Abstract
과학 연구의 근본적인 목표는 이노가 관계에 대해 배우는 것이다. 그러나 예측 작업에 더 중점을 둔 자연어 처리(NLP)에서 인과 관계는 중요성을 갖지 못했다. 이러한 구분은 희미해지고 있다. 그럼에도 불구하고, NLP의 인과 관계에 대한 연구는 고유한 속성을 가진 텍스트 도메인에 인과 관계 추론을 적용하는 데 있어 통일된 정의, 벤치마크 데이터셋 및 chanllenge와 기회에 대한 명확한 설명 없이 도메인 전반에 흩어져 있다. 이 실험에서 우리는 학분 분야 전반에 걸친 연구를 통합하고 더 넓은 NLP 환경에 위치시킨다. 텍스트가 결과, 처리 또는 혼란을 해결하기 위해 사용되는 설증을 포함하여 텍스트로 인과 관계를 추정하는 통계적 문제를 소개합니다. 또한 NLP 모델의 강건성, 공정성 및 해석 가능성을 개선하기 위해 인과 추론의 잠재적 사용을 탐구합니다.
1 Introuduction
NLP의 효과가 증가함에 따라 학제간(여러 학문 분야가 관련된) 협업을 위한 흥미로운 새로운 기회가 창출되었으며, NLP 기술을 광범위한 외부 연구 분야에 도입하고 새로운 데이터와 작업을 NLP에 통합했다. 이러한 학제간 협력에서 가장 중요한 연구 질문의 대부분은 인과 관계의 추론과 관련이 있다. 예를 들어, 임상의는 새로운 약물 치료법을 권장하기 전에 약물이 질병 진행에 미치는 인과적 영향을 알고자 합니다. 인과 추론은 개입을 통해 생성된 조건법적 서술(counterfactual-어떤 문장의 첫절이 사실과 정반대인 것을 서술할 경우의 표현법 [만약 내가 알고 있었더라면 등])에 대한 질문을 포함한다 : 만약 우리가 그들에게 약을 주었더라면 환자의 질병 진행은 어땠을까요? 아래에서 설명하는 바와 같이 관찰 데이터를 통해 인과 관계는 약물 복용 여부와 관찰된 질병 진행 간의 상관관계와 동일하지 않습니다. 현재 텍스트가 아닌 데이터셋을 사용하여 유효한 추론을 하는 기술에 대한 방대한 문헌이 있지만, 이러한 기술을 자연어 데이터에 적용하면 새로운 근본적인 문제가 발생한다.
반대로, 많은 고전적인 NLP 애플리케이션에서의 주요 목표는 정확한 예측을 하는 것이다 : 통계적 상관관계는 기본 인과 관계에 관계없이 허용된다. 그러나 NLP 시스템이 점점 더 도전적이고 고위험 시나리오에 배치됨에 따라 학습 및 테스트 데이터가 동일하게 분포된다는 일반적인 가정에 의존할 수 없으며 해석할 수 없는 블랙박스 예측 변수에 만족하지 않을 수 있다. 이 두가지 문제 모두에 대해 인과관계는 앞으로 유망한 경로를 제공한다 : 데이터 생성 프로세스의 인과 구조에 대한 도메인 지식은 보다 강력한 예측 변수로 이어지는 귀납적 편향을 제안할 수 있으며, 예측 변수 자체에 대한 인과적 관점은 내부 작동에 대한 새로운 통찰력을 제공할 수 있다.
이 논문의 핵심 주장은 인과관계와 NLP의 연관성을 심화시키는 것은 사회과학과 NLP 연구자 모두의 목표를 발전시킬 수 있는 잠재력이 있다는 것이다. 인과 관계와 NLP의 교차점을 두 영역으로 나눈다 : 텍스트에서 인과적 관계 효과를 추정하고 인과 관계 형식을 사용하여 NLP 방법을 보다 안정적으로 만든다.
Example 1.
온라인 포럼에서는 사용자가 프로필에 선호하는 성별을 여성 또는 남성 아이콘으로 표시할 수 있다. 자신을 여성 아이콘으로 표시한 사용자가 게시물에서 '좋아요'를 덜 받는 경향이 있음을 알아차렸다. 프로필에 성별 정보를 허용하는 그들의 정책을 더 잘 평기하기 위해 묻는다 : 여성 아이콘을 사용하면 게시물의 인기가 떨어집니까?
Ex 1은 게시물이 받는것과 같은(결과)에 대한 여성 성별 신호(처리 treatment)의 인과적 영향을 다룬다(https://aclanthology.org/2020.acl-main.474/). counterfactual 질문은 : 만약 우리가 게시물의 성별 아이콘을 조작할 수 있었다면, 그 게시물은 얼마나 많은 좋아요를 받았을까요?
성별 아이콘과 좋아요의 수사이에서 관찰된 상관관계는 일반적으로 인과관계와 일치하지 않는다 :
대신 treantment와 결과 모두와 상관관계가 있는 교란 요인으로 알려진 다른 변수에 의해 유도된 가짜 상관관계일 수 있다. 한 가지 가능한 혼란은 각 게시물의 주제이다 : 여성 아이콘을 선택한 사용자가 작성한 게시물은 특정 주제(예: 출산 또는 월경)에 대해 더 자주 작성될 수 있으며, 그러한 주제는 광범위한 온라인 플랫폼의 청중으로부터 많은 좋아요를 받지 못할 수 있다. section 2에서 볼 수 있듯이, 교란으로 인해 인과 관계를 추정하려면 가정이 필요하다.
Ex 1은 텍스트가 인과 관계의 관련 교란 요소를 인코딩하는 설정을 강조한다. 교란 설정으로서의 텍스트는 텍스트 데이터로 만들 수 있는 많은 인과적 추론 중 하나이다. 텍스트 데이터는 관심있는 결과 또는 treatment를 인코딩할 수 있다. 예를 들어, 성별 신호가 게시물이 받는 답글의 감정에 어떤 영향을 미치는지 (결과로서의 텍스트) 또는 글쓰기 스타일이 게시물이 받는 좋아요에 어떤 영향을 미치는지 (텍스트 처리)에 대해 궁금해할 수 있다.
NLP Helps Causal Inference.
