_length = 4096 # 공식 튜토리얼은 2048
# 자동 감지를 위해 None을 사용합니다. Tesla T4, V100은 Float16, Ampere+는 Bfloat16을 사용하세요.
dtype = None
# 메모리 사용량을 줄이기 위해 4bit 양자화를 사용합니다. False일 수도 있습니다.
load_in_4bit = True
# 4배 빠른 다운로드와 메모리 부족 문제를 방지하기 위해 지원하는 4bit 사전 양자화 모델입니다.
fourbit_models = [
"unsloth/mistral-7b-bnb-4bit",
"unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"unsloth/llama-2-7b-bnb-4bit",
"unsloth/gemma-7b-bnb-4bit",
"unsloth/gemma-7b-it-bnb-4bit", # Gemma 7b의 Instruct 버전
"unsloth/gemma-2b-bnb-4bit",
"unsloth/gemma-2b-it-bnb-4bit", # Gemma 2b의 Instruct 버전
"unsloth/llama-3-8b-bnb-4bit", # Llama-3 8B
] # 더 많은 모델은 https://huggingface.co/unsloth 에서 확인할 수 있습니다.
model, tokenizer = FastLanguageModel.from_pretrained(
# model_name = "unsloth/llama-3-8b-bnb-4bit", # 공식 튜토리얼
model_name="beomi/Llama-3-Open-Ko-8B-Instruct-preview", # 모델 이름을 설정합니다.
max_seq_length=max_seq_length, # 최대 시퀀스 길이를 설정합니다.
dtype=dtype, # 데이터 타입을 설정합니다.
load_in_4bit=load_in_4bit, # 4bit 양자화 로드 여부를 설정합니다.
# token = "hf_...", # 게이트된 모델을 사용하는 경우 토큰을 사용하세요. 예: meta-llama/Llama-2-7b-hf
)PEFT : LoRA 어댑터 추가
PEFT 를 적용하기 위해 LoRA 어댑터를 추가합니다.
# 모델 초기화
model = FastLanguageModel.get_peft_model(
model,
r=16, # 0보다 큰 어떤 숫자도 선택 가능! 8, 16, 32, 64, 128이 권장됩니다.
lora_alpha=32, # LoRA 알파 값을 설정합니다. # 튜토리얼은 16
lora_dropout=0.05, # 드롭아웃을 지원합니다. # # Supports any, but = 0 is optimized
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # 타겟 모듈을 지정합니다.
bias="none", # 바이어스를 지원합니다.
# True 또는 "unsloth"를 사용하여 매우 긴 컨텍스트에 대해 VRAM을 30% 덜 사용하고, 2배 더 큰 배치 크기를 지원합니다.
use_gradient_checkpointing="unsloth",
random_state=123, # 난수 상태를 설정합니다. # 공식 : 3407
use_rslora=False, # 순위 안정화 LoRA를 지원합니다.
loftq_config=None, # LoftQ를 지원합니다.
)데이터셋 생성
데이터셋을 생성합니다.
- EOS_TOKEN 을 추가하여 무한 생성을 막습니다.
load_dataset을 추가하여 데이터셋을 로드합니다.
from datasets import load_dataset
# EOS_TOKEN은 문장의 끝을 나타내는 토큰입니다. 이 토큰을 추가해야 합니다.
EOS_TOKEN = tokenizer.eos_token
# AlpacaPrompt를 사용하여 지시사항을 포맷팅하는 함수입니다.
alpaca_prompt = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{}
### Response:
{}"""
# 주어진 예시들을 포맷팅하는 함수입니다.
def formatting_prompts_func(examples):
instructions = examples["instruction"] # 지시사항을 가져옵니다.
outputs = examples["output"] # 출력값을 가져옵니다.
texts = [] # 포맷팅된 텍스트를 저장할 리스트입니다.
for instruction, output in zip(instructions, outputs):
# EOS_TOKEN을 추가해야 합니다. 그렇지 않으면 생성이 무한히 진행될 수 있습니다.
text = alpaca_prompt.format(instruction, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts, # 포맷팅된 텍스트를 반환합니다.
