AutoRAG
🤷♂️ 왜 AutoRAG인가?
수많은 RAG 파이프라인과 모듈들이 존재하지만, "자신의 데이터"와 "자신의 사용 사례"에 적합한 파이프라인이 무엇인지 알기란 쉽지 않습니다.
모든 RAG 모듈을 만들고 평가하는 것은 매우 시간이 많이 걸리고 어렵습니다. 그러나 이렇게 하지 않으면 나에게 가장 적합한 RAG 파이프라인을 찾을 수 없습니다.
바로 이 점에서 AutoRAG가 필요합니다.
🤸♂️ AutoRAG가 어떻게 도울 수 있을까요?
AutoRAG는 "자신의 데이터"에 최적화된 RAG 파이프라인을 찾는 도구입니다.
이를 통해 다양한 RAG 모듈을 자동으로 평가하고, 자신의 사용 사례에 가장 적합한 RAG 파이프라인을 찾을 수 있습니다.
AutoRAG는 다음과 같은 기능을 지원합니다:
데이터 생성: 자신의 문서를 사용하여 RAG 평가 데이터를 생성합니다.
최적화: 자신의 데이터에 최적화된 최고의 RAG 파이프라인을 찾기 위해 실험을 자동으로 수행합니다.
배포: 단일 YAML 파일로 최적의 RAG 파이프라인을 배포합니다. 또한 FastAPI 서버를 지원합니다.
AutoRAG를 통해, 더 이상 복잡한 RAG 파이프라인 선택에 고민할 필요 없이 자신의 데이터와 사용 사례에 딱 맞는 솔루션을 쉽게 찾고 배포할 수 있습니다.
OpenLab - LLMOps, AutoRAG에서 쿼리 확장 해보기 (Query Expansion with AutoRAG)
Tutorial : Dataset
1. Data Format
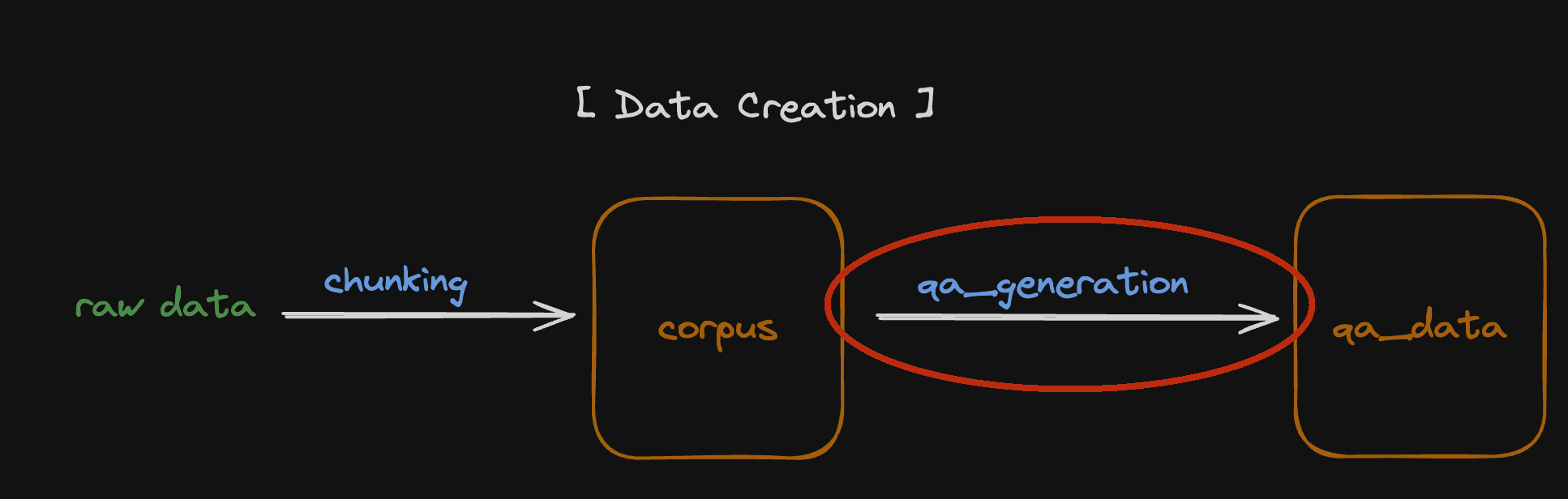
AutoRAG에 사용되는 dataset은 corpus data, qa data 2가지가 있습니다.
corpus dataset은 RAG 시스템의 정보 검색 단계에서, qa dataset은 답변 생성 및 평가 단계에서 주로 활용됩니다.
두 데이터셋의 질과 양이 RAG 시스템 전체의 성능을 좌우하게 됩니다.
- QA dataset
qa data는 qid, query, retrieval_gt, generation_gt 총 4가지 column을 가집니다.

