For Masked Language Modeling, I referred to keras’s official document: keras_masked_langauge_modeling
I got the dataset from : [Kaggle] A Million News Headlines
Masked Language Modeling is a popular modeling method used to pre-train BERT models.
It basically ‘masks’ certain parts of the corpus and train the model to guess the original word.
It is very effective in teaching the model the context.
Preparing Datasets
Following three methods are used to standardize and encode the corpus.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, "<br />", " ")
return tf.strings.regex_replace(
stripped_html, "[%s]" % re.escape("!#$%&'()*+,-./:;<=>?@\^_`{|}~"), ""
)
def get_vectorize_layer(texts, vocab_size, max_seq, special_tokens=["[MASK]"]):
vectorize_layer = TextVectorization(
max_tokens = vocab_size,
output_mode = "int",
standardize = custom_standardization,
output_sequence_length = max_seq
)
vectorize_layer.adapt(texts)
vocab = vectorize_layer.get_vocabulary()
vocab = vocab[2: vocab_size - len(special_tokens)] + ["[mask]"]
vectorize_layer.set_vocabulary(vocab)
return vectorize_layer
def encode(texts):
encoded_texts = vectorize_layer(texts)
return encoded_texts.numpy()Following method was used to mask certain parts of the encoded corpus.
def get_masked_input_and_labels(encoded_texts):
# Creates np.array that will be used to mask 15% of the encoded corpus
inp_mask = np.random.rand(*encoded_texts.shape) < 0.15
# Makes sure that special tokens like padding are not masked
inp_mask[encoded_texts <= 2] = False
# Keeps the original token for the masked tokens
labels = -1 * np.ones(encoded_texts.shape, dtype = int)
labels[inp_mask] = encoded_texts[inp_mask]
encoded_texts_masked = np.copy(encoded_texts)
# 80% of the selected tokens will be masked as [MASK],
# 10% will be masked into a random word,
# and 10% will not be changed.
# This helps model get a deeper understanding about the context,
# as it prevents the model from only paying attention to the [MASK] token.
inp_mask_2mask = inp_mask & (np.random.rand(*encoded_texts.shape) < 0.90)
encoded_texts_masked[inp_mask_2mask] = (mask_token_id)
inp_mask_2random = inp_mask_2mask & (np.random.rand(*encoded_texts.shape) < 1/9)
encoded_texts_masked[inp_mask_2random] = np.random.randint(3, mask_token_id, inp_mask_2random.sum())
# Sample_weights is needed for the model to calculate
# loss only with the masked tokens
sample_weights = np.ones(labels.shape)
sample_weights[labels == -1] = 0
y_labels = np.copy(encoded_texts)
return encoded_texts_masked, y_labels, sample_weightsThen I loaded the dataset and encoded them.
news_raw = pd.read_csv(os.path.join("data", "abcnews-date-text.csv"))
news_text_raw = news_raw["headline_text"]
vectorize_layer = get_vectorize_layer(
news_text_raw.tolist(),
config.VOCAB_SIZE,
config.MAX_LEN,
special_tokens=["[mask]"],
)
mask_token_id = vectorize_layer(["[mask]"]).numpy()[0][0]
x_all_encoded = encode(news_text_raw)
x_masked_train, y_masked_labels, sample_weights = get_masked_input_and_labels(x_all_encoded)
mlm_ds = tf.data.Dataset.from_tensor_slices(
(x_masked_train, y_masked_labels, sample_weights)
)
mlm_ds = mlm_ds.shuffle(1000).batch(config.BATCH_SIZE)The dataset was too large for the Google Colab server to handle, so I saved mlm_ds and uploaded to my google drive.