}
# "teddylee777/QA-Dataset-mini" 데이터셋을 불러옵니다. 훈련 데이터만 사용합니다.
dataset = load_dataset("teddylee777/QA-Dataset-mini", split="train")
# 파일로 불러올 경우 다음 포맷을 따릅니다
# load_dataset("json", data_files="my_file.jsonl")
# 데이터셋에 formatting_prompts_func 함수를 적용합니다. 배치 처리를 활성화합니다.
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)SFT 학습 파라미터 설정
Huggingface TRL의 SFTTrainer를 사용하여 모델 학습 파라미터를 설정합니다.
from trl import SFTTrainer
from transformers import TrainingArguments
tokenizer.padding_side = "right" # 토크나이저의 패딩을 오른쪽으로 설정합니다.
# SFTTrainer를 사용하여 모델 학습 설정
trainer = SFTTrainer(
model=model, # 학습할 모델
tokenizer=tokenizer, # 토크나이저
train_dataset=dataset, # 학습 데이터셋
eval_dataset=dataset,# 테디노트에서 추가된 eval dataset
dataset_text_field="text", # 데이터셋에서 텍스트 필드의 이름
max_seq_length=max_seq_length, # 최대 시퀀스 길이
dataset_num_proc=2, # 데이터 처리에 사용할 프로세스 수
packing=False, # 짧은 시퀀스에 대한 학습 속도를 5배 빠르게 할 수 있음
args=TrainingArguments(
per_device_train_batch_size=2, # 각 디바이스당 훈련 배치 크기
gradient_accumulation_steps=4, # 그래디언트 누적 단계
warmup_steps=5, # 웜업 스텝 수
# you can set num_train_epochs=1 for a full run, and turn off max_steps=None
# 공식문서에는 없음.
num_train_epochs=3, # 훈련 에폭 수
max_steps=100, # 최대 스텝 수 # 공식문서에는 60
do_eval=True, # 테디노트에서 추가
evaluation_strategy="steps", # 테디노트에서 추가
logging_steps=1, # logging 스텝 수
learning_rate=2e-4, # 학습률
fp16=not torch.cuda.is_bf16_supported(), # fp16 사용 여부, bf16이 지원되지 않는 경우에만 사용
bf16=torch.cuda.is_bf16_supported(), # bf16 사용 여부, bf16이 지원되는 경우에만 사용
optim="adamw_8bit", # 최적화 알고리즘
weight_decay=0.01, # 가중치 감소
lr_scheduler_type="cosine", # 학습률 스케줄러 유형 # 공식은 linear
seed=123, # 랜덤 시드 # 공식은 3407
output_dir="outputs", # 출력 디렉토리
),
)Train
학습 시작
trainer_stats = trainer.train() # 모델을 훈련시키고 통계를 반환합니다.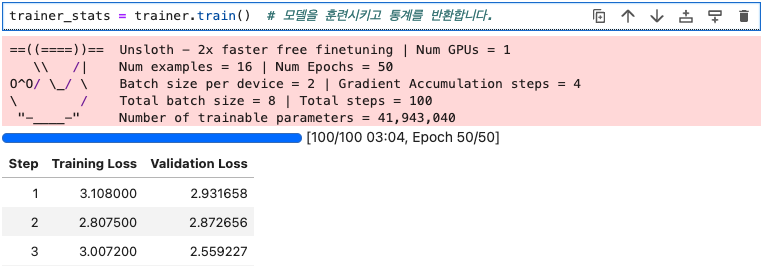
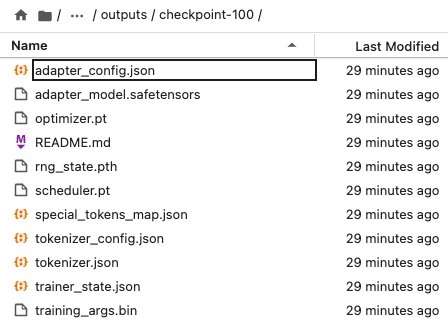
학습이 완료되면 모델 출력 경로에 다음과 같은 파일들이 생성됩니다.