텍스트 데이터를 사용한 인과 추론에는 일반적인 인과 추론 설정과 구별되는 몇 가지 문제가 포함된다 : 텍스트는 고차원이며 주제와 같은 의미론적으로 의미 있는 요소를 측정하기 위해 정교한 모델링이 필요하며 인과적 질문이 해당하는 개입을 공식화하기 위해 신중한 생각을 요구한다. topic model에서 contextual embedding에 이르기까지 모델링 언어를 중심으로 한 NLP의 발전은 인과 관계를 추정하기 위해 텍스트에서 필요한 정보를 추출하는 유망한 방법을 제공한다. 그러나 NLP 방법의 사요이 유효한 인과 관계 추론으로 이어지도록 하려면 새로운 가정이 필요하다. 우리는 텍스트에서 인과 관계를 추정하는 기존 연구에 대해 논의하고 Section 3에서 이러한 도전과 기회를 강조한다.
Example 2.
한 의료 연구 센터에서 환자 의료 기록의 textual narratives(본문의 서술)에서 임상 진단을 감지하는 분류기를 구축하려고 한다. 기록은 여러 병원 사이트에 걸쳐 집계되며, 이는 대상 임상 상태의 빈도와 서술 스타일이 모두 다르다. training set에 없는 사이트의 기록에 classifier를 적용하면 정확도가 떨어진다. 사후 분석에서 서식 지정 마커와 같이 겉보기에 관련이 없어 보이는 기능에 상당한 비중을 두고 있음을 나타낸다.
Ex.1과 마찬가지로 Ex 2.도 counterfactual 질문을 포함한다 : 실제 임상 상태를 고정한 상태에서 병원 사이트 변경에 개입하면 classifier의 예측이 변경됩니까? 우리는 classifier가 작문 스타일이 아니라 임상적 사실을 표현하는 문구에 의존하기를 원한다. 그러나 training data에서, 사이트가 교란 변수로 작용하기 때문에 임상 조건과 작문 스타일은 잘못된 상관 관계가 있다. 예를 들어, 사이트는 위치나 특수성 때문에 대상 임상 상태에 직면할 가능성이 더 높을 수 있으며, 해당 사이트는 각 본문의 시작 부분에 상용구 텍스트와 같은 고유한 텍스트 기능을 사용할 수도 있다. training set에서 이러한 feature들은 레이블을 예측하지만 새로운 사이트의 배포 시나리오에서는 유용하지 않다. 이 예에서는 병원 사이트가 confounder 역할을 한다 : 텍스트의 일부 features과 예측 대상 사이에 거짓된 상관 관계를 생성한다.
Ex 2는 강건성 부족이 NLP 방법을 신뢰할 수 없게 만드는 방법을 보여준다. 관련 문제는 NLP 시스템이 종종 블랙박스이기 때문에 텍스트의 인간이 해석 가능한 features이 관찰된 예측으로 이어지는지 이해하기 어렵다는 것이다. 이 설정에서, 우리는 텍스트의 일부(예: 토큰의 일부 시퀀스)가 NLP 방법의 출력(예: 분류 예측)을 유발하는지 알고 싶다.
Causal Models Can Help NLP
NLP 방법이 제기하는 강건성과 해석 가능성 문제를 해결하려면 상관관계를 활용하는 것을 넘어서는 모델을 학습하기 위한 새로운 기준이 필요하다. 예를 들어, 정답 레이블을 고정한 상태에서 형식을 변경하는것과 같이 텍스트에 대한 특정 변경 사항에 대해 변하지 않는 예측 변수를 워한다. 강력하고 해석 가능한 NLP 방법을 구축하는 서비스에서 새로운 기준을 개발하기 위해 인과관계를 사용하는 것은 상당한 가능성이 있다. 텍스트를 사용한 인과 추론의 잘 연구된 영역과 달리, 최근의 실증적인 성공에 의해 동기 부여가 잘 되었음에도 불구하고, 인과 관계 및 NLP 연구의 영역은 잘 이해되지 않는다. Section 4에서 우리는 기존 연구를 다루고 NLP를 개선하기 위해 인과 관계를 사용하는 것과 관련된 과제와 기회를 검토한다.
이 논문은 인과 추론 내에서 텍스트 데이터의 역할을 검토하는 소규모 조사를 따른다. 우리는 인과 관계와 NLP의 교차점을 텍스트가 적어도 하나의 인과 변수인 인과 관계를 추정하는 두 개의 별개의 연구 라인으로 분리하고(Section 3) 인과 관계 형식을 사용하여 NLP 방법의 강건성과 해석 가능성을 향상시키는(Section 4) 더 넓은 관점을 취한다. 본 논문을 읽고 나면 독자가 다음 사항을 폭넓게 이해할 수 있을 것으로 기대합니다 : 다양한 유형의 인과적 질문과 그들이 제시하는 문제; 텍스트 데이터 및 NLP 방법 작업에 고유한 통계적 및 인과적 문제; 그리고 NLP 방법을 개선하기 위해 텍스트에서 효과를 추정하고 인과관계를 적용하는 데 문제가 있다.
2. Background
이 논문의 두가지 문제(강력하고 설명 가능한 예측을 위한 인과 관계 추정 및 인과 관계 형식)는 모두 인과 추론을 포함한다. 인과 추론의 핵심 요소는 관심 개입을 기반으로 counterfactual을 정의하는 것이다. Section 1의 동기를 부여하는 예를 통해 아이디어를 설명할 것이다.
Example 1은 온라인 포럼 게시물과 그들이 받는 좋아요 Y의 수를 포함한다. 게시물이 '여성 아이콘(T=1)'을 사용하는지 아니면 '남성 아이콘(T=0)'을 사용하는지 나타내기 위해 이진 변수 T를 사용한다. 이 예에서 게시물 아이콘 T를 'treatment'로 보지만, treatment가 무작위로 할당되었다고 가정하지 않는다(게시물 작성자에 의해 선택될 수 있다). counterfactual 결과 Y(1)는 게시물이 여성 아이콘을 사용했다면 받았을 좋아요 수를 나타냅니다. counterfactual 결과 Y(0)는 유사하게 정의된다.
