RAGAS
RAG 파이프라인을 평가하고 파이프라인 성능을 정량화하는 프레임워크
보통 머신러닝 태스크에서 모델 또는 파이프라인을 만들고 나면 이것이 얼마나 '잘' 만들어졌는지 평가하게 됩니다.
RAG 파이프라인의 경우에는 어떻게 성능을 평가하게 될까요?
RAGAS 는 RAG 의 평가지표 중 특히 Rule Base 지표들을 자동으로 계산하기 위해 만들어진 프레임워크입니다.
쉽게 말해 RAG 파이프라인을 구축한 후,
파이프라인의 input / output 을 이용해 평가 지표 계산에 필요한 데이터셋 (question, answer, context, ground truth) 을 만들고
RAGAS 는 이 데이터셋을 이용하여 함수 단 한줄로 각 평가 지표를 빠르게 자동으로 계산해 줍니다.
필요한 코드는 다음 코드가 전부입니다 🙌
# 평가지표 계산용 데이터셋
data_samples = {
'question': ...
'answer': ...
'contexts' : ...
'ground_truth': ...
}
dataset = Dataset.from_dict(data_samples)
# 평가지표 계산
evaluate(dataset, metrics = [평가지표명(ex: faithfulness), ... ])RAGAS score
RAGAS 주요 성능 메트릭을 살펴보면 크게 Retrieval, Generation 각 카테고리 별 측면에서 메트릭을 정의할 수 있습니다.
-
Retrieval 은 정확하고 일관성 있는 답변 생성을 위해 정확성, 정밀성, 관련성 측면에서 좋은 품질의 Context 정보 검색 여부를 살펴봅니다.
-
Generation은 검색한 Context 정보를 기반으로 LLM이 생성한 답변의 정확성 그리고 질문에 대한 명확한 이해를 통해 답변 생성 여부에 대한 성능을 평가합니다.

https://medium.aiplanet.com/evaluate-rag-pipeline-using-ragas-fbdd8dd466c1
Metrics
Generation
-
- 생성된 답변이 얼마나 사실(Context)에 근거한 정확한 답변인가요?
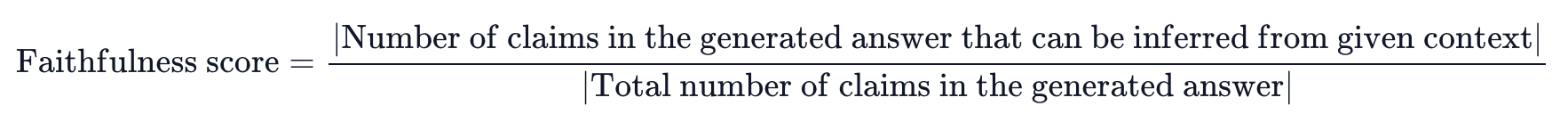
- 생성된 답변이 얼마나 사실(Context)에 근거한 정확한 답변인가요?
-
- 생성된 답변이 질문(공식문서: 주어진 프롬프트)에 얼마나 관련성이 있나요?
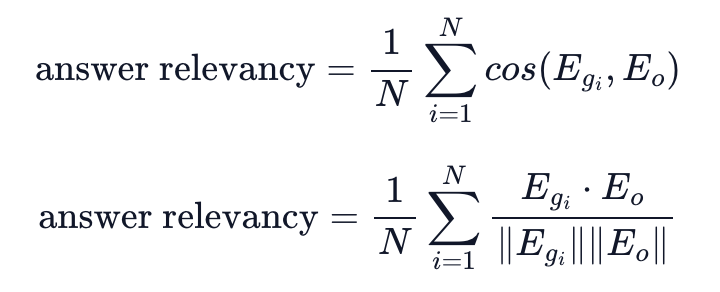
- 생성된 답변이 질문(공식문서: 주어진 프롬프트)에 얼마나 관련성이 있나요?
Retrieval
-
- 질문을 통해 답변을 생성하는데 필요한 맥락 정보(Context)를 검색할 수 있나요?
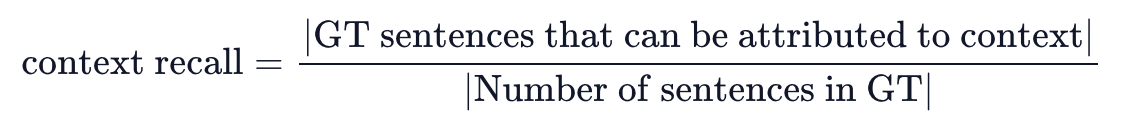
- 질문을 통해 답변을 생성하는데 필요한 맥락 정보(Context)를 검색할 수 있나요?
-
- 질문에 대한 맥락정보를 검색하여 가져온 Context 중, 질문에 대한 답변과 관련있는 문서가 얼마나 상위에 랭크되어 있나요?

- 질문에 대한 맥락정보를 검색하여 가져온 Context 중, 질문에 대한 답변과 관련있는 문서가 얼마나 상위에 랭크되어 있나요?
OpenLab - LLMOps, RAGAS LLM 평가지표 (Faithfulness)
Code
Quickstart + metric 추가
from datasets import Dataset
import os
from ragas import evaluate
from ragas.metrics import answer_relevancy, context_precision, faithfulness, context_recall, answer_correctness
os.environ["OPENAI_API_KEY"] = "sk-"
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
# Metric 추가
score = evaluate(dataset,metrics = [answer_relevancy, context_precision, faithfulness, context_recall, answer_correctness])
score.to_pandas()
print(score)Output 평균 (faithfullness 오차 있음.)


Evaluating: 100%|██████████| 10/10 [00:05<00:00, 1.73it/s]
{'answer_relevancy': 0.9592, 'context_precision': 0.5000, 'faithfulness': 0.0000, 'context_recall': 0.5000, 'answer_correctness': 0.8651}(faithfulness 정답은 원래 0.5)
Evaluating: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:04<00:00, 1.25s/it]
{'faithfulness': 0.5000, 'answer_correctness': 0.8651}추가 튜토리얼
RAG 파이프라인을 간단하게 구축하고 성능을 평가합니다.
기본 RAGAS dataset 에 RAG 파이프라인으로부터 얻는 2가지 요소를 추가합니다.
- answer = RAG의 생성값(결과값)
- context = Retriever 로 검색해서 가져온 context
- 데이터셋 로드 및 청킹
# Load the data
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
# Chunk the data
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)- RAG 파이프라인 구축
# Define LLM (GPT)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# If you want to use Ollama & Llama3:
# from langchain_community.chat_models import ChatOllama
# llm = ChatOllama(model="llama3:latest")
# Define prompt template
template = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use two sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
# Setup RAG pipeline
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)- RAGAS dataset 생성
from datasets import Dataset
questions = ["What did the president say about Justice Breyer?",
"What did the president say about Intel's CEO?",
"What did the president say about gun violence?",
]
ground_truths = [["The president said that Justice Breyer has dedicated his life to serve the country and thanked him for his service."],
["The president said that Pat Gelsinger is ready to increase Intel's investment to $100 billion."],
["The president asked Congress to pass proven measures to reduce gun violence."]]
answers = []
contexts = []
# Inference
for query in questions:
answers.append(rag_chain.invoke(query))
contexts.append([docs.page_content for docs in retriever.get_relevant_documents(query)])
# To dict
data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truths": ground_truths
}
# Convert dict to dataset
dataset = Dataset.from_dict(data)- RAGAS score 계산 (평가)
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
result = evaluate(
dataset = dataset,
metrics=[
context_precision,
context_recall,
faithfulness,
answer_relevancy,
],
)
# score 출력
print(result)
# DataFrame 생성
df = result.to_pandas()Output
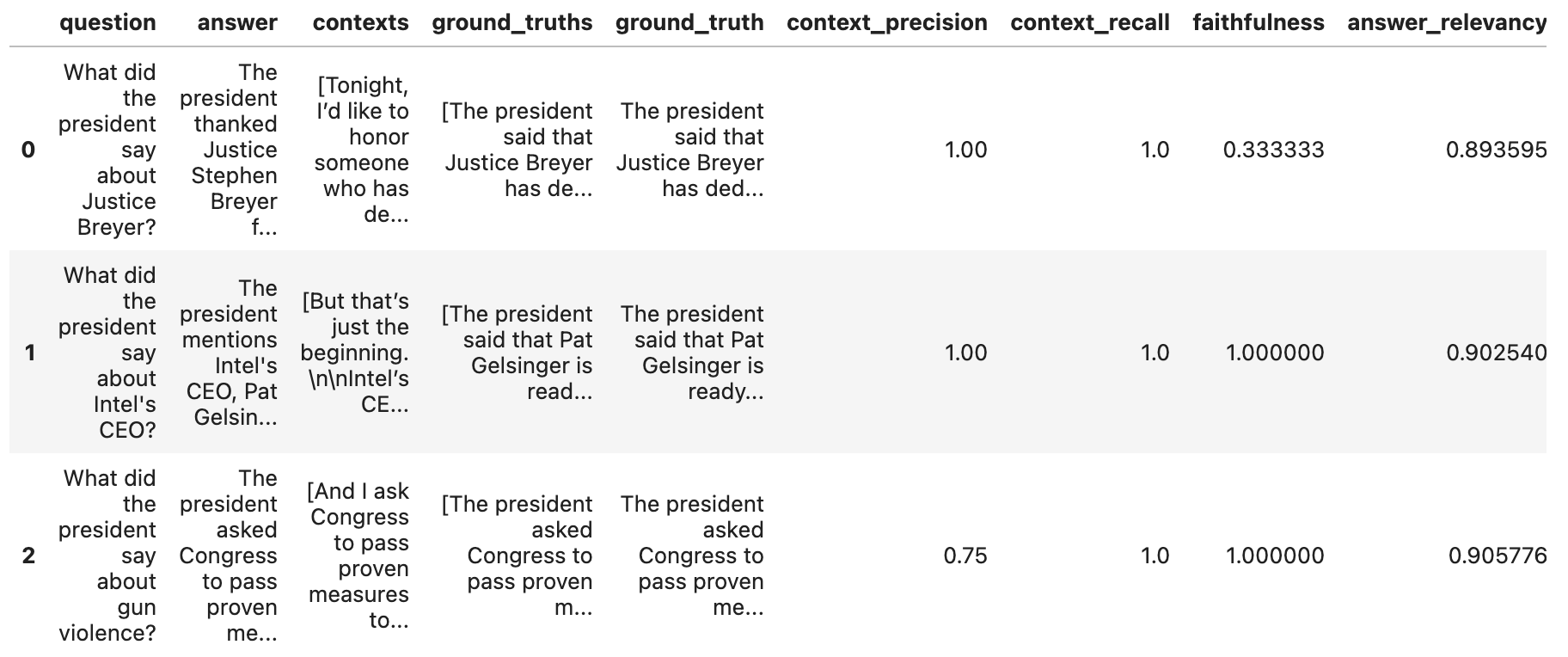
전체 코드 : RAGAS_Tutorial
원본 코드 출처 : Evaluating RAG Applications with RAGAs

4개의 댓글

안녕하세요. RAGAS 글 정말 잘 읽었습니다.
RAGAS를 이용할 때, query, context, ground_truth가 한국어로 되어 있으면 평가가 제대로 이루어지지 않는건가요?
안녕하세요. ragas 적용 관련해서 인터넷을 떠돌다가 이 글을 보게 됐습니다. 정말 잘 읽었습니다.
한가지 궁금한게 있어 질문드려요. 혹시 context와 ground_truth의 차이점이 어떻게 되나요?
현재 제가 문서에서 context 추출까지는 했는데 ground_truth의 개념이 잡기가 힘드네요 ㅠㅠ 간략하게나마 공유해주시면 감사하겠습니다! ㅎㅎ