안녕하세요! 글또 8기 AI 연구 채널의 최민주 입니다 🙋🏻♀️
지난 포스팅에서 AI 시대의 기계번역에 대해 쭉 언급했는데요,
실제로 NMT 즉 신경망 기반 기계번역 실험 또는 서비스를 위해 고려할 점, 구현해야 할 점에 대해 이번 포스팅을 시작으로 앞으로 차근차근 설명해 보겠습니다.
딥러닝 모델을 학습시키려면 가장 먼저 데이터셋이 필요하겠죠.
이번 회차에는 데이터셋을 구축하기 위해 고려할 점에 대해 이야기하겠습니다.
1. Language pairs
지난 포스팅에서 NMT 의 특성에 대해 이렇게 설명했는데요,
NMT (Neural Machine Translation : 인공신경망(AI) 기반)
인공지능의 발전에 힘입어 새롭게 등장한 방법으로, 기존의 단어-단어 또는 구-구 번역과 달리 문장을 통째로 학습합니다.
번역 문장 쌍(ex : 한 - 영)을 이용해 번역 모델을 학습하는데, 아래 그림과 같이 Encoder 에 Source Language 문장을, Decoder 에 Target Language 문장을 넣어 모델을 학습시킵니다.
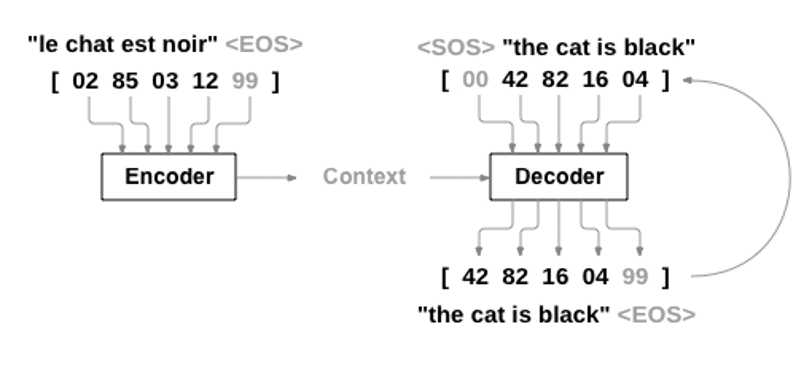
이는 다시 말하면, NMT 모델 학습용 데이터셋을 구성하는 데이터는
'번역할 문장 : 번역된 문장' 과 같이 각 문장이 병렬로 연결된 형태, 즉 1:1 쌍을 이루고
이 언어쌍, 즉 Language pair 들이 모여 하나의 데이터셋이 만들어집니다.
이 데이터셋을 'Parallel Corpus' 라고 부릅니다.
집에 가고 싶다 I want to go to home
나는 BTS를 좋아한다 I like BTS
...위 예시의 경우 한국어를 영어로 번역하고 있죠?
이 때 번역할 언어 (출발 언어라고도 합니다) 를 Source language (src),
번역되는 언어 (도착 언어라고도 합니다) 를 Target language (tgt) 라고 부릅니다.
기계번역을 수행할 첫 번째 단계, 어떤 언어를 src 와 tgt 로 할지 결정합니다.
다시 말해 Language pair 를 선정하는 것이죠.
2. Directions (Bi / Multi)
앞서 언급한 Language pair 에 추가로 한 가지를 더 고려하겠습니다.
어떤 언어를 어떤 언어로 번역할지, 번역 방향(direction)을 정해야 하는데요.
우선 한국어를 영어로 (KO -> EN), 즉 1:1 로 번역하는 경우
이를 Bi-lingual translation 이라고 부릅니다.
앞에서 설명한 Language pair 와 다를 바가 없죠?
하지만 한국어를 영어, 프랑스어, 중국어 등으로 번역하거나 (1:N)
반대로 영어, 프랑스어, 중국어를 한국어 한 종류로 번역하거나 (N:1)
한, 영, 프, 중 각각의 언어를 한, 영, 프, 중 모든 언어에 대응되게 번역할 수도 있겠죠. (N:N)
이를 Multi-lingual translation 이라고 부릅니다.
각각의 장단점을 간단히 언급하고 넘어가겠습니다.
- Bi-lingual (1:1)
- 장점 : Multi-Lingual 모델에 비해 번역 성능이 좋음
- 단점 : 번역해야 할 언어쌍의 종류가 많아진다면…!?
- 여러 개의 번역 모델을 각각 만들어야 한다 ☠️
- Multi-Lingual (1:N / 1:N / N:N)
- 장점
- 하나의 모델로 여러개의 언어 번역 가능
- Zero-Shot 가능
= 학습하지 않은 언어를 번역할 수 있음
- 단점 : Bi-lingual 모델보다는 번역 성능이 다소 떨어짐.