인과 추론의 근본적인 문제는 분석 단위에 대해 Y(0)과 Y(1)을 동시에 관찰할 수 없다는 것이다. 이 문제는 인과적 추론을 통계적 추론보다 어렵게 만들고 식별 가정 없이는 불가능하게 만든다 Section 2.2
Example 2는 임상 본문 서술 X를 입력으로 사용하고 진단 예측을 출력하는 학습된 classifier f(x)를 포함한다. 텍스트 X는 의사의 진단 Y를 기반으로 작성되었으며, 병원 Z에서 사용되는 작문 스타일에도 영향을 받는다. 레이블 Y를 고정한 상태에서 병원 Z에 개입하고 싶다. counterfactual 서술 X(z)는 진단을 고정한 상태에서 병원을 값 z로 설정했다면 관찰했을 텍스트이다. counterfactual 예측 f(X(z))는 counterfactual 검토 X(z)를 입력으로 제공했다면 학습된 classifier가 생성했을 출력
2.1 Causal Estimands
(1)
분석가는 일반적으로 counterfactuals을 포함하는 인과적 추정치라(causal estimands)고 불리는 관심 대상 인과 수량을 지정하는 것으로 시작한다. Example1에서 가능한 인과적 추정치 중 하나는 average treatment effect(ATE)이며, 여기서 기대치는 게시물의 생성적 분포를 초과한다. ATE는 게시물이 남성 아이콘 대신 여성 아이콘을 사용했을 경우 평균적으로 게시물에 받을 수 있는 좋아요 수의 변화로 해석될 수 있다.
관심의 또 다른 가능한 인과적 효과는 conditional average treatment effect(CATE)이다.
(2)
여기서 G는 모집단의 미리 정의된 부분군이다. 예를 들어 G는 정치적 주제에 대한 모든 게시물이 될 수 있다. 이 경우 CATE는 해당 게시물이 여성 아이콘 대신 남성 아이콘을 사용했다면 평균적으로 정치적 주제에 대한 게시물이 받았을 좋아요 수의 변화로 해석할 수 있다. CATE는 다양한 모집단 하위 그룹에서 인과 효과의 이질성을 정량화하는 데 사용된다.
2.2 Identification Assumptions for Causal Inference
우리는 인과적 추론에 필요한 가정을 설명하기 위해 예제1과 식(1)의 ATE에 초점을 맞출 것이다. 우리가 ATE에 초점을 맞추고 있지만, 모든 인과적 추정에 대해 어떤 형태로든 관련 가정이 필요하다. 변수는 이 섹션에서 이전에 정의된 것과 동일하다.
Ignorability
treatment 할당은 counterfactual 결과와 통계적으로 독립적이어야 한다.
{ 0, 1 } (3)
이 가정은 treatment 할당과 관찰된 결과 Y 간의 독립성과 동일하지 않다.
예를 들어, 무시 가능성이 유지된느 경우 는 추가적으로 처리가 효과가 없음을 의미한다.
랜덤화된 treatment 할당은 설계상 무시 가능성을 보장한다. 예를 들어 예제1에서 동전을 던져 각 게시물의 아이콘을 선택하고, 게시물 작성자가 변경하지 못하도록 하여 무시가능성을 보장할 수 있다.
2.3 Causal Graphical Models
조건부 무시가능성(ignorability)을 보장하는 변수 X 집합을 찾는 것은 어려운 일이며 연구 중인 영역의 인과 관계에 대해 신중하게 평가된 몇 가지 가정을 해야 합니다. 인과적 방향성 비순환 그래프(DAG)를 사용하면 이러한 가정을 공식적으로 인코딩하고 무시 가능성이 만족되는 조건을 충족한 후 변수 X 집합을 도출할 수 있다.
인과 DAG에서 에지 X->Y는 X가 Y를 유발할 수도 있고 휴발하지 않을 수도 있음을 의미한다. X와 Y사이에 간선이 없다는 것은 X가 Y를 발생시키지 않다는 것을 의미한다. 변수 사이의 양방향 점선 화살표는 관측되지 않은 일부 변수를 통해 잠재적으로 상관 관계가 있음을 나타낸다.
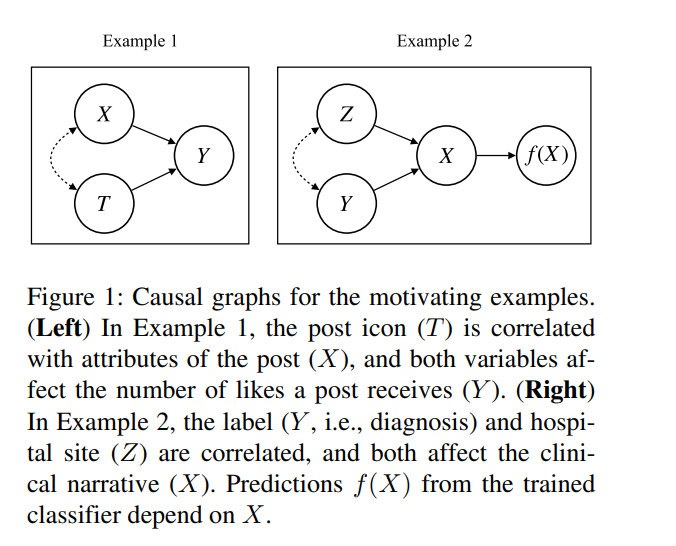 그림 1: 동기 부여 예제에 대한 인과 그래프. (왼쪽) 예시1에서 게시물 아이콘(T)은 게시물의 속성(X)과 상관 관계가 있으며, 두 변수 모두 게시물이 받는 좋아요 수(Y)에 영향을 미친다. (오른쪽) 예제2에서 라벨(Y, 즉 진단)과 병원 위치(Z)는 상관관계가 있으며 둘 다 임상 서술(X)에 영향을 미친다. 학습된 classifier의 예측 f(x)는 X에 따라 달라진다.
그림 1: 동기 부여 예제에 대한 인과 그래프. (왼쪽) 예시1에서 게시물 아이콘(T)은 게시물의 속성(X)과 상관 관계가 있으며, 두 변수 모두 게시물이 받는 좋아요 수(Y)에 영향을 미친다. (오른쪽) 예제2에서 라벨(Y, 즉 진단)과 병원 위치(Z)는 상관관계가 있으며 둘 다 임상 서술(X)에 영향을 미친다. 학습된 classifier의 예측 f(x)는 X에 따라 달라진다.
그림 1은 예제1과 예제2에 대해 가정한 인과적 DAG를 보여준다. 인과적 DAG가 주어지면 d-separation 알고리즘을 사용하여 변수 쌍 간의 인과적 의존성을 도출할 수 있다. 그런 다음 이러한 종속성을 사용하여 주어진 treatment, 결과 및 조건 변수 X 집합에 대해 조건부 무시 가능성이 유지되는지 여부를 평가할 수 있다. 예를 들어, 그림 1의 왼쪽 DAG에서 게시물 아이콘 T는 X를 조건으로 하지 않는 한 좋아요 수 Y와 무관하지 않다. 오른쪽 DAG에서 예측 f(x)는 서술 X를 조건화한 후에도 병원 Z와 독립적이지 않다.
