Abstract
- 언어에 구애받지 않는 방법을 제안해 많은 합성 예제를 생성
- 두 번째 요소는 대규모 다국어 언어 모델(최대 11억 개의 매게 변수)를 사용
- 언어별 supervised set에 대한 fine-tuning이 완료되면 GEC 벤치마크에서 영어, 체코어, 독일어, 러시아어에서 SOTA
- GEC를 위한 새로운 baseline을 설정한후, cLANG-8 데이터셋을 공개해 결과를 쉽게 재현하고 액세스할 수 있도록
- 이 데이터셋은 많이 사용하지만 노이즈가 많은 LANG-8 데이터셋의 target을 clean하기 위해 gT5라고 하는 우리의 최고의 모델을 사용해 생성
- cLANG-8은 여러 fine-tuning 단계로 구성된 일반적인 GEC 학습 파이프라인을 크게 간소화
- 기성 언어 모델을 사용해 cLNAG-8에서 single fine-tuning 단계를 수행하면 이미 최고 성능의 영어용 gT5 모델보다 정확도가 향상
1. Introduction
- 최신 접근법은 GEC 작업을 단일 언어 text-to-text rewriting으로 간주하고 인코더 디코더 neural 아키텍처 사용
- 이러한 방법은 제대로 작동하려면 일반적으로 대규모 학습셋이 필요, 특히 영어 이외의 언어에는 부족
- GEC에 가장 크고 널리 사용되는 데이터셋 중 하나는 80개 언어를 포괄하며 언어 학습자들이 서로의 텍스트를 수정하여 만든 LANG-8 학습자 코퍼스
- 언어 분포가 치우쳐져 있음, 일본어와 영어가 각각 100만개 이상의 비문법적-문법적 문장 쌍을 가지지만, 10,000개 이상의 문자 쌍을 보유한 언어는 10개에 불과
- 또한 많은 예시에는 불필요한 의역과 오류 또는 불완전한 수정이 포함
- 학습 데이터의 양이 제한되어 GEC에 대한 합성 학습 데이터를 생성하는 접근법이 나옴
- 첫 번째 fine-tuning 단계로 합성 데이터를 사용하면 모델 정확도가 향상되는 것으로 나타났지만, GEC 모델의 개발과 공정한 비교를 어렵게 만드는 실질적인 문제 발생
- 합성 방법은 종종 언어별 튜닝(예: 언어별 하이퍼파라미터 및 철자 사전)이 필요
- 합성 데이터가 대상 평가 셋의 완전한 오류 분포를 포착할 수 없기 때문에 최종 모델은 multi-stage fine-tuning 과정을 거져 얻음
- 따라서 각 fine-tuning 단계마다 학습 속도와 학습 단계 수를 신중하게 선택해야 하므로 이전에 가장 잘 보고된 모델을 복제하고 이를 기반으로 구축하기가 어려움
- self-supervised 사전 학습을 활용하고 모델 크기를 늘리는 아이디어는 GEC에 제한된 범위에서만 적용되었음
- 이 논문에선 101개 언어를 포함하는 말뭉치에 대해 이미 사전 학습된 mT5를 base model로 채택
- 문법 문장을 자동으로 수정해 합성 학습 데이터를 생성해 101개 언어 모두에 대해 단일 모델을 학습하며 언어에 구애받지 않기 위해 특정 언어에 대한 선행 학습을 전혀 사용X
- 사전 학습 후에는 사용 가능한 언어(수춘 개에서 수만개 까지 다양)에 대한 supervised GEC data에 대해 모델을 더욱 fine-tuning
- 또한 모델 크기를 6천만개에서 11억 개의 매개변수로 확장하는 효과 실험
- 연구 결과를 많이 이용할 수 있도록 하기 위해 가장 큰 gT5모델을 사용해 자주 사용되지만 노이즈가 많은 LANG-8 데이터셋의 target을 정제하여 얻은 cLANG-8 데이터셋 공개
- cLANG-8에서만 fine-tuning된 T5가 원래 LANG-8 데이터셋에서 학습한 모델보다 성능 우수해서 GEC 모델을 학습하는 복잡한 다단계 프로세스를 단순화한다는 것을 보여줌
- 언어에 구애받지 않는 간단한 사전 학습 목표만으로도 SOTA GEC 달성할 수 있음을 보여줌
- 모델 크기가 GEC에 미치는 영향
- 추가적인 fine-tuning 없이도 SOTA를 얻을 수 있는 LANG-8 기반의 대규모 다국어 GEC 데이터셋을 공개해 학습 설정을 크게 간소화
2. Model
- 우리 모델은 광범위한 NLG 작업에서 SOTA 결과를 달성하는 것으로 입증된 Transformer encoder-decoder 모델은 T5의 다국어 버전인 mT5를 기반
