Abstract
대량의 pseudodata로 Seq2Seq 모델을 사전 학습하는게 효과적이라고 보고
근데 이 접근법은 pseudo data의 크기 때문에 GEC를 위한 사전 학습에 많은 시간 소요
GEC를 위한 일반적인 사전 학습 인코더-디코더 모델로서 bidirectional 및 auto-regressive transformer(BART)의 유용성에 대해 살펴봄
일반 사전 학습 모델을 GEC에 사용하면 시간이 많이 걸리는 사전 학습을 없앨 수 있음
단일 언어 및 다국어 BART 모델이 GEC에서 높은 성능을 달성하며, 그 결과 중 하나는 현재 영어 GEC의 강력한 결과와 비슷
1. Introduction
GEC는 텍스트의 문법 및 기타 언어 관련 오류를 자동적으로 교정하는 작업
대부분의 작업에선 이 작업을 번역 작업으로 간주하고 인코더-디코더 아키텍처를 사용해 문법에 맞지 않는 문장을 문법에 맞는 문장으로 변환
이렇나 Enc-Dec 접근법은 대상 언어에 대한 언어학적 지식이 필요하지 않은 경우가 많음
GEC를 위한 강력한 Enc-Dec 모델은 단일 언어 말뭉치에 인위적인 오류를 도입해서 만든 대량의 인위적으로 생성된 데이터(일반적으로 pseudodata)로 사전 학습
이후 GEC task를 목표로 pseudo data를 사용한 사전 학습을 task-oriented 사전 학습이라고 함
예를 들어, 역번역을 사용해 pseudo corpusㄹ르 생성하고, 영어 GEC에서 좋은 결과 달성
단일 언어 말뭉치에 인위적인 오류를 도입해 pseudo corpus를 생성, 7개 언어의 GEC에서 최고 점수 획득
이러한 task-oriented 사전 학습 접근법은 pseudo 병렬 말뭉치를 광범위하게 사용, 이는 pseudo corpus를 사용해 GEC 모델을 사전 학습하는데 시간이 많이 소요되는 방식
이 연구에선 공개적으로 사용 가능한 사전 학습된 Enc-Dec 모델의 GEC에 대한 효과 확인
특히 pseudo data가 필요 없는 사전 학습된 모델을 조사
BART라는 사전 학습된 모델 사용
이 모델은 마스킹 및 셔플된 문장이 주어졌을 때 원본 시퀀스를 예측하는 방식으로 사전 학습
이러한 모델을 GEC에 사용하게 된 동기는 요약과 같은 여러 텍스트 생성 작업에서 강력한 결과를 얻어서
우리는 pseudo 말뭉치 접근법을 사용하는 GEC 모델과 비교하기 위해 사전 학습된 일반 BART 모델을 사용
4가지 언어에 대해 GEC 실험 수행, 영어, 게르만어, 체코어, 러시아어
BART에 기반한 Enc-Dec 모델은 영어 GEC에 대해 현재 강력한 Enc-Dec 모델과 비슷한 결과를 얻음
다국어 모델은 미세 조정이 필요함에도 불구하고 다른 언어에서도 높은 성능을 보임
이러한 결과는 BART가 GEC의 간단한 baseline으로 사용될 수 있음을 시사
2. Previous Work
GEC를 위한 Enc-Dec 접근법은 종종 task-oriented 사전 학습 전략 사용
예를 들어 Zhao(2019), Grundkiewicz(2019) pseudo 말뭉치를 사용한 Enc-Dec 모델의 사전학습이 GEC task에 효과적이라고 보고
단음절 말뭉치의 문장에 단어 및 문자 수준의 오류를 도입
confusion set을 개발해 문장의 단어를 무작위로 대체, 삭제, 랜덤 단어 삽입, 인접한 단어로 교체
문자에 대해서도 이와 동일한 작업 수행
위와 같은 방법으로 만든 pseudo 말뭉치는 1억 개의 학습 샘플로 구성
이러한 대규모 말뭉치로 사전 학습하는 것은 시간이 많이 걸리기 때문에, 본 연구는 일반적인 사전 학습 모델이 GEC에 효과적인지 검증하는 것을 목표로 함
또 다른 방법은 Naplava(2019) 독일어, 체코어, 러시아어를 포함한 여러 언어에 대해 pseudo 말뭉치(1000만 문장 쌍)로 학습해서 독일어, 체코어, 러시아어 GEC에 대한 SOTA 결과 얻음(위와 같은 방식 사용)