3. Estimating Causal Effects with Text
섹션2에서 treatment, 결과 및 교란 요인을 직접 측정할 때 인과 추론에 대한 가정을 설명했다. 이 섹션에서는 인과 분석에 필요한 변수가 텍스트에서 자동으로 추출될 때 인과 가정이 어떻게 복잡해지는지에 대한 새로운 논의를 제공한다. 이러한 열린 문제를 해결하려면 유효한 인과 관계 결론을 도출하는 데 필요한 가정이 무엇인지 이해하기 위해 NLP와 인과 관계 추정 커뮤니티간의 협력이 필요하다. 우리는 텍스트가 confounder,결과 또는 treatment인 설정에서 이전 접근 방식과 미래의 과제를 강조하지만, 이 논의는 많은 텍스트 기반 인과 문제에 광범위하게 적용된다.
이러한 문제를 명확히 하기 위해 가상의 온라인 포럼이 플랫폼에서 괴롭힘을 이해하고 줄이기를 원한다고 가정하여 예제 1을 확장할 것이다. 이러한 질문의 대부분은 인과관계가 있다 : 성별 아이콘이 사용자가 받는 괴롭힘에 영향을 미칩니까? 정지(suspension) 기간이 길수록 사용자가 다른 사람을 괴롭히는 경향이 줄어듭니까? 다른 사람의 기분을 상하게 하지 않도록 게시물을 다시 작성하려면 어떻게 해야 합니까? 각 경우에 언어의 측면을 측정하기 위해 NLP를 사용하는 것은 모든 인과 분석에 필수적이다.
3.1 Causal Effects with Textual Confounders
예제1로 돌아가서, 플랫폼이 여성 아이콘을 가진 사용자가 다른 사용자로부터 괴롭힘을 받을 가능성이 더 높다고 가정한다. 이러한 발견은 새로운 중재 전략에 대한 계획에 상당한 영향을 미칠 수 있다. 우리는 저자의 아이콘에 대한 처리(성별 신호)를 무작위화할 수 없거나 원하지 않을 수 있으므로, 괴롭힘 받는 성별 신호의 인과 효과는 다른 변수에 의해 혼동(confounded)될 수 있다. 이 게시물의 주제는 중요한 혼돈 요인이 될 수 있다 : 일부 주제 영역은 여성 아이콘을 가진 더 많은 비율의 사용자에 의해 논의될 수 있으며, 논쟁의 여지가 많은 주제는 더 많은 괴롭힘을 유발할 수 있다. 게시물의 텍스트는 주제에 대한 증거를 제공하므로 confounder 역할을 한다.
Previous Approaches
이 설정의 주요 아이디어는 NLP 방법을 사용하여 텍스트에서 confounding 측면을 추출한 다음 성향 점수 일치와 같은 추정 접근 방식에서 해당 측면을 조정하는 것이다. 그러나 이러한 방법이 인과적 가정을 위반하는 방법과 시기는 여전히 미해결 문제이다.
한 세트의 방법은 고차원 텍스트 데이터를 저차원 변수 세트로 줄이는 비지도 차원 축소 방법을 적용한다. 이러한 방법에는 topic model, 임베딩 방법 및 auto-encoder와 같은 잠재 변수 모델이 포함된다.
두 번째 방법 세트는 supervised NLP 방법을 사용하여 텍스트 confounder를 조정한다.
...
Challenges for Causal Assumptions with Text
ㅁ작위 처리가 없는 설정에서 텍스트 confounding을 조정하는 NLP 방법은 특히 조건부 무시 가능성에 대한 강력한 설명을 필요로 한다 (식 4). confounding의 모든 측면은 모델에 의해 측정되어야 한다. 이 가정은 테스트할 수 없기 때문에, 이를 정당화하거나 위반할 경우 이론 및 경험적 결과를 이해하기 위해 도메인 전문 지식을 찾아야 한다.
텍스트가 confounder인 경우, 높은 차원성으로 인해 긍정성(positivity)이 유지될 가능성이 낮다. 텍스트에서 confounder의 저차원 표현을 추출하는 접근 방식의 경우에도 긍정성이 우려된다. 예를 들어 예제1에서 게시물은 작성자의 선택된 성별 아이콘을 거의 완벽하게 인코딩하는 문구를 포함할 수 있다. 학습된 표현이 다른 confounding 측면과 함께 이 정보를 포착한다면, 성별 텍스트를 고정한 상태에서 성별 아이콘을 변경하는 것을 상상하는 것은 거의 불가능하다.
3.2 Causal Effects on Textual Outcomes
플랫폼 관리자가 커뮤니티 지침을 위반한 사용자를 하루 또는 일주일 동안 정지하도록 선택할 수 있다고 가정하고, 우리는 어떤 옵션이 일시 정지된 사용자의 독성을 줄이는데 가장 큰 효과가 있는지 알고 싶다. 각 사용자의 게시물에 대해 우리가 수집할 수 있다면, 독성에 대한 실제 사람의 주석이 이상적인 결과 변수가 될 것이다. 그런 다음 Section 2의 논의에 따라 이러한 결과를 사용하여 ATE를 계산한다. 독성 결과에 대한 실제 레이블 대신 NLP 방법을 사용하여 텍스트에서 결과를 추출하는 경우 서스펜션 분석이 복잡하다. 핵심 문제는 고차원 텍스트를 저차원 toxicity 척도로 추출하는 것이다.
Challenges for Causal Assumptions with Text
Section 2에서 treatment assignment를 무작위화하는 것이 ignorability와 positivity을 보장할 수 있음을 보았다 : 그러나 무작위화를 하더라도 일관성을 만족시키기 위해 더 신중한 평가가 필요하다. 사용자에게 정지 기간을 임의로 할당한 다음 해당 사용자가 돌아와서 게시를 계속하면 클러스터링 방법을 사용하여 이전에 정지된 사용자중 toxic 및 non-toxic 그룹을 발견한다고 가정한다. 서스펜션 길이의 인과 효과를 추정하기 위해, 학습된 클러스터링 모델을 사용하여 결과 변수를 추론한다. 정지 정책이 실제로 게시 행동에 인과적 영향을 미친다고 가정하면, 클러스터링 모델은 학습 데이터의 모든 게시물에 의존하기 때무에, 각 게시물에 영향을 미치는 treatment assignment에도 의존한다. 따라서 결괄르 추론하기 위해 모델을 사용할 때 각 사용자의 결과는 다른 모든 사용자의 treatment에 따라 달라진다. 이는 잠재적인 결과가 다른 단위의 treatment 상태에 의존하지 않는다는 일관성의 가정을 위반한다. 이것은 우리의 인과 추정에 대한 이론적 근거를 약화시키고, 실제로는 다른 무작위 처리 할당이 다른 treatment effect 추정치로 이어질 수 있음을 의미한다.
