BERT 같은 NLP 모데에 대한 간략한 소개로 시작하고, 본직적인 약점을 강조하며, 인과 관계가 기존 단점을 해결할 수 있는 광범위한 방법을 제안한다. 그런 다음 spurious correlation에 대해 논이하고 기사의 나머지 부분에 걸쳐 활용될 실제 사례 연구를 소개한다. 다음으로, robustness와 sensitivity에 초점을 맞춘다. 특히 causally-motivated(인과 동기)가 있는 data augmentation 및 distribution criteria(분포 기준)이 문제를 극복할 수 있는 방법에 대해 설명한다. 이는 NLP 모델의 fairness와 bias에 대한 논의로 이어지며 fairness를 개선하고 bias를 줄이는 목표를 해결하기 위해 인과 관계를 어떻게 사용할 수 있는지에 대해 논의한다. 마지막 섹션에서는 NLP 모델의 interpretability와 explainability를 개선하기 위해 인과 관계를 사용하는 것을 다룬다.
Correlational Predictive Models
BERT는 NLP의 획기적인 순간을 나타냈고, Transformer 아키텍처의 사용과 contextual embedding의 양방향 특성은 RoBERTa, M-BERT, ALBERT 및 ERNIE와 같은 모델을 생성하는 많은 연구자들에의해 채택되었다. 그러나 이러한 아키텍처는 원인, 결과 및 confounder을 구분하지 않는다. Feder는 이러한 모델이 causal relationship을 식별하려고 하지 않는다라고 설명한다. 따라서 'feature가 원하는 output과 직접적인 인과 관계가 없더라도 강력한 예측 변수가 될 수 있다".
Feder에 따르면, 현재 NLP모델은 'correlational predictive model'로 설명될 수 있으며, 여기서 예측은 인과관계가 아닌 상관관계에 기인한다. 따라서 SOTA를 달성했음에도 불구하고, 이러한 상관 예측 모델은 신뢰할 수 없으며 out-of-diestribution외 설정에서 오류를 초래할 수 있다. 신뢰와 관련하여 Jacovi는 AI 모델의 신뢰성을 탐구한다. 그들은 'warranted(보증된)' 신뢰가 무엇을 의미하고 내적 추론과 외적 행동을 통해 어ㄸ허게 달성할 수 있는지에 대해 논의한다. 그들은 신뢰할 수 있는 AI를 설계하는 방법을 제안하며, 주요 결과는 신뢰와 설명 가능한 AI(XAI) 사이의 관계의 중요성이다. AI의 설명 가능성을 향상시키기 위해 인과관계를 사용해야하는 또 다른 이유. 또한 McCoy는 AI 언어 모델이 잘못된 이유로 어떻게 옳은지 보여주며, 오류가 있는 구문 휴리스틱(spurious 'shorcut')에 의존하기 때문에 out-of-distribution 설정에서 오류를 발생시킬 것이다. 인과관계가 부족하면 일반화에 서투른 설명할 수 없는 모델로 이어진다는 것이 분명해진다.
상관 예측 모델에는 두가지 문제가 있다."사용자 그룹간에 허용할 수 없는 성능차이와 사용자의 행동이 너무 이해하기 어려워서 중요한 의사 결정에 통합할 수 없다는 문제" 예를 들어 '남성도 쇼핑을 좋아합니다'라는 제목의 전자상거래 연구는 성별 편향 증폭에 대해 논의하고 이러한 AI 모델이 사용자 그룹 간에 성능 차이를 어떻게 나타낼 수 있는지 보여준다. 게다가 언급했듯이 BERT같은 블랙박스 모델의 공통적인 문제는 그것들이 고위험 의사결정에 사용될 튜명성이 부족하다는 것이다.