- 이 작업에선 base(600M parameter), xxl(13B parameter)를 사용
2.1 mT5 사전 학습
- mT5는 101개 언어를 포괄하고 약 500억 개의 문서로 구성된 Common Crawl의 하위 집합인 mC4 말뭉치에 대해 사전 학습을 거침
- 사전 학습 목표는 autoregressive seq2seq 모델에 대한 마스킹 언어 목표의 변형인 span-prediction task를 기반으로 함
- 모든 mT5 모델은 1024개의 최대 시퀀스 길이를 가진 1024개의 입력 시퀀스 batch에 대해 1M 단계에 대해 학습되었으며, 이는 약 1T개의 토큰에 해당
- 모든 실험에선 공개적으로 사용 가능한 mT5 및 T5 checkpoint 사용(섹션 4만 해당)
2.2 GEC 사전 학습
- mT5의 span-prediction 목표는 특수 토큰을 사용해 텍스트를 삽입해야 하는 위치를 표시하기 때문에 추가 fine-tuning 없이는 모델이 GEC를 수행X
- 또 다른 제약 조건은 mT5가 문장이 아닌 단락에 대해 학습되었음
- 따라서 mC4 말뭉치의 모든 단락을 문장으로 분할
- 다음 작업의 조합을 사용해 각 문장을 corrupt
a) 토큰의 span 삭제
b) 토큰 교체
c) 문자 span 삭제
d) 문자 교체
e) 문자 삽입 (같은 passage의 문자를 삽입하여 다른 알파벳의 문자를 삽입하지 않도록)
f) 단어 소문자
g) 첫 번째 대문자
-> 문자를 변경할 수 있음
ex)
Input: Simple recipe for Multingual Grammatical Correction Error
Target: A Simple Recipe for Multilingual Grammatical Error Correction
- 예제의 약 2%는 손상되지 않은 채로 남겨두어 모델이 입력이 문법적일 수도 있다는 것을 학습하도록
- 101개 언어에 모두 적용하기 어렵기 때문에 정교한 텍스트 corruption은 사용X
3. gT5: Large Multilingual GEC Model
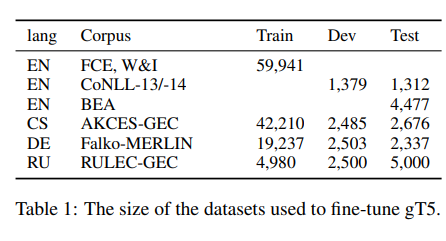
Fine-tuning datasets
영어의 경우 FCE, W&I corpora에 대해 사전학습된 모델을 fine-tuning
Training Regime
- 모두 mT5 사전 학습 모델을 기반으로 함(Section 2.1)
a) GEC 사전 학습 데이터(Section 2.2)와 fine-tuning data(Section 3)를 혼합하는 방법
b) 사전 학습과 fine-tuning 예제를 혼합하되 다른 접두사로 주석을 다는 방법
c) 수렴까지 GEC 사전 학습을 먼저 사용한 후 fine-tuning하는 방법을 실험
c가 계산 비용이 가장 많이 들지만 가장 좋은 결과
- GEC 사전 학습과 fine-tuning은 0.001의 일정한 learning rate 가짐
- 사전 학습은 development set의 정확도가 떨어질 때까지 수렴 및 fine-tuning이 이루어지며,이는 200 steps 또는 800K개의 예제 또는 7 epoch후에 발생
Results
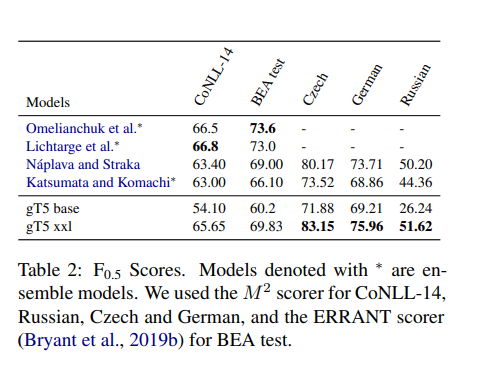
- 영어의 경우 CoNLL-14(휴리스틱셋으로 모델 출력을 후처리해서 토큰화 불일치 수정)github와 BEA 테스트의 표준 마크로 평가하고, 개발 셋은 CoNLL-13을 사용(Table 1)
- 다른 언어의 경우 학습 데이터와 연관된 테스트 및 개발 셋을 그대로 사용
- Table 2는 모든 언어에 대한 결과
- 먼저 base 모델 크기가 현재 SOTA 모델 보다 낮음을 알 수 있음
- 이는 모델 용량이 101개 언어를 모두 커버하기에 충분하지 않기 때문에 예상되는 결과
- 따라서 더 큰 xxl(11B) 모델을 사용해 새로운 SOTA를 생성
- 영어에 대한 개발셋의 성능을 살펴보면 분산이 크고 학습이 매우 빠르게 과적합됨
- 이는 영어의 경우 학습 및 개발/테스트 셋 도메인이 잘 정렬되지 않았음을 시사
- 다음 섹션4에선 접근 방식을 더욱 세분화해서 영어에 대한 SOTA 얻음
