Abstract
기존 연구는 text representation을 향상시키고 multi-source 정보를 사용하여 모델의 detection과 correction의 성능을 향상시키는 것을 목표로 하지만 혼동하기 쉬운 단어를 구별하는 능력을 향상시키는 데 크게 attention X
유사한 sample pair간의 representation space를 최소화하는 것을 목표로하는 Contrastive learning(대조 학습)은 자연어처리 주요 기법
대조 학습에 영감을 받아 language representation, spelling check 그리고 역대조 학습의 세 가지 모듈로 구성된 중국어 맞춤법 거사를 위한 새로운 프레임워크 제시
특히, 모델이 음성적으로나 시각적으로 혼동하기 쉬운 문자 간의 일치도를 최소화하도록 명시적으로 강제하는 역 대조학습 제안
이 프레임워크는 모델에 구애받지 않으며 기존 중국어 철자 검사 모델과 결합하여 SOTA
Introduction
맞춤법에 대한 대부분의 최근 성공은 BERT와 같은 non-autoregressive 모델에 의해 달성
왜냐하면 출력의 길이가 입력의 길이와 정확히 같아야 하고 동시에 소스 시퀀스의 각 문자가 대상의 문자와 동일한 위치를 공유해야 하기 때문
한국어에선 입력 길이와 출력길이가 달라지는 경우도 있으텐데 적용 가능할려나...
한자의 오류 패턴은 시각적 음성적으로 요약될 수 있음
CSC 모델이 음성 및 시각적으로 혼동하기 쉬운 문자를 잘 구별할 수 있다면 철자 오류를 수정하는 데 있어 성능을 향상시키는 데 큰 도움
그러나 현재 혼동하기 쉬운 문자 문제를 해결하는 데 도움이 되는 음성 및 시각 정보의 사용을 고려하는 방법은 거의 없음
반면, self-supervised representation 학습은 대조 학습의 적용으로 크게 발전했는데, 주요 아이디어는 임베딩 공간에 대상 예제(anchor)와 유사한(positive) 예제 사이의 일치를 최대화하는 동시에 이 대상과 다른 유사하지 않은(negative) 예제간의 불일치를 최대화하도록 모델 학습
먼저 대조 학습을 fully-supervised setting, 즉 레이블 정보를 효과적으로 활용하여 anchor의 긍정적인 예와 부정적인 예를 구별할 수 있는 Supervised Contrastive Learning(SCL)에 적용할 수 있도록 함
대조 학습의 목적은 유사한 예를 모으는 것이지만, 음성적이나 시각적으로 유사한 문자를 분리해서 모델이 혼동하기 쉬운 문자를 구별하는 데 도움이 될것을 제안
(1) 대조 학습을 CSC 작업에 적용하고 혼동하기 쉬운 문자와 관련된 철자 오류를 더 잘 감지하고 수정하는 모델을 만드는 역 대조 학습(RCL)전략 제안
(2) RCL 전략을 기존 CSC 모델과 쉽게 결합하여 더 나은 성능을 산출할수 있는 모델에 상관없는 CSC 프레임워크 제시
(3) 새로운 CSC 모델이 SIGHAN 벤치마크에서 SOTA
3. The Chinese Spelling Check Framework
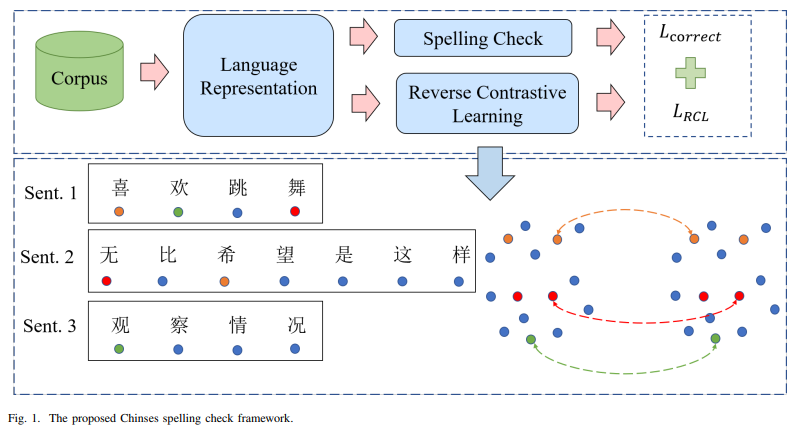
철자 검사를 non-autoregressive작업으로 취급
CSC의 프레임워크는 language representation, 맞춤법 정확성 및 역대조 학습 3가지 모듈로 구성
A. Language representation module