Inference
TeddyNote 튜토리얼의 경우 Stop Token 을 좀더 세심하게 설정하는데요,
StoppingCriteria와 StoppingCriteriaList를 사용하여 특정 토큰에서 생성을 중단합니다.
from transformers import StoppingCriteria, StoppingCriteriaList
class StopOnToken(StoppingCriteria):
def __init__(self, stop_token_id):
self.stop_token_id = stop_token_id # 정지 토큰 ID를 초기화합니다.
def __call__(self, input_ids, scores, **kwargs):
return (
self.stop_token_id in input_ids[0]
) # 입력된 ID 중 정지 토큰 ID가 있으면 정지합니다.
# end_token을 설정
stop_token = "<|end_of_text|>" # end_token으로 사용할 토큰을 설정합니다.
stop_token_id = tokenizer.encode(stop_token, add_special_tokens=False)[
0
] # end_token의 ID를 인코딩합니다.
# Stopping criteria 설정
stopping_criteria = StoppingCriteriaList(
[StopOnToken(stop_token_id)]
) # 정지 조건을 설정합니다.TextStreamer 를 이용해 결과를 스트리밍합니다.
Text 형태로 출력값이 깔끔하게 스트리밍되는 것을 확인할 수 있습니다.
from transformers import TextStreamer
# FastLanguageModel을 이용하여 추론 속도를 2배 빠르게 설정합니다.
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
alpaca_prompt.format(
"테디노트 유튜브 채널에 대해 알려주세요.", # 지시사항
"", # 출력 - 생성을 위해 이 부분을 비워둡니다!
)
],
return_tensors="pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=4096, # 최대 생성 토큰 수를 설정합니다.
stopping_criteria=stopping_criteria # 생성을 멈출 기준을 설정합니다.
)
공식 튜토리얼의 경우 다음과 같이 TextStreamer 와 StoppingCriteria 를 사용하지 않았는데요,
결과값은 다음과 같습니다.
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"테디노트 유튜브 채널에 대해 알려주세요.", # instruction
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 4096, use_cache = True)
tokenizer.batch_decode(outputs)
PEFT Model Save
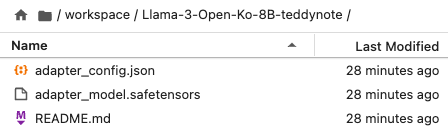
출력에 문제가 없는 점을 확인했으니 PEFT 어댑터 모델을 로컬에 저장합니다.
# 모델이 저장될 로컬 경로명 입력
model.save_pretrained("model") # 모델을 로컬 경로 'model'에 저장합니다.
# model.push_to_hub("your_name/lora_model", token = "...") # 모델을 온라인 허브에 저장합니다.(아래 캡쳐의 경우 'model' 경로 = Llama3-Open-Ko-8B-teddynote 로 설정)
VLLM을 위한 float16 저장
모델을 float16 으로 저장합니다.
base_model = "model" # 병합을 수행할 베이스 모델
# huggingface_token = "" # HuggingFace 토큰
# huggingface_repo = "Llama-3-Open-Ko-8B-Instruct-teddynote" # 모델을 업로드할 repository
save_method = (
"merged_16bit" # "merged_4bit", "merged_4bit_forced", "merged_16bit", "lora"
)로컬에 저장
model.save_pretrained_merged(
base_model,
tokenizer,
save_method=save_method, # 저장 방식을 16비트 병합으로 설정
)GGUF 변환
Unsloth 는 llama.cpp를 복제하고 기본적으로 q8_0에 저장합니다.
# Quantization 방식 설정
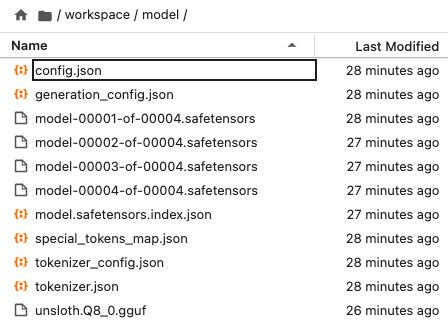
quantization_method = "q8_0" # "f16" "q8_0" "q4_k_m" "q5_k_m".gguf 파일 로컬에 저장
model.save_pretrained_gguf(
"model",
tokenizer=tokenizer,
quantization_method=quantization_method,
)
Reference
https://unfinishedgod.netlify.app/2024/06/15/llm-unsloth-gguf/