I then loaded the dataset and prefetched it.
vectorize_layer = get_vectorize_layer(
news_text_raw.tolist(),
config.VOCAB_SIZE,
config.MAX_LEN,
special_tokens=["[mask]"],
)
mask_token_id = vectorize_layer(["[mask]"]).numpy()[0][0]
#mlm_ds_small is created to test the model with short training time.
mlm_ds = tf.data.Dataset.load(os.path.join("data", "mlm_dataset_final"))
mlm_ds_small = mlm_ds.shard(num_shards=8, index=0)
mlm_ds = mlm_ds.prefetch(tf.data.AUTOTUNE)
mlm_ds_small = mlm_ds_small.prefetch(tf.data.AUTOTUNE)Preparing MLM Model
Same BERT model was used as before
class MultiHeadSelfAttention(Layer):
def __init__(self, embed_dim, num_heads=8, name=None):
super(MultiHeadSelfAttention, self).__init__(name=name)
self.embed_dim = embed_dim
self.num_heads = num_heads
self.projection_dim = embed_dim // num_heads
self.query_dense = Dense(embed_dim)
self.key_dense = Dense(embed_dim)
self.value_dense = Dense(embed_dim)
self.combine_heads = Dense(embed_dim)
self.supports_masking = True
def attention(self, query, key, value, mask=None):
score = tf.matmul(query, key, transpose_b=True)
dim_key = tf.cast(tf.shape(key)[-1], tf.float32)
scaled_score = score / tf.math.sqrt(dim_key)
if mask is not None:
mask = tf.cast(mask, dtype=scaled_score.dtype)
mask = mask[:, tf.newaxis, tf.newaxis, :]
scaled_score += (1.0 - mask) * -1e9
weights = tf.nn.softmax(scaled_score, axis=-1)
output = tf.matmul(weights, value)
return output, weights
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.projection_dim))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, inputs, mask=None):
batch_size = tf.shape(inputs)[0]
query = self.query_dense(inputs)
key = self.key_dense(inputs)
value = self.value_dense(inputs)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
attention, _ = self.attention(query, key, value, mask=mask)
attention = tf.transpose(attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(attention, (batch_size, -1, self.embed_dim))
output = self.combine_heads(concat_attention)
return output
class TransformerBlock(Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1, name=None):
super(TransformerBlock, self).__init__(name=name)
self.att = MultiHeadSelfAttention(embed_dim, num_heads)
self.ffn = tf.keras.Sequential([
Dense(ff_dim, activation="relu"),
Dense(embed_dim),
])
self.layernorm1 = LayerNormalization(epsilon=1e-6)
self.layernorm2 = LayerNormalization(epsilon=1e-6)
self.dropout1 = Dropout(rate)
self.dropout2 = Dropout(rate)
self.supports_masking = True
def call(self, inputs, training=False, mask=None):
# Attention Layer + Dropout
attn_output = self.att(inputs, mask=mask)
attn_output = self.dropout1(attn_output, training=training)
# Residual Connection + Normalization
out1 = self.layernorm1(inputs + attn_output)
# Feed Forward + Dropout
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
# Residual Connection + Final Normalization + Return
return self.layernorm2(out1 + ffn_output)
class TransformerEncoder(Layer):
def __init__(self, num_layers, embed_dim, num_heads, ff_dim, rate=0.1, name="transformer_encoder", **kwargs):
super(TransformerEncoder, self).__init__(name=name, **kwargs)
self.num_layers = num_layers
self.embed_dim = embed_dim
self.enc_layers = [TransformerBlock(embed_dim, num_heads, ff_dim, rate, name=f"Transformer_Block_{i}") for i in range(num_layers)]
self.dropout = Dropout(rate)
self.supports_masking = True
def call(self, inputs, training=False, mask=None):
x = inputs
for i in range(self.num_layers):
x = self.enc_layers[i](x, training=training, mask=mask)
return xThen, I created a MaskedLanguageModel to use custom loss calculation.
This ensures that only the masked tokens are included in the loss calculation and the padding tokens to not affect the result.
loss_fn = keras.losses.SparseCategoricalCrossentropy(reduction=None)
loss_tracker = keras.metrics.Mean(name="loss")
class MaskedLanguageModel(keras.Model):
def compute_loss(self, x=None, y=None, y_pred=None, sample_weight=None):
loss = loss_fn(y, y_pred, sample_weight)
loss_tracker.update_state(loss, sample_weight=sample_weight)
return keras.ops.sum(loss)
def compute_metrics(self, x, y, y_pred, sample_weight):
return {"loss": loss_tracker.result()}
@property
def metrics(self):
return [loss_tracker]Previously, I just structured model on a single cell, but for reproductivity, I defined a method for the masked language model.
First the inputs are embedded to fit the BERT model.
Then, the goes through the encoding layers (Attention Layers).
Finally, it is defined to be a MaskedLanguageModel so that the custom loss function is used.
The encoder_layer will be extracted in the future for transfer learning.
def create_masked_language_bert_model():
input_layer = Input(shape=(config.MAX_LEN,), dtype="int64")
word_embeddings = Embedding(
input_dim=config.VOCAB_SIZE,
output_dim=config.EMBED_DIM,
mask_zero=True
)(input_layer)
position_embeddings = PositionEmbedding(
sequence_length=config.MAX_LEN
)(word_embeddings)
embeddings = word_embeddings + position_embeddings
encoder_layer = TransformerEncoder(config.NUM_LAYERS, config.EMBED_DIM, config.NUM_HEAD, config.FF_DIM)
encoder_output = encoder_layer(embeddings)
mlm_output = Dense(config.VOCAB_SIZE, name="mlm_cls", activation="softmax")(encoder_output)
mlm_model = MaskedLanguageModel(input_layer, mlm_output, name="masked_bert_model")
optimizer = keras.optimizers.Adam(learning_rate=config.LR)
mlm_model.compile(optimizer=optimizer)
return mlm_modelTraining the model
Custom Generator was defined to help keep track of the model’s current performance by testing it with sample sentence ("I have watched this [mask] and it was awesome" for this case).