입력을 인코딩 하기 위해 사전 학습된 모델 채택
주석이 달리지 않은 방대한 텍스트 데이터로 학습된 사전 학습 모델은 매개변수의 언어 규칙성을 기억하여 다운스트림 모듈에 풍부한 문맥 표현을 제공할 수 있음
입력 시퀀스 X가 주어졌을 떄, 모델은 먼저 입력 시퀀스 X를 임베딩 에 투영하고 multiple hidden encoding layer를 거친 후 마지막으로 language representation 산출
이 중 각 레이어의 출력은 다음과 같이 표시
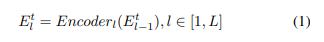
B. Spelling check modulke
이전 모듈에서 생성된 language presentation 가 주어졌을 때, 모델의 목표는 시퀀스에서 부적절한 문자를 감지하고 수정하여 목표 시퀀스 Y를 생성
이 모델의 학습 손실은 로 표시
C. Reverse contrastive learning module
대조 학습의 기본 원리는 유사한 데이터 포인트(동일한 레이블 또는 positive sample)가 서로 가깝게, 동시에 서로 다른 데이터 포인트(negative sample)와는 멀리 떨어져 있도록 모델을 학습
그러나 대조 학습에서 주요 장애물은 적절한 샘플을 구성하는 방법
CSC는 데이터 증강이나 기존 레이블을 직접 사용해 양성 샘플을 구하기 어려움
negative sample을 구성하는 데에만 집중하는 역 대조 학습(RCL) 전략 제안
중국어 문자(anchor)가 주어지면, 부정 샘플은 이 문자와 같은 소리를 내는(동음이의어)와 이문자와 비슷하게 보이는 모든 문자(혼동 집합)로 정의
따라서 학습 목표는 앵커와 그 동음이의어 사이의 거리와 혼동 집합에서 앵커와 거리를 최대화하는 것
K개의 한자 가 포함된 미니배치가 있고 {}가 문자 집합이라고 가정
문자 (병음은 로 표시)와 혼동 집합 가 주어지면 배치에서 이 문자와 동일한 병음을 공유하는 다른 모든 문자는 집합 {}를 형성. 그런 다음 병음 정보를 기반으로 역 대조 손실 함수를 정의
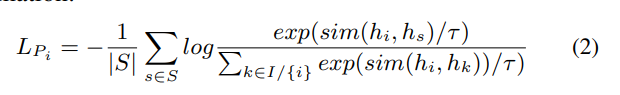
batch 는 혼동 집합 에서 발생하는 모든 문자는 집합{}을 구성
마찬가지로 혼란 집합에 기초한 손실 함수는 다음과 같음
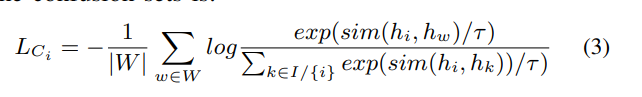
두 방정식에서 sim(.)은 코사인 유사도를 의미하며, τ는 유사도에 얼마나 민감한지를 제어하는 temperature
두 뮨자가 공통점이 많을 경우 τ가 0에 가까울수록 유사성을 강조하고, τ가 클수록 유사성에 신경X
전체 역대조 손실은 모든 negative pairs, 즉 과 에 걸쳐 배치에서 계산
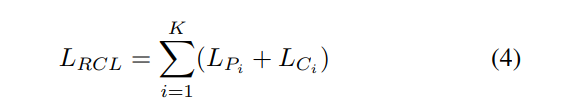
따라서 전체 프레임워크의 총 송실은 이전 섹션에서 언급한 역대조 학습 손실과 맞춤법 검사 훈련 손실의 가중치 합계
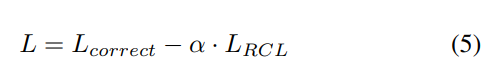
그림 1에 표시된 세 개의 발화(크기 3의 미니 배치)를 예로 들어보면 (喜, 希) and (舞, 无)는 각 쌍의 문자가 동일한 병음(Pinyin)을 가지고 있기 때문에 모두 negative paris. 또한 (欢, 观) 역시 '观'이 '欢'의 혼동 세트에서 발생하므로 negative pair.