이러한 결과를 사전 학습된 일반 모델의 결과와 비교하여 모델이 여러 언어의 GEC에 효과적인지 확인
Kiyono(2019) 무작위 오류를 도입하거나 역번역을 사용해 pseudo 말뭉치를 생성하는 방법 탐구
역번역 데이터와 문자 오류를 사용한 task-oriented 사전학습이 무작위 오류를 기반으로 한 pseudo data보다 더 우수하다고 보고
Kaneko(2020)는 Kiyono(2019)의 사전 학습 방식과 BERT를 결합해 Kyono의 결과를 개선
특히 Kaneko(2020)는 문법 오류 감지 task를 통해 BERT를 미세 조정
각 토큰에 대해 미세 조정된 BERT 출력은 원래의 토큰과 결합되어 GEC 입력으로 사용
두 연구 모두 공개적으로 사용 가능한 일반 사전 학습 모델을 사용해 GEC를 수행한다는 점에서 우리의 연구와 유사
이 두 연구의 차이점은 Kaneko는 사전 학습된 모델의 아키텍처를 인코더로 사용했다는 점
따라서 이들의 방법은 여전히 많은 양의 pseudo data로 사전 학습 해야 함
영어 GEC의 현재 SOTA 방법은 Omelianchuk(2020)가 제안한 시퀀스 태깅 모델 사용
token-level transformation을 설계해 입력 토큰을 학습 데이터를 생성하기 위한 target correction에 매핑
그런 다음 시퀀스 태깅 모델은 입력 토큰에 해당하는 변환을 예측
본 연구의 목적은 pseudo data나 언어적 지식을 사용하지 않고 강력한 GEC 모델을 만드는 것이므로 이 접근 방식과 비교X
3. Generic Pretrained Model
BART는 transformer를 사용해 마스크된 시퀀스와 셔플된 시퀀스가 주어진 원본 시퀀스를 사전 학습
Span-BERT에서 영감을 얻은 Poisson distribution에 기반한 다양한 길이의 마스크 토큰을 여러 위치에 도입
문장의 언어를 표현하기 위해 special token 사용
예를 들어 독일어-러시아어 변환을 위해 인코더 및 디코더의 initial token에 <de_DE>와 <ru_RU>를 추가
GEC에 맞게 mBART를 미세 조정하기 위해 해당 언어를 참조하는 special token의 target 언어를 설정
4. Experiment
4.1 Settings
Common Settings
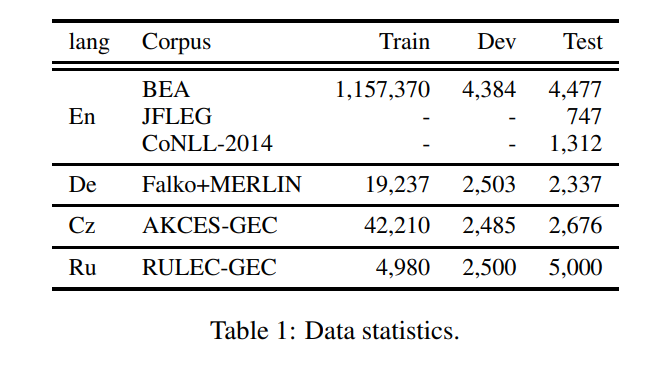
사용한 데이터셋은 표1과 같음
모델은 single GPU(NVIDIA TITAN RTX)를 사용해 미세 조정, 구현은 공개적으로 사용 가능한 코드를 기반으로(fairseq)
ensemble을 제외한 점수는 random seed를 사용한 5번의 미세 조정 실험에서 평균
English
영어 GEC를 위한 학습 데이터는 BEA-train에서 추출
source와 target에서 변경되지 않은 문장은 사용X(문법적으로 맞은 문장), 학습 데이터는 561,525개의 문장으로 구성
BEA-dev를 사용해 최적의 모델을 찾음
BART-large를 사용해 BART 기반 모델을 학습
이 모델은 적절한 출력을 보장하기 위해 추론에 약간의 제약이 필요한 요약 작업을 위해 제안되었지만, 우리는 task의 성격이 다르기 대문에 제약 조건 부과X
BART 기반 모델을 위한 학습 데이터에는 BPE 모델을 사용해 바이트 쌍 인코딩(BPE)를 적용
CoNLL-14와 JFLEG에는 각각 M2점수와 GLUE를 사용했고, BEA test에넌 ERRANT 점수를 사용
이러한 점수를 strong 결과와 비교(Kiyono, Kaneko)
m2 score: 오류 교정의 단위를 구(phrase)로 취급하고 GEC 결과가 정답과 비교해서 얼마나 교정되었는지 평가