상관예측 모델의 단점을 해결하기 위한 솔루션은 인과적 관점을 적용하는 것이다. 'observation과 label 사이의 인과관계에 대한 지식을 사용하여 spuruous correlation을 공식화하고 이러한 상관관계에 대한 예측 변수의 의존도를 완화하는 것'이 가능하다는 것을 보여준다. 즉 데이터 생성 프로세스(DGP)의 인과 구조를 이해하면 잠재적인 confounder를 식별하는데 도움이 될 수 있다. 예를 들어 베이치는 입력의 관련 없는 부분을 변경하면 모델의 예측이 변경되지 않아야 한다는 요구 사항을 공식화 하는 방법으로 스트레스 테스트를 사용할 것을 제안한다(counterfactual invariance)
Spurious Correlations & A Case Study
한 의료 연구 센터에서 환자 의료 기록의 textual narratives(본문의 서술)에서 임상 진단을 감지하는 분류기를 구축하려고 한다. 기록은 여러 병원 사이트에 걸쳐 집계되며, 이는 대상 임상 상태의 빈도와 서술 스타일이 모두 다르다. 여기서 Z는 병원을, Y는 의사가 지정한 진단 레이블을, W는 서면 임상 설명을 Yhat은 분류기의 예측을 나타낸다.
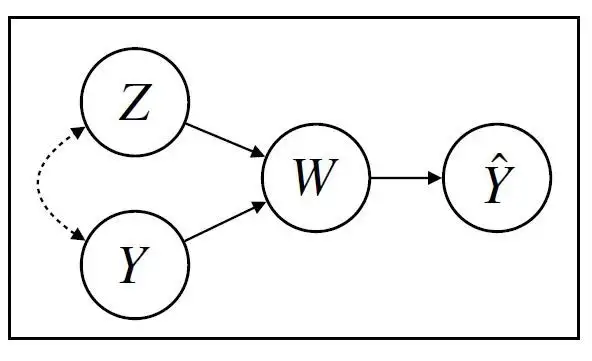 예측(Yhat)이 임상 서술(W)에 의존하는 분류 문제로, 진단 라벨(Y)과 병원(Z)의 영향을 받으며, 둘은 상관관계가 있다.
예측(Yhat)이 임상 서술(W)에 의존하는 분류 문제로, 진단 라벨(Y)과 병원(Z)의 영향을 받으며, 둘은 상관관계가 있다.
classifier Y_hat(W)는 임상 서술(W)의 텍스트를 입력으로 받아 진단 예측을 출력한다.단, 내러티브는 의사의 진단(Y)을 기반으로 하며 병원 Z에서 사용되는 문체에도 영향을 받는다. 이 경우, Feder에 따르면, 레이블(Y)를 고정한 상태에서 병원 Z에 개입하고자 한다. Counterfactually로 병원을(z)로 설정할 것이며, Y가 고정된 동안 counterfactual narrative W(z)를 제공한다. counterfactual narrative W(z)의 입력이 주어졌을 때, classifier Y_hat(W)의 출력은 counterfactual prediction Y_hat(W(z))이다.
학습 데이터에는 여러 병원의 기록을 갖고 있기 때문에 환자가 특정 상태로 진단받을 가능성이 높은 병원이 있을 수 있다. 특정 병원의 의사들이 해당 병원의 관행 때문에 고유한 텍스트 기능을 사용하는 경향이 있을 수 있다. BERT를 사용하여 상관 예측 모델을 구축할 경우, 예측 변수는 병원(Z)에 대한 정보를 전달하는 textual features (X)를 사용하며, 이는 특정 병원내 진단을 예측하는 데 쓸모가 없다. 따라서 문제는 out-of-distribution 성능이 좋지 않다는 것이다. 작문 스타일과 의학적 진단 사이의 spurious correlation으로 인해 학습 데이터 이외의 병원에 대한 예측은 유효하지 않을 것이다.
Federt은 spuruous correlation이 발생하려면 두 가지 조건이 충족되어야 한다고 말한다. 첫 째, 학습데이터에는 feature(X)와 label(Y) 모두에 대해 정보를 제공하는 factor(Z)가 있어야 하며, 둘때 Y와 Z는 일반적으로 유지가 보장되지 않는 방식으로 학습 데이터에 종속되어야 한다. 이 예제에서 이미지에서 보듯이 Z는 Y와 상관 관계가 있다.
