Abstract
- Transformer encoder써서 간단하고 효과적인 GEC sequence tagger 소개
- 오류가 있는 말뭉치와 없는 말뭉치를 조합해 fine-tune
- 입력 토큰을 target correction에 매핑하기 위해 custom token-level transformation 설계
- best single-model/ensembel GEC tagger는 CoNLL-2014(test)에서 F0.5 65.3/66.5,
BEA-2019(test)에서 F0.5 72.4/736. - 추론 속도는 transformer 기반 보다 최대 10배 빠름
1. Introduction
- 오류가 있는 문장은 source 언어, 오류가 없는 문장은 target 언어
- 이제 연구의 초점은 Transformer-NMT 기반 GEC 시스템을 사전 학습학기 위한 합성 데이터를 생성하는 쪽으로 이동
- NMT 기반 GEC 시스템은 실제 배포가 어려움
- 느린 inference 속도
- 많은 양의 학습 데이터
- 해석 가능성, 설명 가능성 <- 문법적 오류 유형 분류와 같은 수정을 설명하기 위한 추가 기능 필요
- 본 논문에선 시퀀스 생성부터 시퀀스 태킹까지 작업을 단순화해서 문제 해결
- GEC 시퀀스 태킹 시스템은 합성 데이터에 대한 사전 학습
- 오류가 잇는 병렬 말뭉치에 대한 fine-tuning
- 마지막으로 오류가 있는 병렬 말뭉치와 오류가 없는 병렬 말뭉치의 조합에 대한 fine-tuning
Related work
LaserTagger는 BERT 인코더와 autoregressive Transformer decoder를 결합해 토큰 유지, 토큰 삭제, 토큰 앞에 문구 추가 등 세가지 주요 편집 작업 예측
반면 우리 시스템에서 디코더는 softmax layer
PIE는 tokenlevel edit 작업을 예측하는 반복적 시퀀스 태깅 GEC 시스템
이 접근 방식이 본 논문 방식과 가장 유사하지만 다음 작업이 다름
1. custom g-transformation 개발: token-level 편집을 통해 (g)rammatical 오류 수정
일반 토큰 대신 g-transformation을 예측하면 GEC 시퀀스 태깅 시스템의 일반화를 개선
2. fine-tuning 단계를 오류만 있는 문장에 대한 fine-tuning과 오류가 없는 문장이 모두 포함된 소규모 고품질 데이터셋에 대한 추가 fine-tuning 두 단계로 세분화
3. 사전 학습된 Transformer 인코더를 GEC 시퀀스 태깅 시스템에 동합해 우수한 성능 달성.
XLNet과 RoBERTa의 인코더는 다른 세 가지 SOTA transformer encoder(ALBERT, BERT, GPT-2)를 능가
2. Datasets
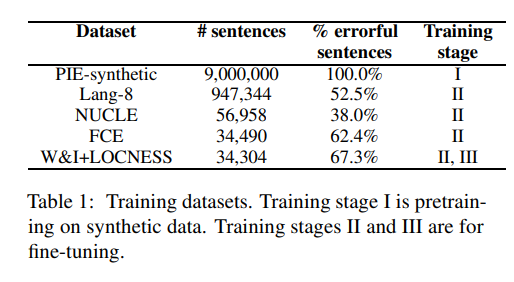
Synthetic data
1단계 사전 학습에선 합성적으로 생성된 문법 오류가 있는 9백만 개의 병렬 문장 사용
Training data
2단계, 3단계를 fine-tuning하기 위해 다음 데이터 사용
- 싱가포르 국립대 학습자 영어 말뭉치(NUCLE), Lang-8 학습자 영어 말뭉치, 캠브리지 학습자 말뭉치의 공개적으로 사용 가능한 부분인 FCE 데이터셋, Write & Improve + LOCNESS 말뭉치 등
Evaluation data
CoNLL-2014 test set, BEA-2019 dev and test set
3. Token-level transformation
- custom token-level transformation 를 개발해 source token 에 적용해 대상 텍스트를 복구
Basic transformation
가장 일반적인 token-level edit 작업 수행
예를 들어, 현재 토큰을 변경하지 않음(tag KEEP), 현재 토큰 삭제(tag DELETE), 현재 토큰 옆세 새 토큰 추가(tag APPEND_) 또는 현재 토큰 를 다른 토큰 (tag REPLACE)로 바꿈
g-transformation
현재 토큰의 대/소문자 변경(CASE tags), 현재 토큰과 다음 토큰을 하나의 토큰으로 병합(MERGE tags), 현재 토큰을 두 개의 새 토큰으로 분할(SPLIT tag)하는 등의 작업별 작업 수행
또한 NOUN NUMBER과 VERB FORM 변환의 태그는 토큰의 문법적 속성을 인코딩
예를 들어, 이러한 변환에는 단수 명사를 복수로 또는 그 반대로 변환하거나 정규/불규칙 동사의 형태를 변경해 다른 수나 시제를 표현하는 것 등이 포함