이러한 문제는 데이터 샘플에 대해서만 측정값을 개발한 다음 별도의 보류된 데이터 샘플에 대한 영향을 추정하여 해결할 수 있다.
3.3 Causal Effects with Textual Treatments
세 번째 예로 우리가 게시물을 불쾌하게 만드는 것이 무엇인지 이해하고 싶다고 가정해보자. 이를 통해 플랫폼은 사용자가 자신의 게시물의 어구를 바꾸도록 권장하는 제안을 제공할 수 있다. 여기서 우리는 독자가 텍스트를 공격적으로 보고하는지 여부에 대한 텍스트 자체의 인과적 영향에 관심이 있다. 이론적어르 counterfactual Y(t)는 임의의 t에 대해 정의되지만, 텍스트의 특정 측면에 대한 탐색으로 제한될 수 있다. 예를 들어 2인치 대명사를 사용하면 게시물이 신고될 가능성이 더 높습니까?
Previous Approaches
텍스트의 효과를 연구하는 한가지 접근법은 treatment discovery를 포함한다 : 잠재적 주제 또는 n-gram과 같은 어휘적 특징과 같은 텍스트의 해석 가능한 특징을 생성함으로써 결과와 인과적으로 연결될 수 있다. 예를 들어, Fong과 Grimmer는 유권자 평가를 주도하는 후보자 전기의 특징을 발견했고, Prrizant 등은 마케팅 자료에서 매출 증가에 영향을 미치는 글쓰기 스타일을 발견했으며, Zhang등은 긍정적인 정신 건강 상담으로 이어지는 대화 경향을 발견했다.
또 다른 접근법은 실험 중에 개입되거나 관찰 연구를 위해 텍스트에서 추출된 특정 잠재적 특성의 인과 효과를 추정하는 것이다. 예를 들어, Gerber는 시민 의무에 호소하는 것이 투표율에 미치는 영향을 연구했다. 이 설정에서 요인은 측정 모델이 필요한 텍스트의 잠재적 속성이다.
Challenges for Causal Assumptions with Text
이 환경에서 긍정성과 일관성을 보장하는 것은 여전히 어려운 과제이지만, 조건부 무시 가능성을 평가하는 것은 특히 어렵다. treatment가 2인칭 대명사의 사용이지만, 이 treatment가 결과 사이의 관계가 텍스트의 다른 특성(예:공손함)에 의해 혼동된다고 가정한다. 조건부 무시 가능성을 유지하려면 모든 confounder에 대한 텍스트와 조건을 추출해야 하며, 이는 텍스트의 다른 많은 측면에서 처리를 분리할 수 있다고 가졍해야 한다. 이러한 유려는 독자들에게 무작위로 텍스트를 할당하므로써 피할 수 있지만 비현실적일 수 있다. 텍스트를 무작위로 할당할 수 있더라도 독자의 정치적 이념이나 취향 등 잠재 속성으로 인한 교란 요인이 없다고 가정해야 한다.
3.4 Future Work
다음으로 NLP 연구자가 텍스트에서 인과 추론을 용이하게 하기 위한 주요 과제와 기회를 강조한다.
Heterogeneous Effects
텍스트는 사람마다 다르게 읽고 해석합니다 : NLP 연구자들은 주석자의 이질적인(여러 다른 종류들로 이루어진) 인식의 맥락에서 이 문제를 연구했다. 인과 추론 분야에서 서로 다른 하위 그룹이 서로 다른 인과 효과를 경험한다는 생각은 이질적 처리 효과로 공식화되며, 서로 다른 하위 그룹에 대한 조건부 편균 처리 효과 식(2)를 사용하여 연구된다. treatment가 관심 있는 결과에 강한 영향을 미치는 하위 그룹을 발견하는 것도 흥미로울 수 있다. 예를 들어, 콘텐츠 조정 정책과 같은 처리과 효과적인 경우를 특징으로 하는 텍스트 기능을 식벽하고자 할 수 있다. Wager 와 Athey는 랜덤 포레스트를 기반으로 이기종 효과를 추정하는 유연한 접근법을 제안했다. 그러나 표 데이터를 염두에 두고 개발된 이러한 접근 방식은 고차원 텍스트 데이터에 대해 계산적으로 불가능 할 수 있다. 인과 관계가 다른(다양한) 하위 그룹을 포착하는 텍스트 기능을 발견하기 위해 NLP ㅏㅂㅇ법을 확장할 수 있는 기회가 있다.
Representation Learning
텍스트에서 인과 관계를 추론하려면 텍스트에서 저차원 특징을 추출해야 한다. 설정에 따라 저차원 기능은 confounding 정보, 결과 또는 treatment를 추출하는 작업을 수행한다. 텍스트에서 잠재된 측면을 측정해야 할 필요성은 텍스트 표현 학습 분야와 연결된다. 텍스트 표현 학습 접근법의 일반적인 목표는 언어를 모델링 하는 것이다. 인과 추론을 위해 표현 학습을 적용하는 것은 열린 문제다 : 예를 들어, 우리는 1. 긍정성이 충족되는지 2. confounding 정보가 폐기되지 않는지 3. noisily 측정된 결과나 treatment가 정확한 인과 관계 추정을 가능하게 하는지 확인하기 위해 목적 함수를 증가시킬 수 있다.
Benchmarks
벤치마크 데이터셋은 예측 모델을평가할 수 있는 공유 메트릭을 생성하여 머신 러닝을 발전시켰다. 개인에 대한 no real-word를 결코 얻을 수 없고 실제 인과 효과를 관찰할 수 없다는 인과 추론의 근본적인 문제로 ㅇ니해 현재 실제 텍스트 기반 인과 추정 벤치마크가 없다. 그러나 실제 공변량이 treatment와 결과를 생성하는데 사용되는 반합성 데이터셋에 대한 텍스트 기반 추정 바법을 평가하는데 약간의 진전이 있었다라고 논의한다. Wood-Doughty 등은 인과 방법을 평가할 수 있는 제어된 합성 텍스트 생성을 위해 대규모 언어 모델을 사용했다. 공개된 문제는 합성 데이터에서 잘 수행되는 방법이 실제 데이터로 일반화되는 정도이다.
Controllable Text Generation
무작위 실험을 진행하거나 합성 데이터를 생성할 때 연구자들은 데이터의 경험적 분포를 사용하여 결정을 내린다. 만약 우리가 약물이 두통을 예방하는지 여부를 연구하고 있다면 '합리적인' 복용량을 무작위로 할당하는 것이 합리적이다. 그러나 인과 관계 질문이 자연어와 관련된 경우 도메인 지식은 작은 '합리적인' 텍스트셋을 제공하지 않을 수 있다. 대신 몇 가지 요구사항을 충족하는 샘플 텍스트에 대한 제어 가능한 텍스트 생성으로 전환할 수 있다. 이러한 방법은 NLP에서 오랜 역사를 가지고 있다 : 예를 들어, 대화 에이전트는 예의바른것으로 인식되면서 사용자의 질문에 대답할 수 있어야 한다. 어떤 텍스트 측면이 텍스트를 불쾌하게 만드는지 이해하려는 처리 예제로서의 텍스트에서, 이러한 방법은 특정 잠재적 측며에서만 다른 텍스트를 무작위로 할당할 수 있는 실험을 가능하게 할 수 있다. 예를 들어 텍스트의 내용을 고정한 상태에서 텍스트의 스타일을 변경할 수 있다. 최근 연구는 인과저 관점에서 텍스트 생성을 탐구했지만, 향후 연구는 인과적 추정을 위해 이러하 방법을 개발할 수 있다.
4. Robust and Explainable Predictions from Causality
지금까지 텍스트 데이터가 존재할 때 인과 관계를 추정하기 위해 NLP 도구를 사용하는 데 중점을 두었다. 이 섹션에서는 자연어 이해, 조작 및 생성과 같은 전통적인 NLP작업을 해결하는 데 도움이 되는 인과 추론을 사용하는 것을 고려한다.
언뜻 보기에 NLP는 인과적 아이디어에 대한 필요성이 거의 없어 보일 수 있다. 이 분야는 점점 더 많은 용량의 뉴럴 아키텍처를 사용하여 대규모 데이터셋에서 상관 관계를 추출하는 데 놀라운 발전을 이루었다. 이러한 아키텍처는 원인, 효과 및 confounder을 구분하지 않으며 인과 관계를 식별하려고 시도하지 않는다 : feature는 원하는 출력과 직접적인 인과 관계가 없는 경우에도 강력한 예측 변수가 될 수 있다.
그러나 상관관계 예측 모델은 신뢰할 수 없다 : spurious correlation(shortcut)에 걸려 out-of-distribution(OOD) 설정에 오류가 발생할 수 있다; 사용자 그룹 간에 허용할 수 없는 성능 차이르 보일 수 있다; 그리고 그들의 행동은 너무 이해하기 어려워서 중대한 결정에 통합할 수 없을지도 모른다; 이러한 각각의 결점은 잠재적으로 인과적 관점에 의해 해결될 수 있다: 관측치와 레이블 사이의 인과 관계에 대한 지식은 가짜 상관관계를 공식화하고 그 영향을 완하하는 데 사용될 수 있다(Section 4.1); 인과 관계는 또한 송정성 조건을 지정하고 추론하기 위한 언어를 제공한다(Section 4.2); 그리고 예측을 설명하는 작업은 counterfactual 측면에서 자연스럽게 공식화될 수 있다(Section 4.3); 이러한 문제에 대한 안과 관계를 적용하는 것은 여전히 활발한 연구 영역이며, 우리는 이전의 다양한 선행 작업 간의 암묵적인 연관성을 강조하여 촉진하려고 한다.
4.1 Learning Robust Preictors
NLP 분야는 spurious correlation에 대한 우려가 점점 커지고 있다. 인과적 관점에서 두 조건이 충족될 때 spurious correlation이 발생한다. 첫째, feature X와 label Y 모두에 대해 (학습 데이터에서) 정보를 제공하는 factor Z가 있어야 한다. 둘째, Y와 Z는 일반적으로 유지되는 것이 보장되지 않는 방식으로 학습 데이터에 종속되어야 한다. 예측 변수 f: x-> y는 z에 대한 정보를 전달하는 X의 부분을 사용하는 방법을 학습할 것이다(Z는 Y에 대한 정보를 제공하기 때문). 예측 변수가 배포될 때 Y와 Z 사이의 관계가 변경되면 오류가 발생할 수 있다.
이 문제는 환자 기록의 텍스트에서 의학적 상태를 예측하는 작업인 예제2에 설명되어 있다. 학습셋은 대상 임상 조건(Y)의 빈도와 서술 방식(X로 표현)이 모두 다른 여러 병원에서 가져온거다. 이러한 데이터에 대해 학습된 예측 변수는 개별 병원 내에서 진단을 예측하는데 쓸모가 없는 경우에도 병원(Z)에 대한 정보를 전달하는 텍스트 기능을 사용한다. spurious correlation는 또한 자연어 추론과 같은 작업의 벤치마크에서 아티팩트로 나타난다. 여기서 부정 단어는 크라우드소싱 학습 데이터의 의미론적 모순과 상관관계가 있지만 더 자연스러운 조건에서 생성된 텍스트에서는 상관관계가 없다.
이러한 관찰로 인해 예측 변수가 "잘못되 이유로 옳지 않음"을 보장하기 위한 새로운 평가 방법론에 대한 여러 제안이 나왓다. 이러한 평가는 일반적으로 두 가지 형태를 취한다 : 예측이 레이블과 인과 관계가 없는 pertubation(혼란)에 의해 영향을 받는지 여부를 평가하는 불변성 테스트 및 어떤 의미에서 실제 레이블을 뒤집는데 필요한 최소한의 변화가 되어야 하는 pertubation을 적용하는 민감도 테스트. 두 유형의 테스트 모두 인과적 관점에서 동기를 부여할 수 있다. 불변성 검정의 목적은 에측 변수가 counterfactual 입력에서 다르게 동작하는 여부를 결정하는 것이다. 여기서 Z는 분석가가 Y와 인과관계가 없다고 믿는 속성을 나타낸다. 이러한 counterfactual에 걸쳐 예측이 변하지 않는 모델은 경우에 따라 Y와 Z사이의 관계가 다른 테스트 분포에서 더 잘 수행될것으로 예상할 수 있다. 마찬가지로 민간도 테스트는 라벨 Y가 변경되지만 X에 대한 다른 모든 인과적 영향은 일정하게 유지되는 counterfactuals 의 평가로 볼 수 있다. Y와 spuriously correlated가 있는 feature는 factual X와 counterfacutl 에서 동일하다. 거짓 상관관계에만 의존하는 예측 변수는 factual 인스턴스와 counterfactual 인스턴스 사례 모두에 올바르게 레이블을 지정할 수 없다.
민감도 및 불변성 테스트를 통과하는 예측 변수를 학습하기 위해 많은 접근법이 제안되었다. 이러한 접근법의 대부분은 인과적 관점에 의해 명시적 또는 암시적으로 동기 부여된다. 데이터의 인과 구조에 대한 지식을 학습 목표에 통합하는 방법으로 볼 수 있다.
4.1.1 Data Augmentation
불변성과 민감도 테스트를 통과하는 예측 변수를 학습하기 위해 대중적이고 간단한 방식은 data augmentation이다: counterfactual 인스턴스를 도출하거나 구성하여 학습 데이터에통합. counterfactual이 confounding factor Z에 대한 혼란을 포함할 때, counterfactual 쌍에 대한 예측의 불일치를 명시적으로 처벌하기 위해 학습 목표에 용어를 추가하는데 도움이 될수 있다.
예를 들어 f는 예측 함수이다. ...
counterfactual 예제는 여러 가지 방법으로 생성될 수 있다 : (1) 수동 사후 처리 (2) 휴리스틱 키워드 교체 (3) 자동 텍스트 다시 쓰기. 수동 편집은 유창하고 정확하지만 상대적으로 비용이 많이 든다. 경우에 따라 키어ㅜ드 기반 접근 방식이 적절하다-예를 들어, 대명사와 같은 closed-class 단어를 국소적으로 대체하여 counterfactual을 얻을 수 있을 때- 하지만 관심 있는 모든 레이블 및 covariates의 유창성이나 적용 범위를 보장할 수 없으며, 여러 언어로 일반화하기 어렵다. 완전히 생성적인 접근법은 잠재적으로 수동 편집의 유창성과 적용 범위를 어휘 휴리스틱의 용이성과 결합할 수 있다.
counterfactual 예제는 Section2에 설명된 대로 인과 추론에 내재된 누락 데이터 문제를 직접 해결하기 때문에 강력한 자원이다. 그러나 많은 경우에 유창한 사람도 의미 있는 counterfactual을 만들기는 어렵다: 어떻게든 "everything else"을 일정하게 유지하면서 book review를 레스토랑 리뷰로 전환하는 작업을 상상해 보십시오. 이와 관련된 우려는 counterfactual의 원하는 영향을 지정하는데 있어 정확성이 부족하다. 예를 들어 미국에서 영국 영어로 텍스트를 수정하려면 'colors'가 'colours'로 대체되어야 하지만 'congress'와 같은 용어는 'parliament'와 같은 유사한 개념으로 대체되어야 하는가? 이것은 우리가 텍스트의 의미를 local의 causal descendent로 보느냐에 달렸다. 이러한 결정을 주석자의 직관에 맡기면 counterfactual data augmentation에서 얻을 수 있는 robustness가 무엇인지 확인하기 어렵다. 마지막으로, counterfactual이 새로운 spurious correlation를 도입할 가능성이 있다. 예를 들어, 정반대를 사용하지 않고 NLI 예제를 다시 작성하라는 요청이 있을 때 주석자(또는 자도화된 텍스트 재작성기)는 새로운 가짜 상관관계를 도입하는 또 다른 지름길을 찾을 수 있다. 키워드 치환 접근법은 키워드 어휘가 불완전한 경우 새로운 가짜 상관관계를 도입할 수 있다. 조건부 택스트 재작성을 위한 자동화된 방법은 일반적으로 다양한 원인과 결과 사이의 관계를 모델링해야 하는 data generating process의 공식적인 counterfactual 분석에 기반하지 않는다. 따라서 resulting counterfactual instance는 가짜 상관관계를 완전히 설명하지 못할 수 있으며 새로운 가짜 상관관계를 도입할 수 있다.
4.1.2 Distributional Criteria
data augmentation의 대안은 관찰된 데이터에서 직접 작동하는 새로운 학습 알고리즘을 설계하는 것이다. 불변성 테스트의 경우 한가지 전략은 불변성 예측 변수의 분포 특성을 도출한 다음 이러한 속성이 학습된 모델에 의해 충족되는지 확인하는 것이다.
학습 시간에 잠재적 confounder의 관찰한 경우 counterfactually 불변 에측 변수는 데이터 생성 프로세스의 인과 구조에서 파생될 수 있는 독립 기준을 충족한다. 예제2로 돌아가서 예측 진단 f(x)가 병원 Z와 관련된 쓰기 스타일의 측면에 영향을 받아서는 안된다는 것이 필요하다. 이것은 Z에 대한 counterfactual 불변성으로 공식화 될 수 있다 : predictor f는 모든 z, z'에 대해 에 대해 만족해야 한다. 이 경우 Z와 Y는 모두 텍스트 features X의 원인이다. 이 관찰을 사용하면, 모든 counterfactually 불변 예측 변수가 를 만족한다는 것을 보여줄 수 있다. 즉, 예측 f(x)는 실제 레이블 Y에서 조건화된 covariate Z와 무관핟. 내용 조정과 같은 다른 경우에 레이블은 이러한 구별에 대한 자세한 논의를 위한 원인이 아니라 텍스트의 결과이다.
각 환경에는 원인에 대한 고유한 분포를 가지지만 X와 Y 사이의 인과 관계는 환경에 따라 변하지 않는 유한한 환경 집합에서 발생하는 것으로 학습 데이터를 봄으로써 분포 기준의 대안 집합을 도출할 수 있다. => 특정 도메인에 대한 예측 변수를 학습X 다른 도메인에서도 잘 작동하는 예측 변수를 해서 도메인 일반화가 되게
두 가지 일반적인 접근 방식 모두 일반적인 지도 학습보다 더 풍부한 훈련데이터가 필요하다. 예측에서 분리할 요인에 대한 명시적 레이블Z 또는 레이블이 지정된 여러 환경에서 수집된 데이터에 대한 엑세스. 이러한 데이터를 얻는 것은 counterfactual instance를 만드는것돠 비교해도 다소 어려울 수 있다. 또한, 지금까지 분포 접근법은 분류 문제에만 적용되었지만, 기계 번역과 같은 구조화된 출력에는 data augmentation을 쉽게 적용할 수 있다.
4.2 Fairness and Bias
NLP 시스템은 텍스트 학습 데이터에 인코딩된 바람직하지 않은 편향을 상속하고 때로는 증폭한다. 인과 관계는 인종 및 성별과 같은 인구통계학적 특성에 대해 원하는 공정성 조건을 지정하기 위한 언어를 제공할 수 있다. 실제로 예측 모델의 공정성과 편향성은 인과관계와 밀접한 관련이 있다 : Hardtet은 관특된 데이터 및 예측 분포의 송정성 속성을 결정하기 위해 인과 분석이 필요하다고 주장한다; 등...
Fairness with Text
인과 관계와 불공정 편향 사이의 근본적인 연관성은 주로 텍스트보다는 상대적으로 저차원 표 데이터의 맥락에서 탐구되었다. 그러나 이 설정에서 Section 4.1.1의 counterfactual data augmentation 전략에는 다음과 같은 몇 가지 적용이 있다 : 예를 들어 Garg등은 텍스트 분류의 편향을 줄이기 위해 'identity terms' 목록을 교환하여 counterfactual을 구성하고 누구는 상호 참조해결을 위해 대명사 미 이름과 같은 성별 표시를 바꾼다. 사전 학습된 모델의 편향을 줄이기 위해 counterfactual data augmentation도 적용되었지만 사전 학습된 모델의 편향이 다운스트림 애플리케이션에 전파되는 정도는 불분명하다. Section 4.1.2에서 논의된 분포 기준의 공정성 적용은 상대적으로 드물지만 누가 불변 위험 최소회가 toxity 검출을 위한 인종과의 가짜 상관관계 사용을 줄일 수 있음을 보여준다.
4.3 Causal Model Interpretations
모델 예측에 대한 설명은 오류를 진단하고 의사 결정자와의 신뢰를 확립하는 데 중요할 수 있다. 설명을 생성하는 한 가지 중요한 접근 방식은 예측을 생성하는 경로에서 계산되는 attention weight와 같은 network artifacts를 활용하는 것이다. 또는 테스트 예제의 perturbations 또는 hidden representation을 사용하여 더 단순하고 해석 가능한 모델을 추정하려는 시도가 있었다. 그러나 attention 기반 방법과 perturbation 기반 방법 모두 중요한 한계가 있다. attention-based 설명은 오해의 소지가 있을 수 있으며, 일반적으로 개별 토큰에 대해서만 가능하다; 더 추상적인 언어적 개념의 관점에서 예측을 설명할 수 없다. 기존 perturbation-based 방법은 종종 신뢰할 수 없는 counterfactual을 생성하고 문장 수준 개념의 효과를 추정하는 것을 허용하지 않는다.
인과적 추론 문제로 볼때, 각 예에 대한 에측과 그것이 생성한 counterfactual을 비교함으로써 설명이 가능하다. 일반적으로 counterfactual 예측을 관찰하는 것은 불가능하지만, 여기서 인과 시스템은 예측 변수 그자체이다. 그러한 경우, 예를 들어, 네트워크 내부의 activation을 조작하여 counterfactual을 계산할 수 있다. 그런 다음 factual and counterfactual 조건에서 예측을 비교하여 treatment effect를 계산할 수 ㅣㅆ다. 이러한 통제된 설정은 Section2에서 설명한 무작위 실험과 유사하며, 여기서 실제 텍스트와 텍스트에 특정 개념이 없었을 경우의 차이를 계산할 수 있다. 실제로 counterfactual 텍스트가 생성될 수 있는 경우 텍스트 기반 모델에 대한 인과 관계를 추정할 수 있다. 하지만 counterfactual을 생성하는 것은 어렵다(Section4.1,1).
counterfactual 생성 문제를 극복하기 위해, 텍스트 자체가 아니라 텍스트의 representation을 조작하는 또 다른 접근 방식이 제안되다. Federet은 confoundig 개념을 제어하면서 선택 개념을 '잊도록' 설계된 적대적 구성 요소를 사용하여 classifier가 사용하는 언어 표현 모델의 추가 인스턴스를 사전 학습하여 counterfactual 표현을 계산한다. Ravfogel은 linear classifier를 반복적으로 학습하고 표현을 null-space에 투영하여 표현에서 정보를제거하는 방법을 제공하지만 confounding 개념을 설명하진 않는다.
complementary(보완적) 접근법은 다른 모델 예측을 얻는 최소한의 변경으로 counterfactual을 생성하는 것이다. 이러한 예를 통해 모델의 예ㅡㄱ을 변경하는데 필요한 변경 사항을 관찰할 수 있다. 인과 모델링은 관찰된 특징 사이의 인과 관계에 대해 추론할 수 있게 함으로써 이를 용이하게 할 수 있으며 여러 특징에 다운스트림 영향을 미칠 수 있는 최소한의 작업을 식별하여 궁극적으로 새로운 예측을 생성한다.
마지막으로, attention-based 설명에 대한 인과적 관점은 내부 노드를 입력에서 출력까지 인과적 효과의 매개자로 보는것이다. 수동으로 제작된 counterfactual을 사용하여 모델을 쿼리함으로써 정보가 어떻게 흐르는지 관찰할 수 있고 모델에서 그것이 인코딩되는 위치를 식별할 수 있다.
5. Conclusion
이 논문의 주요 목표는 인과관계와 NLP의 다양한 접점을 한 공간으로 모은 다음 인과관계 효과의 크기를 추정하는 문제로 세분화했다. 과학적 탐구의 이러반 분야는 공통의 목표와 직관을 공유하고 방법론적 시너지 효과를 보이기 시작하고 있다. Section 3에서 우리는 NLP 모델링의 최근 발전이 어떻게 연구자들이 텍스트 데이터와 이 과정의 과제로 인과적 결론을 내릴 수 있는지 보여주었다. Section 4에서 인과 추론의 아이디어를 사용하여 NLP 모델을 보다 강력하고 신뢰할 수 있으며 명료하게 만들 수 있는 방법을 보여주었다. 또한 암시적으로 인과 관계가 있고 인과 추론과의 관계를 명시적으로 보여주는 접근법을 수집한다. 이 두 공간, 특히 강력하고 설명 가능한 예측을 위하 인과적 아이디어의 사용은 우리가 이 논문을 통해 자세히 설명한 많은 공개 과제와 함께 초기 상태로 남아있다. 인과적 방법론의 특별한 장점은 실무자들이 그들의 가정을 설명하도록 강요하다는 것이다. 과학적 기준을 개선하기 위해 NLP 커뮤니티가 이러한 가정에 대해 보다 명확하게 설명하고 인과적 추론을 사용하여 데이터를 분석해야 한다고 생각한다. 이것은 언어를 처리하기 위해 구축한 모델과 언어에 대한 더 나은 이해로 이어질 수 있다.