우리의 학습 목표는 각 쌍의 문자 표현 사이의 거리를 최대화하고 다른 모둔 문자는 그대로 두는 것
4. Evaluation Protocol
Datasets
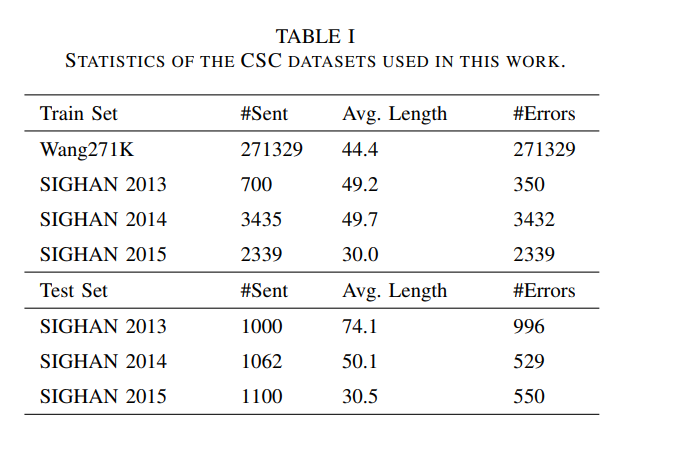
학습 데이터는 Wang271K corpus2를 사용.
또한 SIGHAN 2013, 2014, 2015의 학습 셋도 채택하여 해당 테스트 셋에 대해 제안한 전략의 성능 평가
데이터셋의 통계는 표1에 나와 있음
우리가 사용한 혼동 세트는 시각적 유사성과 음성적 유사성을 기반으로 구축
Setups
CSC 프레임워크가 특정 모델에 종속되지 않는다는 것을 보여주기 위해, DCN과 ReaLiSe를 모두 사용하여 구현
DCN의 경우 language representation module로 RoBERTa를 사용하고, 맞춤법 검사 모듈은 dynamic connected scorer와 Pinyin-enhanced candidate generator로 구성
전체 네트워크는 5e-5의 학습률로 AdamW를 사용하여 최적화 되고 20 epoch에 걸쳐 32 batch size로 학습
ReaLiSe의 경우, 사전 학습된 모델로써 BERT를 사용함. 위의 모델과 동일한 옵티마이저, 32 batch size에 10 epoch동안 모델 학습
warm up과 linear decay 사용
를 계산하기 위해 Cross entropy선택
역대조 손실의 가중치는 최종 값을 찾기 위해 파라미터 검색을 채택
Baseline Models
다른 7개 모델도 비교
Sequence Labeling
CSC 작업을 시퀀스 레이블링 문제로 처리한 다음 양방향 LSTM 모델을 기반으로 지도 시퀀스 레이블링 모델 구축
동시에 모델의 클래스 교차 엔트로피 손실을 최소화하기 위해 RM-Sprop을 optimizer로 사용
FASpell
denoising autoencoder(DAE)와 decoder로 구성된 새로운 패러다임
1. DAE는 BERT, XLNet, MASS 등과 같은 비지도 사전 학습 언어 모델의 성능을 활용하여 지도 학습에 필요한 중국어 맞춤법 검사 데이터의 양을 줄임
2. Decoder는 혼동 셋의 유연하지 않고 불충분한 중국어 문자 유사도 핵심 특성 사용을 제거하는데 도움
BERT
CSC 학습 데이터로 모델을 직접 미세 조정하여 철자 오류 수정을 구현할 수 있는 강력한 사전 학습 언어 모델
SpellGCN
graph convolutional networks를 사용하여 SpellGCN은 지정된 문자 혼동 셋을 BERT 기반 correction model에 통합
Soft-Masked BERT
오류 감지를 위한 네트워크와 BERT 기반의 오류 수정을 위한 네트워크로 구성
FixedFilt
혼동셋을 수작업으로 생서하는 대신 FixedFilt는 계층적 문자 임베딩을 활용하는 확장 가능한 adaptable filter를 사용하여 흔하지 않은 오류로 인한 희소성 문제를 해결
MLM-phonetics
강력한 사전 학습 및 미세 조정 방법을 사용하여 음성 기능을 언어 모델에 통합
음운의 특징을 가진 단어들과 비슷한 소리를 내는 단어들이 그 자리에 사용
5. Experiments
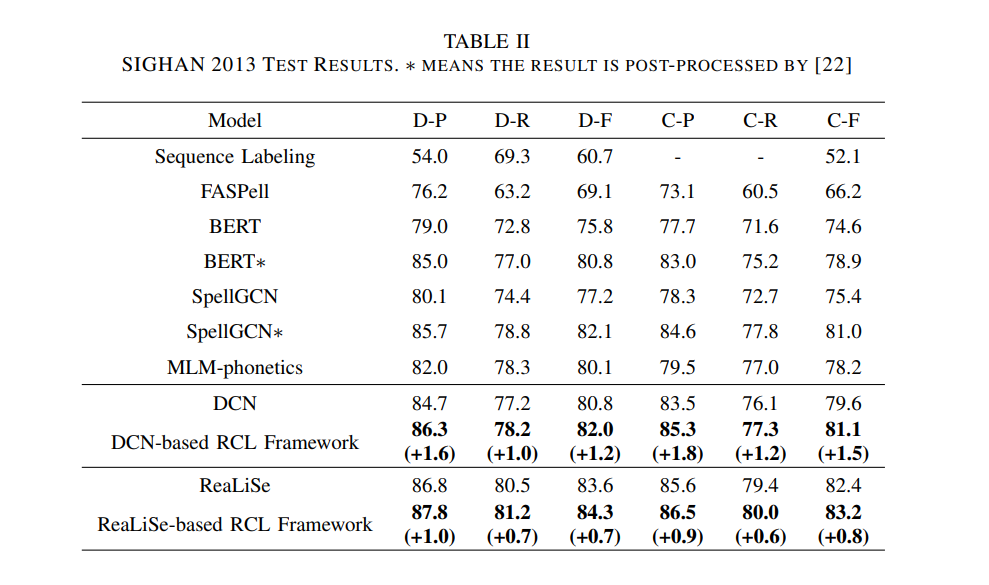
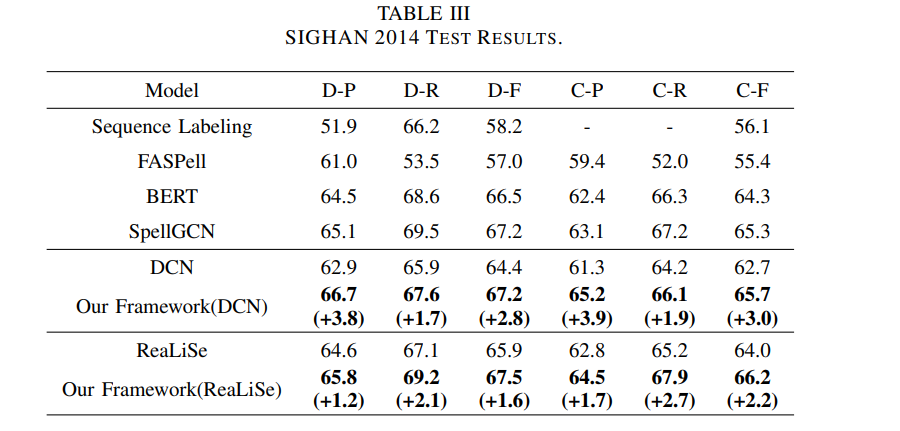
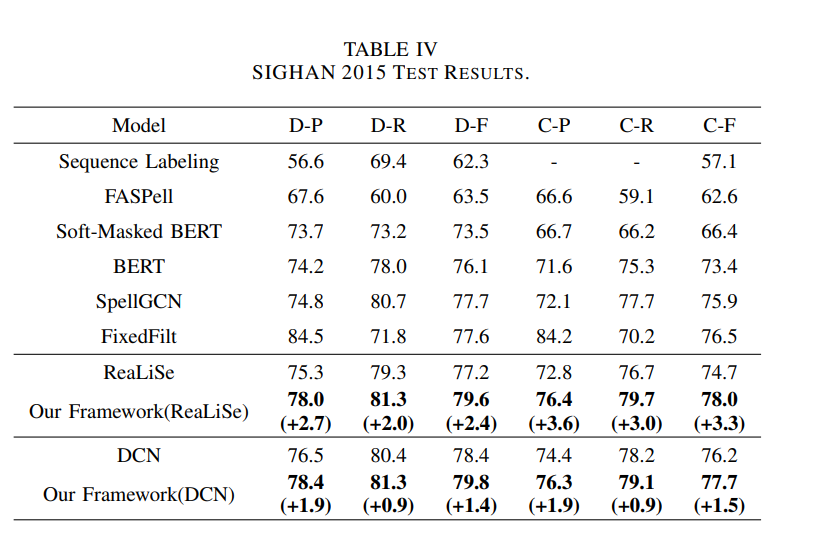
표 2,3,4는 각각 SIGHAN 2013, 2014, 2015 벤치마크에서 다른 모델과 비교한 RCL 프레임워크의 결과를 보여줌
우리의 방법은 fine tuning단계에서 실험하기 때문에 사용된 데이터는 SIGHAN 2013과 같은 4개의 데이터로 제한되어 있으므로 미세 조정단계에서도 최적화된 모델만 비교
역대조 학습 전략이 여러 데이터셋에서 일괄된 개선 효과를 가져오는 것을 관찰할 수 있음
표2에서 볼 수 있듯이 DCN을 사용하면 바닐라 DCN에 비해 F-value이 오류 감지에서 1.2%, 수정에서 1.5%증가
또한 ReaLiSe 기반 프레임워크는 탐지 측면에서 84.3%의 F-value와 83.2%의 교정률로 가장 높은 점수 획득
모든 결과는 우리가 제안한 방법의 효과를 보여주며, 모델에 의존적이지 않다는 것을 잘 보여줌
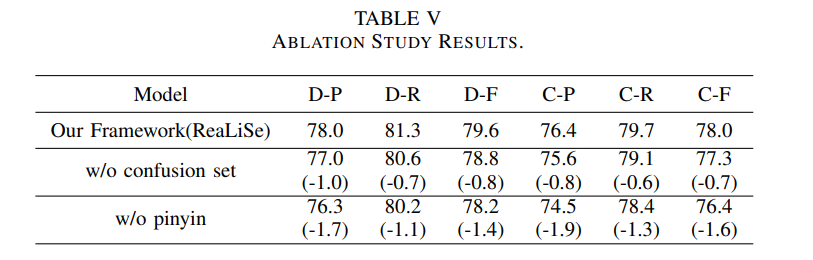
SIGHAN 2015 데이터셋에 대한 Realise-based 프레임워크의 결과를 예로 들어 다양한 모듈에 대한 ablation 연구를 수행, 실험 결과는 표5
pinyin기반 RCL 모듈을 제거 하면 탐지 수준 F-value와 보정 수준 F-value과 1.4%, 1.6%하락
혼동 셋을 제거하면 0.8%, 0.7%만 하락
병음 정보가 모델 성능 향상에 더 큰 역할을 함
