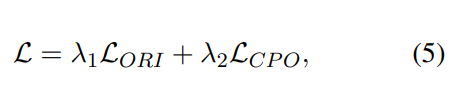Abstract
PLM에 대한 학습된 지식과 CSC 작업의 목표 사이에는 격차가 있음
PLM은 텍스트의 의미론에 초점을 맞추고 잘못된 문자르 의미론적으로 적절하거나 일반적으로 사용되는 문자로 수정하는 경향이 있지만, 이는 실제 수정이 아님
이 문제를 해결하기 위해 CSC 작업에 대한 오류 중심의 지속적 확률 최적화(ECOPO) 프레임워크 제안
ECOPO는 PLM의 지식 표현을 개선하고 모델이 오류 중심 방식을 통해 이러한 일반적인 문자르 예측하지 않도록 안내
특히 ECOPO는 모델에 구애받지 않으며 기존 CSC 방법과 결합하여 더 나은 성능을 달성
1. Introduction
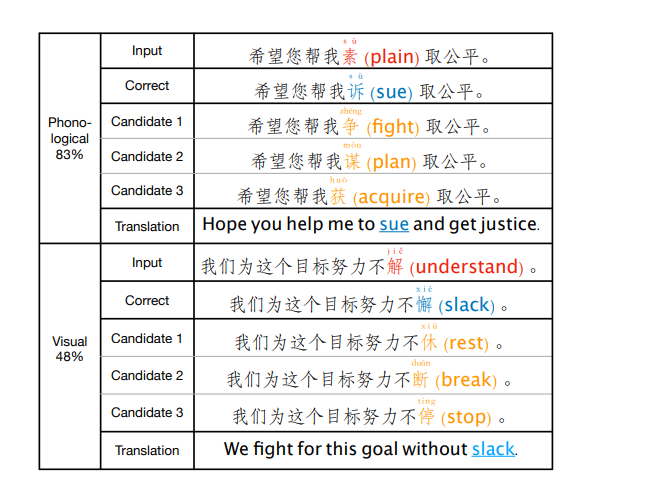
그림 1. 중국어 철자 오류 예. 이전 연구는 오류의 83%가 음운 오류에 속하고 48%가 시각 오류에 속함을 보여줌. 우리는 문자의 발음과 번역을 제공. 입력을 confusing/golden/common 후보 문자를 red/blue/orange로 표시 '후보' 문장의 문자는 모두 미세 조정된 BERT에 의해 예측
PLM에 대한 학습된 지식과 CSC 작업의 목표 사이에는 상당한 격차가 존재. PLM은 의미론적 관점에서 유익한 표현을 제공하지만, CSC에서 의미론만 고려한다면 보정할 수 있는 적절한 문자는 여러개 있음
음운 및 시각적 유사성의 제약 없이 PL은 사전 학습 절차의 마스킹 전략으로 인해 의미적으로 적절하거나 일반적인 문자를 쉽게 예측할 수 있음
그림 1은 BERT의 두 가지 예측을 보여 줌
첫 번째 예는 "素(sù, plain)"와 "诉(sù, sue)"의 오용으로 인해 발생합니다.
이상적인 CSC 모델은 발음 정보 "su"에 주목하고 입력 혼동 문자에 대한 보정으로 golden 문자 "诉(sue)"를 출력해야 합니다.
그러나 일반적인 말뭉치에 대해 사전 훈련을 받은 BERT는 "争(정, 싸움)", "¯(모우, 계획)" 및 "获(후, 획득)"과 같은 의미론적으로 적절한 문자를 예측하는 경향이 있습니다
두 번째 예에서 BERT는 또한 "解(jie, understand)"와 "ˇ(xiè, slack)" 사이의 시각적 유사성을 간과하여 잘못된 수정을 초래합니다.