-
qid : string
각 쿼리의 고유 식별자 -
query : string
사용자의 질문 내용 -
retrieval_gt : 2D list
검색된 정답 ID를 저장하는 문서 ID의 2차원 리스트 (1차원 string도 가능)
2차원 리스트인 이유는 질문에 대한 답변을 구성하기 위해 여러 문서의 정보를 조합해야 하기 때문
예를 들어 retrieval_gt = [['NewJeans1', 'Aespa1'], ['NewJeans2', 'Aespa2']]라면:
'NewJeans1'과 'Aespa1' 문서를 참고하거나
'NewJeans2'와 'Aespa2' 문서를 참고하면해당 질문에 대한 답변을 구성할 수 있다는 의미.
AutoRAG는 이 column을 사용하여 검색 성능을 평가하기 때문에 매우 중요합니다. -
generation_gt : list
LLM 모델이 생성할 것으로 기대하는 정답 목록입니다.
RAG 시스템의 Generation 단계에서 목표로 하는 이상적인 답변 텍스트를 의미하며, 시스템 평가 및 학습을 위한 지표로 활용됩니다.
- Corpus dataset
corpus dataset은 doc_id, contents, metadata 총 3가지 column을 가집니다.
-
doc_id : string
chunk된 각 passage의 고유 식별자 -
contents : string
실제 콘텐츠 내용
다양한 chunk 전략을 통해 chunk된 결과물 -
metadata : dictionary
chunk된 각 passage의 metadata 모음
2. Data 생성
Raw data -> Corpus data
Raw data (PDF 파일)

생성된 Corpus data
Corpus data 와 GPT4를 이용해 만든 QA data
prompt = """다음은 걸그룹 뉴진스에 관한 기사입니다.
기사를 보고 할 만한 질문을 만드세요.
반드시 뉴진스와 관련한 질문이어야 합니다.
만약 주어진 기사 내용이 뉴진스와 관련되지 않았다면,
'뉴진스와 관련 없습니다.'라고 질문을 만드세요.
기사:
{{text}}
생성할 질문 개수: {{num_questions}}
예시:
[Q]: 뉴진스는 몇 명인가요?
[A]: 뉴진스는 총 다섯 명입니다.
뉴진스와 관련이 없는 기사일 경우 예시:
[Q]: 뉴진스와 관련 없습니다.
[A]: 뉴진스와 관련 없습니다.
결과:
"""
@click.command()
@click.option('--corpus_path', type=click.Path(exists=True),
default=os.path.join('data', 'corpus_new.parquet'))
@click.option('--save_path', type=click.Path(exists=False, dir_okay=False, file_okay=True),
default=os.path.join('data', 'qa_new.parquet'))
@click.option('--qa_size', type=int, default=5)
def main(corpus_path, save_path, qa_size):
load_dotenv()
corpus_df = pd.read_parquet(corpus_path, engine='pyarrow')
llm = OpenAI(model='gpt-4o', temperature=0.5)
qa_df = make_single_content_qa(corpus_df, content_size=qa_size, qa_creation_func=generate_qa_llama_index,
llm=llm, prompt=prompt, question_num_per_content=1)
Tutorial : Config
node_lines:
- node_line_name: retrieve_node_line
nodes:
- node_type: retrieval
strategy:
metrics: [retrieval_f1, retrieval_ndcg, retrieval_map]
top_k: 3
modules:
- module_type: bm25
bm25_tokenizer: ko_kiwi
- module_type: vectordb
embedding_model: openai
- module_type: hybrid_rrf
target_modules: ('bm25', 'vectordb')
rrf_k: [3, 5, 10]
- module_type: hybrid_cc
target_modules: ('bm25', 'vectordb')
weights:
- (0.5, 0.5)
- (0.3, 0.7)
- (0.7, 0.3)
- module_type: hybrid_rsf
target_modules: ('bm25', 'vectordb')
weights:
- (0.5, 0.5)
- (0.3, 0.7)
- (0.7, 0.3)
- module_type: hybrid_dbsf
target_modules: ('bm25', 'vectordb')
weights:
- (0.5, 0.5)
- (0.3, 0.7)
- (0.7, 0.3)
- node_line_name: post_retrieve_node_line
nodes:
- node_type: prompt_maker
strategy:
metrics:
- metric_name: rouge
- metric_name: sem_score
embedding_model: openai
# - metric_name: bert_score
# lang: ko
modules:
- module_type: fstring
prompt:
- |
단락을 읽고 질문에 답하세요. \n 질문 : {query} \n 단락: {retrieved_contents} \n 답변 :
- |
단락을 읽고 질문에 답하세요. 답할때 단계별로 천천히 고심하여 답변하세요. 반드시 단락 내용을 기반으로 말하고 거짓을 말하지 마세요. \n 질문: {query} \n 단락: {retrieved_contents} \n 답변 :
- node_type: generator
strategy:
metrics: # bert_score 및 g_eval 사용 역시 추천합니다. 빠른 실행을 위해 여기서는 제외하고 하겠습니다.
- metric_name: rouge
- metric_name: sem_score
embedding_model: openai
# - metric_name: bert_score
# lang: ko
modules:
- module_type: openai_llm
llm: gpt-3.5-turbo
temperature: [0.1, 1.0]
batch: 8Tutorial : Code
🤖 E01. #AutoRAG - 처음 사용자를 위한 튜토리얼 by Markr.AI 김동규
실행 예시 : 7:54 부터
AutoRAG-tutorial-ko
또는
AutoRAG
Reference