class MaskedTextGenerator(keras.callbacks.Callback):
def __init__(self, sample_tokens, top_k=5):
self.sample_tokens = sample_tokens
self.k = top_k
def decode(self, tokens):
return " ".join([id2token[t] for t in tokens if t != 0])
def convert_ids_to_tokens(self, id):
return id2token[id]
def on_epoch_end(self, epoch, logs=None):
prediction = self.model.predict(self.sample_tokens)
masked_index = np.where(self.sample_tokens == mask_token_id)
masked_index = masked_index[1]
mask_prediction = prediction[0][masked_index]
top_indices = mask_prediction[0].argsort()[-self.k :][::-1]
values = mask_prediction[0][top_indices]
for i in range(len(top_indices)):
p = top_indices[i]
v = values[i]
tokens = np.copy(sample_tokens[0])
tokens[masked_index[0]] = p
result = {
"input_text": self.decode(sample_tokens[0].numpy()),
"prediction": self.decode(tokens),
"probability": v,
"predicted mask token": self.convert_ids_to_tokens(p),
}
id2token = dict(enumerate(vectorize_layer.get_vocabulary()))
token2id = {y: x for x, y in id2token.items()}
sample_tokens = vectorize_layer(["I have watched this [mask] and it was awesome"])
generator_callback = MaskedTextGenerator(sample_tokens.numpy())
checkpoint_callback = ModelCheckpoint(
os.path.join("models", "model_weights_cp_best.weights.h5"),
save_best_only=True,
monitor="loss",
save_weights_only=True,
mode="min",
verbose=1
)bert_masked_model = create_masked_language_bert_model()
bert_masked_model.summary()This is the summary of the model:
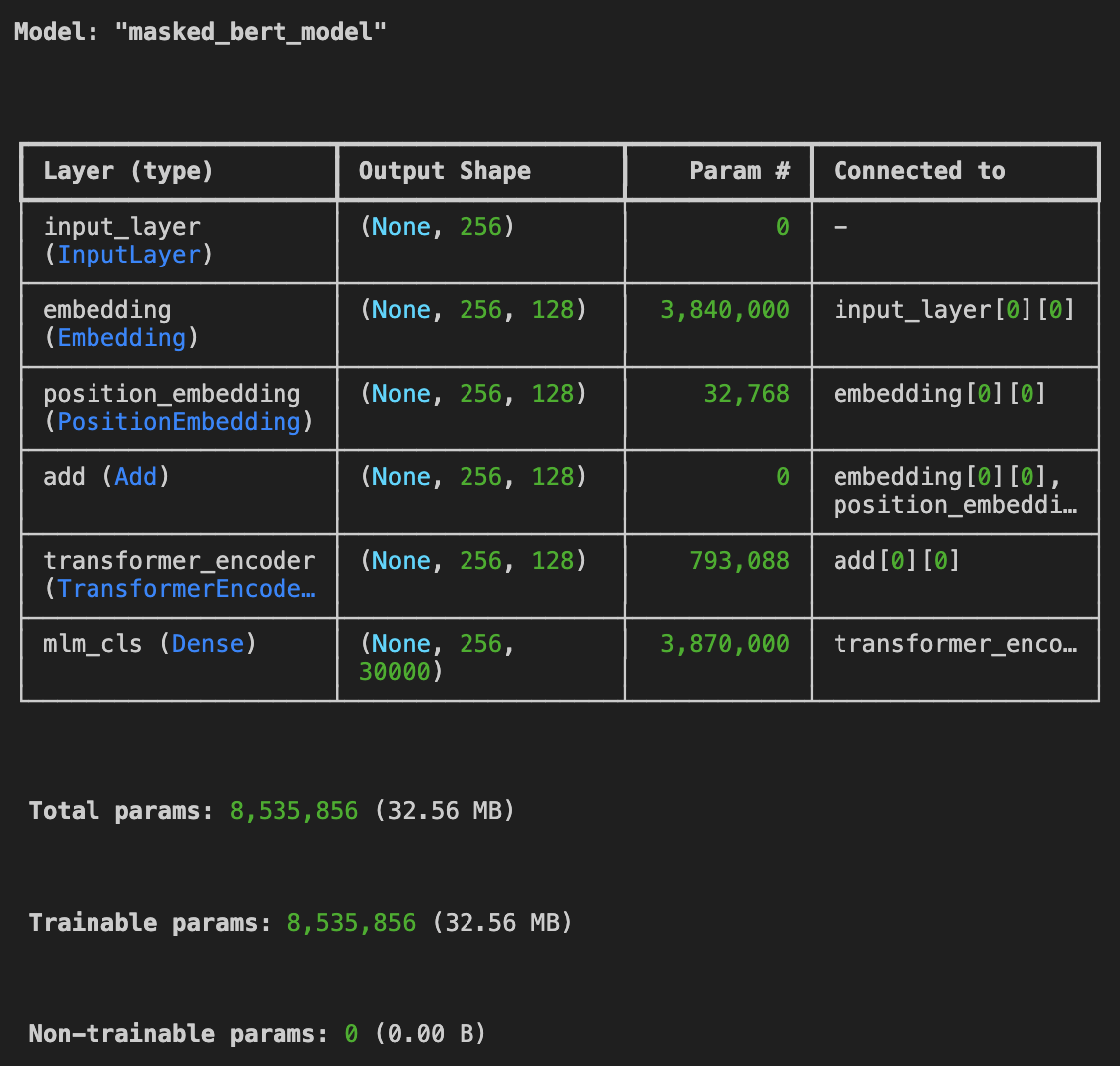
When the structure of the model is finalized, I plan on practiceing making the summary more explicit.
bert_masked_model.fit(mlm_ds_small, epochs=5, callbacks=[generator_callback, checkpoint_callback])I don't think my current model is not learning effectively.
It is only predicting the masked words as prepositions like "in", "the", "of", "and".
I plan to find out the reason behind it and resolve it within this week.