병원Z와 라벨Y사이의 이러한 가짜상관관계는 학습 데이터내에 존재한다; 따라서 예측 변수는 병원 Z에 대해 정보를 제공하는 X의 부분을 학습한다. 그러나 feature X와 label Y사이의 학습된 관계가 deployment중에 유지되지 않기 떄문에 이 예측 변수는 robust하지 않다.
Sensitivity and Robustness
예측을 위해 상관관계에 의존하는 BERT와 같은 AI언어모델을 다를때 예측이 잘못된 이유로 답을 맞추지 않게하는 것이 중요하다. 이 작업에 사용할 수 있는 평가에는 invariane test(불변성 테스트)와 sensitivity test(민감도 테스트) 두가지 유형이 있다. 불변성 테스트는 "예측이 레이블과 인과 관계가 없는 perturbation(작은 변화)에 의해 영향을 받는지 여부를 평가한다". 반면에 민감도 테스트는 "true label을 전환하는데 필요한 최소한의 변화가 되어야 하는 perturbation을 적용한다". causally-motivated 불변성 검정의 목적은 counterfactual 입력이 주어졌을 떄 예측 변수가 다르게 동작하는지 확인하는 것이다. Z가 텍스트에서 레이블 Y와 인과관계가 없어야 하는 원인 레이블인 경우 counterfactual 입력은 X(Z=~z)가 된다. 그러한 counterfactual에 걸쳐 예측이 변하지 않는 모델은 경우에 따라 Y와 Z 간의 관계가 다른 테스트 분포에서 더 잘 수행될것으로 예상할 수 있다.
민감도 테스트는 counterfactual에 대한 평가라는 점에서 불변성 검정과 유사하다. 그러나 차이점은 레이블 Y가 변경되지만 X에 대한 다른 모든 인과적 영향은 일정하게 유지된다. 민감도 테스트의 counterfactual는 X(Y=~y)로 표현. 민감도 및 불변성 테스트는 robustness을 테스트하는 방법이며, 이러한 테스트를 통과할 수 있는 학습 예측 변수에 대한 몇 가지 접근법이 있다. 이러한 접근법은 데이터의 인과 구조에 대한 도메인 지식을 학습 목표에 통합하는 방법이며, 이는 인과 동기 접근법임을 의미한다.
data augmentation은 counterfactual instace가 구성되며 학습 데이터에 통합되는 곳이다. 이 방법은 불변성과 민감성 모두에 효과 있음. 예를 들어, 불변성을 사용하여 counterfactual 쌍(예: X(Z=z) 및 X(Z=~z)에 대한 예측의 불일치를 penalizes하는 용어를 학습 목표에 추가할 수 있다. 민감도 테스트하는 경우 개입은 레이블Y에 있을 것이고, label counterfactuals X(Y=~y)로 학습 데이터를 증가시킬 것이다. 이것은 noise에 대한 민감도를 줄이고 out-of-domain 일반화 한다.
manual post-editin(수동 사후 편집), 키워드의 휴리스틱 대체 또는 자동 텍스트 재작성과 같은 counterfactual 예제를 생성하는 몇 가지 방법이 있다. 수동 편집은 일반적으로 정확하지만 비용이 많이 든다. 키워드를 사용하는 두번쨰 옵션은 일부 시나리오에서만 작동한다. 예를 들어, 대명사와 같은 단어의 국소치환을 함으로써 counterfactual을 얻을 수 있을 때. 그러나 이 키워드 접근법은 관심 있는 모든 레이블과 covariates의 유창성이나 적용범위를 보장할 수 없으며, 여러 언어 간에 일반화하기 어렵다. 마지막 옵션은 완전히 생성적인 접근 방식으로, 수동 편집의 정확성과 적용 범위를 어휘 휴리스틱의 용이성과 결합하는것이다.