이러한 격차를 완화하기 위해 PLM의 지식 표현을 최적화하여 PLM이 위에서 언급한 공통 문자를 예측하지 않도록 할 수 있는 권한을 부여할 것을 제안. 직관적으로 모델이 이전과 같은 실수를 저지르지 않도록 모델을 안내하면 모델 성능이 향상되어야 함
따라서 모델이 저지른 실수는 모델의 지식 표현에 대한 제약으로 활용될 수 있음
즉, 모델 자체를 더육 향상시키기 위해 모델이 저지를 수 있는 과거의 실수를 활용하는 것인데, 이것이 바로 "과거의 실수가 미래의 지혜"라는 제목의 의미
CSC 모델의 지식 표현을 개선하는 것을 목표로 하는 간단하지만 효과적인 훈련 프레임워크인 오류 중심 COntrastive Probability Optimization(ECOPO)을 제안
ECOPO는 (1) negative sample 선택의 두 단계로 구성
다양한 문자에 대한 모델의 예측 확률을 기반으로 높은 확률을 가진 공통 문자를 negative sample로 선택
gloden 문자는 positive sample로 간주
(2) 대조 확률 최적화
양성 샘플과 음성 샘플을 활보 후, 서로 다른 문자에 대한 예측 확률을 최적화하는 것을 목표로 하는 대조확률 최적화(CPO)를 통해 모델을 학습
최적화 프로세스를 통해 최종적으로 사전 학습된 PLM 지식과 CSC의 목표 사이의 간극을 좁힐 수 있음
또한 ECOPO는 최적화 대상 모델에 대한 엄격한 제한이 없기 때문에 기존의 다양한 CSC 모델의 성능을 향상
요약하자면:
1. PLM에 대한 지식과 CSC의 목표 사이의 격차로 인한 부정적인 영향을 관찰하고 초점을 맞춤
2. 과거의 실수를 통해 모델이 성장하고 발전하도록 가르칠 수 있는 모델 독립적인 ECOPO 프레임워크 제안
3. SIGHAN 벤치마크에 대한 광범위한 실험과 상세한 분석을 수행하고 SOTA 달성
2. Related Work
2.2 Contrastive Learning
대조 학습의 주된 동기는 특정 공간에서 positive sample을 끌어당기고 negative sample은 밀어내는 것
NLP의 기존 대조 학습 모델은 주로 언어 표현 공간(예: 단어/문장/의미 표현)에 초점을 맞추고 있음
우리가 제안하는 방법은 선택된 positive/negative sample과 원래 예측된 확률을 통해 다양한 문자에 대한 모델의 확률 공간을 직접 최적화
3. Methodology
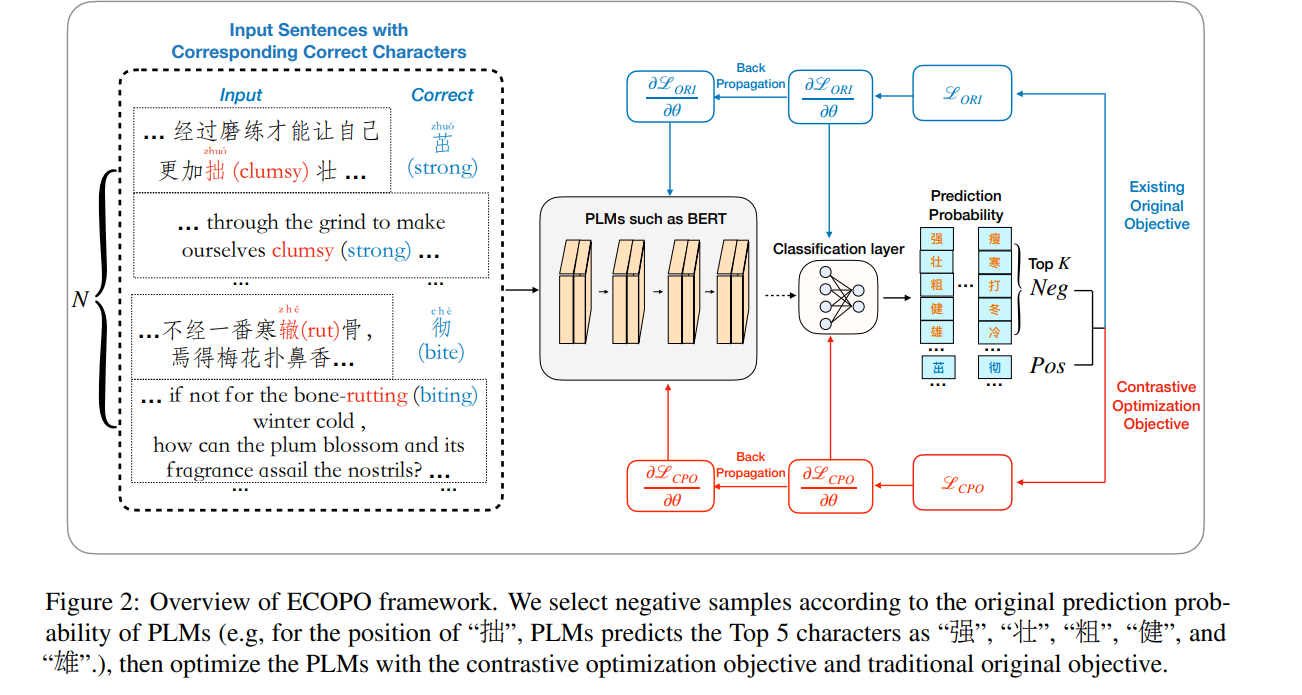
그림 2와 같이 제안된 ECOPO에 대해 자세히 소개
ECOPO는 PLM의 지식 표현을 개선하여 CSC 작업의 본질과 간극을 좁히는 것을 목표
섹션 1에서 언급했듯이 최적화 프로세스 이전의 모델을 사용하여 이 모델 자체에서 생성된 오류를 negative sample로 선택
그런 다음 대조 확률 최적화 목표를 통해 정답에 대한 모델의 예측 확률을 최대화하고 negative sample에 대한 모델의 예측 확률을 최소화
이러한 오류 중심의 방식으로 모델의 원래 예측 확률이 개선되어 CSC 작업에서 모델의 성능이 향상
따라서 모델은 인간과 마찬가지로 실수를 반복하면서 성장하고 발전하게 됨
3.1 Observation and Intution
그림 1에서 볼 수 있듯이 BERT와 같은 PLM은 CSC 작업에서 더 많은 주의를 기울여야 하는 혼동하기 쉬운 문자에 제대로 attention 할 수 없는 것이 ECOPO의 핵심 관찰 결과