- Tip : 모델 학습 방법은 Bi-lingual 과 동일하며, src 쪽에 태그를 부착하여 src, tgt 을 명시한다.
-
ex
<ko2en> 집에 가고 싶다 I want to go to home <ko2fr> 나는 BTS를 좋아한다 J'aime BTS ...
-
- 장점
3. Domain
Text
어떤 도메인에 대해 번역할지 결정합니다.
도메인은 문체로 구분할 수도 있고, 주제에 따라 구분할 수 도 있습니다.
- 문어체
- 뉴스
- 가장 흔한(?) 도메인입니다.
- 뉴스 기사이다 보니 맞춤법도 정확하고 noise (오타, 문법 오류 등) 이 적은 편입니다.
- 따라서 크롤링 등의 방법으로 수집만 잘 한다면 noise filtering 에 드는 수고를 다소 덜 수 있습니다.
- 위키피디아
- 다양한 언어를 지원하고, 뉴스와 마찬가지로 noise 가 적습니다.
- 대표적으로 Meta (구 Fasebook) 에서 공개한 FLoRes 벤치마크가 위키피디아를 이용해 구축되었습니다.
- 다양한 언어를 지원하고, 뉴스와 마찬가지로 noise 가 적습니다.
- 뉴스
- 구어체
- 강연 스크립트, 영화 자막, 채팅체…
- 대표적인 데이터셋으로 TED, OpenSubTitles(영화 자막) 등이 있습니다.
- 문어체에 비해 noise 도 많고 정확히 번역하기가 까다로운 도메인입니다.
경우에 따라 noise filtering 도 필요하고요.
- 강연 스크립트, 영화 자막, 채팅체…
- 전문분야
- 의학/약학 (Biomedical), 법률(Legal), 특허(Patent), 계약서, 과학 기술…
- 문서에서 추출한 데이터로 만드는 경우가 많다 보니 상대적으로 noise 는 적은 편입니다.
- 대신 이 도메인은 전문분야에서 사용되는 어휘를 정확한 어휘로 번역하는 것이 관건입니다.
- 단어 사전과 Word Alignment, APE(사후교정) 등을 활용할 수 있습니다.
- 의학/약학 (Biomedical), 법률(Legal), 특허(Patent), 계약서, 과학 기술…
- Low-Resource (저자원)
- 이 경우는 2가지로 나눌 수 있는데, 특정 언어 자원이 적거나 도메인 특성상 데이터가 적은 경우입니다.
- 특정 언어 자원이 적은 경우 (구사자가 적거나 연구가 많이 진행되지 않아 데이터셋이 적은 경우)
- African language, Asian language...
- 특수한 도메인인 경우 : 한국어 특허, 의료/약학 도메인...
- 특정 언어 자원이 적은 경우 (구사자가 적거나 연구가 많이 진행되지 않아 데이터셋이 적은 경우)
- 이 경우는 2가지로 나눌 수 있는데, 특정 언어 자원이 적거나 도메인 특성상 데이터가 적은 경우입니다.
Speech
코로나 이후 원격으로 회의하는 경우가 많아짐에 따라 회의 중 실시간 통역 즉 음성 번역 연구가 진행되고 있습니다.
- Speech to Speech
- Speech to text (STT)
- Text to Speech (TTS)
etc
- 수화 - 음성 언어간 번역 태스크도 등장했습니다.
(WMT 2022 에서 처음으로 sign language 세션이 등장했습니다.)
4. Amount of Dataset
1-3 번에 따라 수집 가능한 데이터가 모델을 학습하기에 충분한 양인지 고려합니다.
만약 소수 언어 또는 특수한 도메인을 번역할 경우 Low-Resource 문제를 해결할 방법을 찾아야 합니다.
또한 도메인이 구어체와 같이 noise 가 많은 경우에는 데이터셋의 noise 를 제거하기 위해 필터링하는 과정에서 데이터가 많이 걸러질 것입니다.
따라서 초기 데이터셋 수집 시 목표보다 더 많은 양을 수집해야 합니다.
Conclusion
이번 포스팅에서는 번역 모델을 학습하기 위한 데이터셋을 구축할 때 고려해야 할 점에 대해 설명하였습니다.
다음 포스팅에서는 구체적으로 어떤 open dataset 이 있는지,
직접 데이터셋을 수집할 경우 어떤 방법을 시도할 수 있는지,
수집한 dataset 의 noise 를 어떻게 필터링할 수 있는지 소개해 보겠습니다.