세 가지 옵션 모두 가짜 상관 관계를 초래할 위험이 있다. 예를 들어, 키워드 어휘가 불완전할 경우 키워드를 대체 방법은 새로운 가짜 상관관계가 도입될 수 있다. 수동 편집과 자동 텍스트 생성의 다른 두가지 옵션은 counterfactual 생성이 새로운 가짜 상관관계를 도입할 수 있는 동일한 문제를 공유한다. counterfactual예는 인과적 추론에 내재된 누락된 데이터 문제를 직접 해결하기 때문에 강력할 수 있지만 counterfactual data augmentation은 가짜 상관관계에 취약. 따라서 대안은 관찰된 데이터에 직접 작용하는 causally-motivated 분포 기준이다.
정의에 따르면 counterfactually 불변 예측 변수는 DGP의 인과 구조에서 파생될 수 있는 독립 기준을 충족한다.불변 예측 변수의 분포 속성을 도출함으로써 학습된 모델이 이러한 속성을 충족하는지 확인할 수 있다. 의료 예에서 병원 작문 스타일 Z를 변경하면 거짓 상관관계이므로 진단 Y가 변경되지 않도록 해야한다. 페더등에 따르면 예측 변수 f와 text feature X가 주어지면 Z에 대항 counterfactual 불변성은 모든 z에 대해 f(X(z)) = f(X(z'))오 공식화 할 수 있다. 여기서 Z와 Y는 모두 X의 원인이므로 counterfactually 불변 에측 변수는 true label Y에서 조건화된 convariate Z와 독립적인 에측 f(x)를 제공한다. 즉 레이블은 텍스트의 효과가 아니다
분포 기준을 얻기 위한 두가지 다른 대안. 첫 번째 대안은 학습 데이터를 '각 환셩이 원인에 대해 고유한 분포를 갖지만 X와 Y 사이의 인과 관계는 환경에 따라 변하지 않는 유한한 환경 집합에서 발생하는'것으로 보는 것이다. 환경 불변성 기준의 목적은 동일한 예측 변수가 모든 환셩에서 최적인 표현을 갖도록 하는 것이다. 이것은 도메인 일반화로 생각할 수 있다. 다른 대안은 confounding을 제어하는 것이다. 페더에 따르면 Z가 confounding 일 경우, 관찰 확률을 개입 확률로 변환하기 위한 '백도어 조정'과 관련된 인수 분해?를 사용하여 Z의 confounding feature를 제어할 수 있다.
data augmentation과 비교하여 distribution criteria에는 '일반적으로 지도 학습 문제에 사용할 수 있는것보다 더 많은 학습데이터'가 필요하다. 따라서 선택방법은 분포 기준에 필요한 관찰 데이터를 얻는 것이 더 쉬운지 아니면 학습셋을 증가시키기 위해 confunding instance를 만드는 것이 더 쉬운지에 따라 달라진다.
Fairness and Bias
Causal Model Interpretability & Explainability
BERT와 같은 NLP 모델은 현재 설명하기 어려운 난해한 블랙박스이지만, 오류를 진단하고 의사결정자와의 신뢰를 구축할 필요가 있다. 현재 페더는 일반적인 접근 방식은 attention weight와 같은 network artifact를 이용하여 설명을 생성하는 것이라고 말한다. 정당성은 attention weight가 예측을 생성하는 경로에서 계산된다는 것이다. 다른 접근 방식은 테스트 예제의 perturbation 또는 hidden representation을 사용하여 더 단순하고 해석 가능한 모델을 추정하라는 것이다. attention과 perturbation 기반의 접근법은 오해의 소지가 있는 한계를 가지고 있다. 예를 들어, 'attention-based 설명은 일반적으로 개별 토큰에 대해서만 가능하므로 추상적인 언어 개념의 관점에서 예측을 설명할 수 없다'. 또한 perturbation-based 방법은 '문장 수준 estimates의 효과를 추정할 수 없으며 종종 신뢰할 수 없는 counterfactuals를 생성한다.
기존 설명 가능성의 문제를 고려할 때 causal perspective(인과적 관점)을 적용할 여지가 있다.페더에 따르면, 한가지 접근법은 data augmentation을 사용하여 counterfactual 사례를 생성한 다음, 각 사례에 대한 예측을 생성된 counterfactual의 예측과 비교하는 것이다. counterfactual data augmentation은 observed text와 텍스트 내에 특정 개념이 존재하지 않는 경우 텍스트(예측 뭐시기 observed반대)가 어떻게 되었을지 간의 차이를 계산할 수 있다. 이러한 경우 counterfactual 텍스트를 생성할 수 있는 경우 텍스트 기반 모델에 대한 인과 관계를 추정할 수 있게 된다.