이러한 차이는 주로 일반적인 말뭉치와 언어 모델의 사전 학습에 사용되는 학습 패러다임에 비롯된다고 생각
BERT를 예로 들면, 사전 학습 코퍼스는 주로 위키피디아의 텍스트에서 가져온 것으로, 혼동하기 쉬운 문자가 포함된 문맥의 비율이 매우 낮음
또한 마스킹 복구 전략은 사전 학습 과정에서 PLM이 습득한 지식을 CSC 작업에서 불연속적으로 만듬
사실 사람이 맞춤법 오류를 수정할 때도 동일한 문제가 존재
맞춤법 오류를 보지 않고 입력된 문장의 문맥만 주어지면 혼동하기 쉬운 문자가 아닌 일반적인 문자를 문맥과 연관시키는 경향이 있음
따라서 인간이나 모델은 일반적인 문자를 잘못 예측할 수 있음
직관적으로, 오류 기반 방식을 통해 일반 문자에 대한 모델을 최적화할 수 있다면, 인간이 실수를 통해 발전하는 것처럼 모델을 더욱 향상시킬 수 있음
3.2 Stage 1: Negative Samples Selection
CSC의 negative sample을 최적화 프로세스 전에 PLM에 의해 높은 예측 확률이 잘못 할당되는 공통 문자로 정의
일반적인 collocation이나 구를 형성할 수 있는 negative sample은 golden 문자보다 높은 확률로 할당되는 경향이 있어 모델이 잘못된 수정을 함
따라서 다음 단계에서 활용한 negative sample을 선택하기 위해 예측 확률에 기반한 간단한 전략을 사용
특히 BERT와 같은 PLM을 사용하여 마지막 transformer layer의 출력을 기반으로 각 입력 토큰의 원래 문자를 예측. 문장 X에서 i번째 토큰 의 예측 확률은 다음과 같이 정의
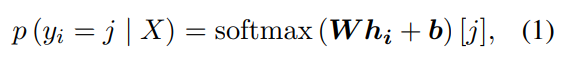
여기서 는 i번째 토큰 가 PLM의 vocab에서 j번째 문자로 예측되는 조건부 확률을 의미하며, 및 은 학습 가능한 매개 변수이며, vocab은 어휘의 크기이고 hidden은 hidden state의 사이즈, 은 i번쨰 토큰 에 대한 PLM의 hidden state output
원래 예측 확률을 바탕으로 모델이 입력 문자에 대해 잘못된 수정을 할 경우 입력 문자에 대해 negative sample을 선택
negative sample set Neg는 candidate set T에서 다음과 같이 선택
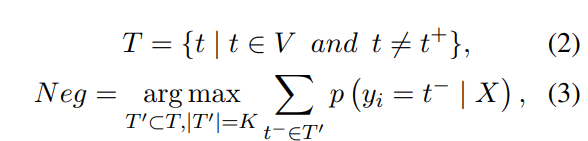
t-와 t+는 각각 음의 샘플과 양의 샘플을 의미
음의 표본 t-는 예측 확률이 vocab V의 상위 K개에 있는 토큰 중에서 선택되고 K의 가장 좋은 값이 경험적으로 선택
학습 과정은 CSC task에서 supervised되므로 golden 문자를 sample t+로 간주
3.3 Stage 2: Contrastive Probability Optimization
positive/negative sample과 해당 예측 확률을 얻은 후, CPO(Contrastive Probability Optimization) 목표에 따라 모델을 학습
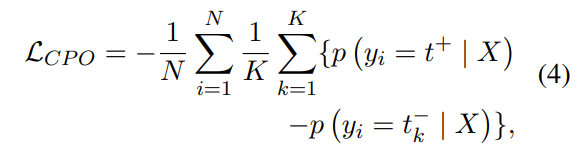
N은 배치크기, K는 선택한 negative samples size, 는 Neg에서 k번째 negative sample
CPO목표는 양성 샘플(즉, 혼동하기 쉬운 문자)에 대한 예측 확률을 높이고 음성 샘플(즉, 공통 문자)에 대한 예측 확률을 낮추는 모데을 학습시키는 것
모델의 일반화 성능을 보존하기 위해 기존의 원래 목표 와 CPO 목표 를 모두 학습함
전체 목표: