[논문 리뷰]Encoder-Decoder Models Can Benefit from Pre-trained Masked Language Models in Grammatical Error Correction
논문리뷰

Abstract
오류 보정을 위해 BERT와 같이 사전 학습된 MLM을 EncDec 모델에 효과적으로 통합하는 방법
MLM을 EncDec 모델에 통합하는 이전의 이란적인 방법은 GEC에 적용될 때 잠재적인 단점
예를 들어, GEC 모델에 대한 입력의 분포는 MLM을 사전 학습하는 데 사용된 말뭉치의 분포와 다를 수 있음
실험 결과, 주어진 GEC 말뭉치로 MLM을 fine-tuning한 다음 fine-tuning된 MLM의 출력을 GEC 모델의 추가 기능을 사용하는 제안된 방법이 MLM의 이점을 극대화
최고 성능 모델은 BEA-2019, CoNLL-2014에서 SOTA
1. Introduction
MLM을 EncDec 모델에 통합하는 일반적인 방법은 초기화(init)과 융합(fusion)
초기화 방법에선 다운스트림 task model이 사전 학습된 MLM의 파라미터로 초기화된 다음 task-specific training set에 대해 학습
근데 이 방식은 시퀀스간 언어 생성 작업과 같은 작업에는 적합하지 않음
많은 양의 학습 데이터가 필요, 그렇게 되면 사전 학습된 표현이 파괴되어 망각으로 이어짐
융합 방법에는 task-specific model을 학습하는 동안 미리 학습된 MLM의 representation이 추가 기능으로 사용
이 방법을 GEC에 적용할 경우, MLM이 사전 학습에서 학습한 내용은 유지하지만, MLM이 GEC task 또는 task-specific 입력 분포(예:학습자 말뭉치의 오류 문장)에 맞게 조정되지 않음
BERT를 사용하고, 다음 세가지 방법 평가
(a) 사전 학습된 BERT를 사용해 EncDec GEC 모델을 초기화(BERT-init)
(b) 사전 학습된 BERT의 출력을 추가 기능으로 EncDec GEC 모델에 전달(BERTfuse)
(c) a와 b의 best parts를 결합
(c)에선 먼저 GEC 말뭉치로 BERT를 미세 조정한 다음, 미세 조정된 BERT 모델의 출력을 GEC 모델의 추가기능으로 사용
이를 구현하기 위해 (c1)은 사전 학습된 BERT를 GEC 말뭉치로 추가로 학습시키는 방법(BERT-fuse mask)와 (c2)는 문법 오류 감지(GEC) 작업을 통해 사전 학습된 BERT를 미세 조정하는 방법(BERT-fuse GEC) 두 가지 옵션 고려
(c2)에선 대규모 일반 말뭉치(사전 학습된 BERT)에서 학습된 표현과 GEC 학습 데이터에서 유도된 GEC에 유용한 작업별 정보를 모두 활용할 수 있도록 GEC모델을 학습할 것으로 예상
미세 조정된 BERT 모델의 출력을 GEC 모델의 추가 기능으로 사용하는 방법(c)가 대부분의 GEC 말뭉치에서 BERT를 가장 효과적으로 사용하는 방법임
또한 BERT-fuse mask와 BERTfuse GED 방법을 결합하면 GEC의 성능이 더욱 향상
2. Related Work
MLM을 re-ranker로 사용하거나 필터링 tool로 사용할 경우 GEC의 성능을 향상시킬 수 있다고 보고
MLM과 결합된 EncDec 기반 GEC 모델은 이러한 파이프라인 방법과 함께 사용될 수 있음
MLM은 일반적으로 미세 조정을 통해 다운스트림 작업에 사용되지만, MLM의 최종 레이어의 출력을 문맥 임베딩으로 EncDec 모델에 제공하는 게 더 효과적이다
3. Methods for Using Pre-trained MLM in GEC Model
사전 학습된 MLM을 GEC모델에 통합하기 위한 접근 방식을 설명
(1) BERT를 사용해 GEC 모델 초기화
(2) BERT 출력을 GEC 모델의 추가 기능으로 사용
(3) GEC 코퍼스로 미세 조정된 BERT의 출력을 GEC 모델의 추가 기능으로 사용
3.1 BERT-init
BERT 가중치로 초기화된 GEC EncDec 모델 만듬
가장 최근의 SOTA는 문법적으로 올바른 문장에 pseudo 오류를 주입해 pseudo 데이터 사용
하지만 이 방법은 pseudo 데이터에서 학습한 사전 학습된 파라미터로 GEC 모델을 초기화할 수 없음
3.2 BERT-fuse
feature-based 접근법(BERT-fuse)로 모델 사용
이 모델은 트랜스포머 EncDec 아키텍처를 기반으로 함
BERT가 입력 문장을 인코딩하고 representation을 출력
다음으로 GEC 모델은 입력 문장과 representation을 입력으로 인코딩
3.3 BERT-fuse Mask and GED
BERT-fuse의 장점은 원시 말뭉치에서 사전 학습된 정보를 보존할 수 있지만, GEC 작업이나 작업별 입력 분포에는 적용되지 않을 수 있음
GEC 모델에선 BERT 학습에 사용되는 데이터와 달리 입력이 잘못된 문장이 될 수 있어서
GEC와 BERT를 학습하는 데 사용되는 말뭉치 사이의 격차를 메우기 위해, GEC 말뭉치에 대해 BERT를 추가로 학습하거나(BERT-fuse Mask), BERT를 GED 모델로 미세 조정한 후(BERT-fused GED) BERT-fuse에 사용
GED는 입력 문장에서 문법적으로 잘못된 단어를 검출하는 시퀀스 라벨링 작업
BERT는 GED에도 효과적이라 문법적 오류를 고려한 미세 조정에 적합한 것으로 판단
4. Experimental Setup
4.1 Train and Development Sets
BEA-2019를 학습 및 development셋으로 사용
특히 GEC모델을 학습하기 위해 W&I-train, NULE, FCE-train, Lang-8 데이터셋 사용
BERT-fuse mask 및 GED에 대한 BERT를 학습하기 위해 W&I-train, Nuclear, FCE-trian을 학습으로 사용하고 W&I-dev를 개발 데이터로 사용
4.2 Evaluating GEC Performance

W&I-test에선 ERRANT 평가지표를, CoNLL-2014 및 FCE-test 셋에선 M2점수, JFLEG에선 GLUE 사용
모든 결과(앙상블 제외)는 4개의 서로 다른 무작위 시드를 사용한 4번의 개별 실험의 평균
4.3 Models
GEC 모델의 하이퍼파라미터 값은 표1에 나와 있음
GEC 모델을 학습하는 동안 모델은 development set에서 평가되어 매 epoch마다 저장
1 epoch가 끝날 때 loss가 떨어지지 않으면 학습은 learning rate에 0.7 곱함
learning rate이 최소보다 낮거나 학습 epoch이 최대 epoch인 30에 도달하면 학습 중지
4.4 Pseudo-data
또한 pseudo 데이터 GEC 모델에서 사전 학습된 모델에 추가 기능으로 BERT-fuse, BERT-fuse mask, BERT-fuse GED 출력을 사용해 실험 수행
pseudo 데이터는 문법적으로 올바른 문장에서 문법적으로 잘못된 문장을 생성하는 역번역 모델의 출력에 확률적으로 문자 오류를 주입해 생성
4.5 Right-to-left(R2L) Re-ranking for Ensemble
standard left-to-right(L2R) 모델은 정규 앙상블의 점수를 사용해 n-best 가설을 생성하고 R2L 모델은 점수를 다시 매김
그런 다음 L2R과 R2L 점수의 합을 기준으로 n-best 후보의 순위를 다시 매김
생성 확률을 re-ranking 점수로 사용하고 4개의 L2R 모델과 4개의 R2L 모델 앙상블
5. Results
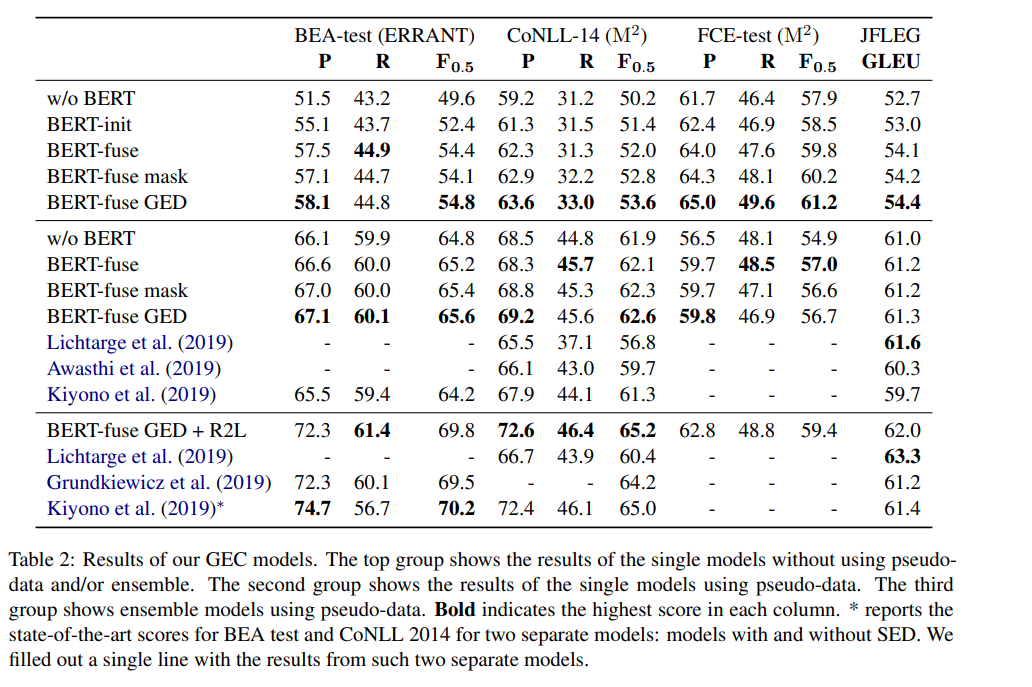
표2는 GEC 모델의 실험 결과
BERT를 사용하지 않고 Transformer에서 학습된 모델은 w/o BERT로 표시
상위 결과 그룹에서 BERT를 사용하면 GEC 모델의 정확도가 지속적으로 향상
BERT-fuse, BERT-fuse mask 및 BERT-fuse GED는 BERT-init보다 성능 좋음
또한 GEC 말뭉치를 BERT-fuse로 간주하는 BERT를 쓰면 더 나은 수정 결과를 얻을 수 있음
그리고 BERT-fuse GED는 항상 BERT-fuse mask보다 더 나은 결과 제공
이는 BERT-fuse GED가 문법 오류를 명시적으로 고려할 수 있기 때문일 수 있음
두 번째 행에서는 BERT를 사용해 수정 결과 개선
이 설정에서도 BERT-fuse GED는 FCE 테스트셋을 제외한 모든 경우에서 다른 모델보다 성능이 뛰어났으며, BEA2019, CoNLL14에서 단일 모델로 SOTA
마지막 행에선 앙상블 모델은 모든 말뭉치에서 높은 점수 얻음
7. Conclusion
GEC 모델 학습에 MLM을 효과적으로 사용한느 방법 조사
그 결과, BERT-fuse GED가 GEC 말뭉치에 맞게 미세 조정되었을 때 가장 효과적인 기법 중 하나였음을 알 수 있음