예를 들어, 로스는 data augmentation을 용이하게 하기 위해 의민론적으로 제어되는 방식으로 텍스트를 교란하는 작업에 구애받지 않는 생성 시스템을 만들었다. 그드리 Tailor라고 이름 붙인 시스템은 unlikelihood 학습과 의미론적 역할에서 파생된 일련의 제어 코드를 따르는 생성기를 사용하며, 여기서 이러한 제어 코드의 수정은 미세한 perturbation을 허용한다. counterfactual 생성에 Tailor를 사용하여 일반적으로 작업별 perturbation 생성기와 관련된 오버헤드를 줄였으며 모델의 해석 가능성을 개선할 수 있는 이점이 있었다. 가드너는 모델의 decision boundary를 평가하기 위헤 '대조 세트'를 사용하여 모델의 해석 가능성을 개선하려고 한다. 그들은 데이터셋을 구성한 후 작성자가 작지만 의미 있는 방식으로 테스트 인스턴스를 수동으로 교란하여 대조세트를 생성해야 한다고 제안한다. 이러한 대조세트는 모델의 decision boundary 경계에 대한 local view를 제공하며, 모델의 진정한 언어 능력을 더 정확하게 평가하는데 사용될 수 있다.
자연어 counterfactual 생성하는데 진전이 있음에도 불구하고, 스타일, 주제 또는 정서와 같은 추상적인 언어 개념의 경우 종종 '의미 있는 counterfactual을 자동으로 생성하는 것이 불가능하며, 수동으로 생성하는 것은 너무 비싸다'. 이 문제를 감안할 때 텍스트 자체를 그대로 두고 대신 텍스트의 표현을 조작하는 대체 접근법이 제안되었다. 이 접근법의 예는 counterfacutal 언어 표현 모델에 대한 페더의 이전에 언급된 연구다. 그들은 confounding concept을 제어하는 적대적 보조 작업과 함께 classifier를 사용하는 언어 표현 모델 BERT의 추가 인스턴스를 사전학습하여 counterfactual representation을 계산한다. 또 다른 예는 ravfogel의 작업으로, 여기서 보호된 속성을 보존하기 위해 반복적인 null-space projection을 사용하여 모델에서 정보를 제거하는 방법이 제안된다. 지금까지 논의된 해석가능성 접근법은 불변성을 식별하기 위해 counterfactual을 사용하며,' 보완적 접근법은 다른 모델 예측을 얻는 최소한의 변경으로 counterfactual을 생성하는 것이다.'
민감도 접근법은 모델의 예측을 변경하는데 필요한 변경 사항을 강조하기 떄문에 설명 가능성을 향상시킨다. 예를 들어 모델의 설명 가능성을 향상시키는 방법으로 다양한 counterfactual 설명을 생성하고 평가하기 위한 프레임워크를 개발한다. 본질적으로, 모델 개발 과정에 불변성 및 민감도 테스트를 통합하는 것은 해석 가능성과 설명 가능성을 높이기 위해 인과 관계를 사용하는 방법이다.
Final thoughts
인과 관계는 robustness, fairness 및 해석 가능성을 높여 NLP 모델을 개선할 수 있다. 이러한 개선을 통해 BERT 같은 최신 AI언어 모델에 존재하는 일부 문제를 해결하는데 도움이 될것이다.인과 추론이 윤리적 인공지능의 발전에 역할을 한다고 믿는다. 사실 나는 최근에 신경과학과 비판 이론이 인과적 추론을 사용하는 시냄스 가소성을 모델로 한 윤리적 AI 시스템에 어떻게 영감을 줄 수 있는지 설명했다. 최근 연구는 인과관계가 편향을 식별하고 완화하는 방법을 제공할 수 있다는 생각을 강화환다.
