

지난 10월 25일 솔트룩스에서 주최한 '개발자를 위한 AI 기술 Meet-up'에 오프라인으로 참석하여 강의를 들었다. 크게는 3가지의 주제가 있었고, 각 주제 당 4개의 강의가 있었다.
최신 인공지능을 소개하면서 동시에 솔트룩스와 자회사에서는 인공지능을 이용해 어떠한 서비스를 제공하고 있는지, 또 제공할 계획인지에 대한 내용이었다.이 중 재미있게 들었던 강의 주제 몇개를 정리해보려고 한다.
1부 초거대 언어모델의 sota와 미래전망
설명 가능한 인공지능과 서비스 응용
인류는 지식 학습, 의사소통으로 학습된 지식을 후대에게 전달, 그리고 협력을 통해 발전해옴
시대가 발전함에 따라 정보량이 점점 늘어나면서, 현재는 한 사람의 인지 능력으로 감당하기 어려울 만큼의 정보들을 습득하고 있음
어떻게 하면 개인의 인지 능력을 초월해서 폭발적으로 증가하고 있는 정보들을 개인이 사용할 수 있게 해서, 지적 노동의 생산성을 극대화시키면서 새로운 혁신을 만들어낼 수 있을까 ?
왜 인간은 두 부분의 서로 다른 뇌를 가지고 있을까 ?
흔히 좌뇌는 논리적인 영역을, 우뇌는 예술뿐만이 아니라 감정, 감각, 공간에 대한 패턴 이해 등을 담당한다고 함. 서로 다른 뇌는 협력할 수 있는 신경 다발을 가지고 정보를 교환함
인공지능도 이런식으로 발전하고 있다고 함 ➡️ 3 waves of AI
- first wave : 20년전부터 시작, 논리적 지식, 역지적 지식, 연혁적 추론을 다룸
- second wave : 최근 10년동안 딥러닝이라고 하는 심층 신경망을 통해 귀납적 추론과 insight와 implicit knowledge이라고 하는 암묵적 지식을 얻을 수 있는 방법들을 찾아가는 중
- third wave : first wave와 second wave에서의 두 가지 인공지능이 결합이 된 형태가 될 것 (Neuro-symbolic AI, ensemble AI) ➡️ 설명 가능한 인공지능을 만들어 내는 동시에 연혁적 추론과 귀납적 추론을 해내고, 인간이 하고 있는 지적 노동을 기계로 대체할 수 있는 방법을 찾아내고자함
위 과정 중에 있어서, 인공지능 시장에 3~4가지 정도의 큰 임팩트가 존재했음
- 그 중 하나가 초거대 인공지능 모델이라고 부르는 것들임
- 이 모델들의 시작은 Transformer라고 하는 모델에서 부터 시작됨
- “Attention is All you need”
- self-attention module 들을 쌓아올려서 실제 인간의 뇌에서 작동되는 feedback 시스템과 attention 시스템을 모방하려고 노력
- 대규모 언어 학습 및 언어를 생성하는 Encoding-Decoding 기술을 상용화 단계까지 이끌어냄
- 학습 가능한 파라미터 수도 폭발적으로 증가시켜서, 언어의 이해 뿐만 아니라 그림 같은 시각적인 요소를 이해할 수 있는 수준까지 발전하고 있음 (파라미터의 수 = 시냅수의 수)
지식 기반 대화 서비스를 위한 초거대 언어모델 상용화 방안
자연어 처리 분야에서 모델의 사이즈를 키우는 이유는 대화를 잘 하기 위해서임
모델의 크기가 커지면 대화 역량이 향상됨을 여태까지 나온 sota 모델들을 통해 알 수 있음 (LaMDA)
어떻게 하면 GPT-3를 더 잘 쓸 수 있을까 ?
- 단순한 prompt 보다는 명확한 지침을 줄 것
- 사람의 피드백이 담긴 reward model
- chain of thaught, 왜 해당 답이 나오는지 서술형 답안의 추리과정이 필요함
- 사실성 보장, 신뢰, 안전을 위해 검색을 활용할 것
- 각 문장에 대해 safety/sensible 등을 classifier를 활용하여 점수를 매길 것
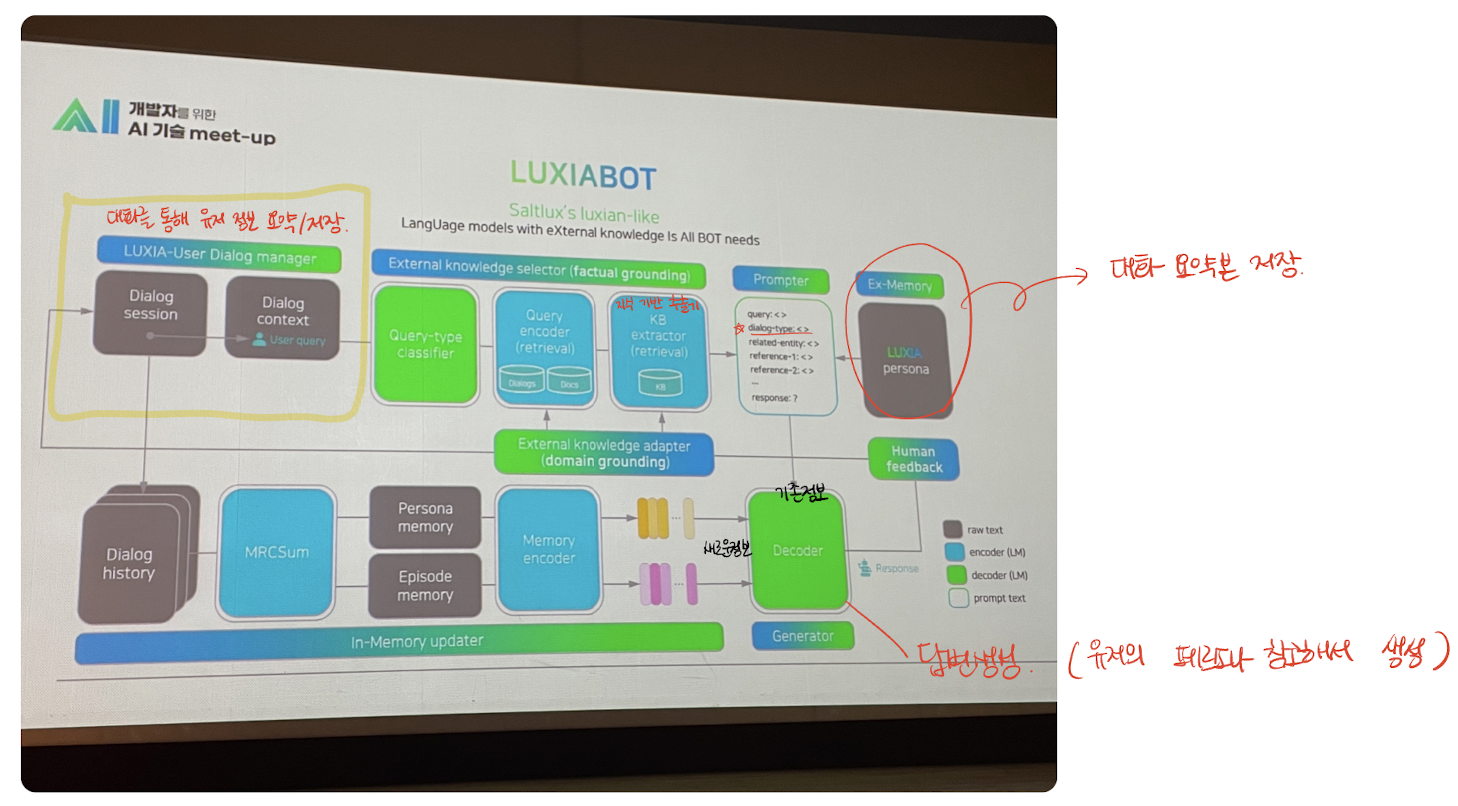
솔트룩스가 사용하는 LUXIABOT 모델의 구조
1부 패널 토의
Q. data-driven 모델의 문제점 중 하나인 data bias 를 제거하는 방법은 ?
A. human feedback
Q. 말투를 바꾸는 것은 transfer learning을 사용하고 있는지 ?
A. few-shot을 통해 가능
2부 생성적 AI와 멀티 모달 인지
메타 휴먼을 위한 소규모 데이터 기반 실감형 음성합성
다양한 심화 연구 주제 중 fast TTS, Robust, Adaptive 에 집중
자기 회귀 모델의 문제 (LSTM) -> 느리고 attention이 깨짐 -> non-autoregressive 로 해결
선명하고 자연스러운 음성, 다화자지원, 입력에 대한 robustness를 위해서 솔트룩스에서 하는 것
- 자체 데이터 구축
- fast speech 기반 모델에서 지금은 비자기회귀모델을 사용
Review
비록 모든 내용을 이해하지 못했지만, ai 기술의 이론 및 사용 사례, 더 잘 사용하기 위해서는 어떻게 해야는지 등의 내용을 공부할 수 있어서 좋은 경험이었다.
전체 강의는 아래 링크에서 볼 수 있다 !
https://www.youtube.com/watch?v=nZBdR1-3ymU)