GLUE: m2에 생성된 순위가 상관이 별로 없다해서 BLUE의 수정
n-gram 기반 평가 지표로 일반적인 기계 번역분야의 성능 측정과 달리, 원시 언어 문장도 같이 교정 성능 측정에 입력해서, 교정 모델이 원시 언어 문장에서 올바르게 교정한 부분에 대해서 평가 가중치를 더 부여
독일, 체코, 러시아 GEC를 위해 mBART-base 모델 학습(mbart.cc25)
mBART-base 모델에 대한 GEC 학습 데이터를 detokenized하고, SentencePiece 모델과 함께 SentencePiece를 적용
이 전처리를 통해 입력된 문장은 형태소 분석 tool, subword tokenizer를 사용해 토큰화된 문장과 비교하여 입력 문장이 문법 정보를 나타내지 않을 수 있음
그러나 어떤 전처리가 GEC에 적합한지는 본 논문의 범위를 벗어나므로 추후 연구로 다룰 예정
평가를 위해 subword를 복구한 후 출력을 토큰화
그런 다음 독일어와 러시아어에는 spaCy 기반의 tokenizer를 사용, 체코어에는 MorphoDiTa tokenizer 사용
게다가, M2 점수는 각 언어에서 사용, 이 점수를 현재 SOTA 결과와 비교
4.2 Results
English

표2는 영어 GEC task의 결과
단일 언어 모델을 사용할 경우, BART 기반 모델이 Kiyono가 제안한 모델보다 우수하며, CoNLL-14 및 BEA-test 측면에서 Kaneko가 말한 결과와 비슷한 수준
Kiyono와 Kaneko는 GEC의 정확도 향상을 위해 여러 가지 기법을 적용
이러한 모델들ㅇ르 비교하기 위해 다섯 가지 모델의 앙상블로 실험 진행
앙상블 모델은 싱글 모델보다 약간 더 좋았지만 다른 두 모델의 앙상블 모델보단 더 나빴음
앙상블 모델과 함께 BART-base 모델은 BART 모델을 미세 조정하기만 했음에도 불구하고 현재의 강력한 결과와 비슷한 결과를 얻음
앙상블 방식의 비효율적인 이유는 초기 가중치가 BART 모델과 동일하고, seed는 학습 데이터 순서 등 사소한 변화에만 영향을 미치기 때문에 5개의 모델이 크게 다르지 않기 때문인 것으로 판단
German, Czech, and Russian
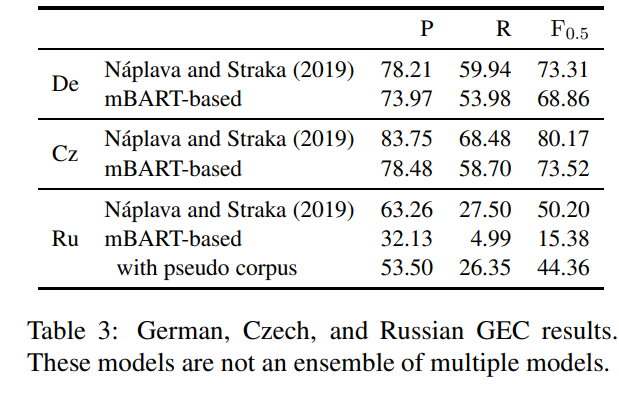
표3은 독일어, 체코어, 러시아어 GEC에 대한 결과
독일 GEC-task에선 mBART-based 모델이 4.45 F0.5점 낮은 점수 나옴
이는 Naplava가 target 언어로만 GEC 모델을 사전 학습했고 mBART는 25개 언어로 사전 학습해서 다른 언어의 정보가 노이즈로 포함되기 때문일 수도
10M pseudo 말뭉치로 mBART 모델을 추가 학습하고 학즙자 말뭉치로 미세 조정해서 자원이 부족한 시나리오 보완
5. Discussion
BART as a simple baseline model
독일어와 체코의 GEC 결과에 따르면 사전 학습된 mBART 모델을 미세 조정한 mBART-base 모델은 SOTA 모델과 비교할 수 있는 점수(엥?)
즉, mBART-base 모델은 pseudo 말뭉치를 사용하지 않고도 여러 언어에 대해 충분히 높은 성능을 보이는 것으로 간주
이러한 결과는 mBART-base 모델이 여러 언어에 대한 간단한 GEC baseline으로 사용될 수 있음을 나타냄
Performance comparison for each error type
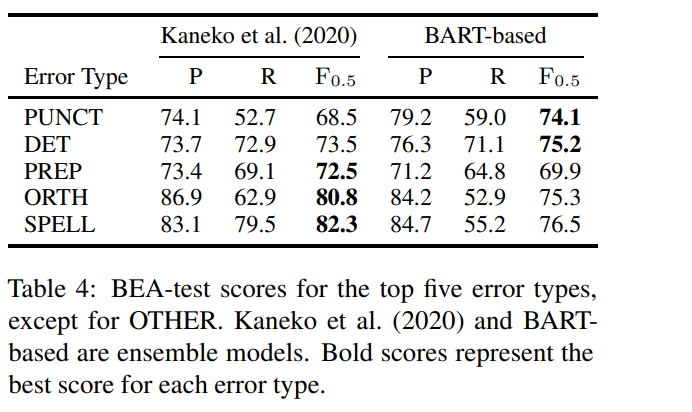
BART-base model을 Kaneko(2020)모델과 비교
BART-base는 PUNCT 및 DET 오류에서 좋고
특히, PUNCT는 5.6 F0.5 더 높음
BART는 셔플 및 마스킹된 시퀀스를 수정하도록 사전 학습되어 있으므로 이 모델은 구두점을 적절하게 배치하는 방법 학습
ORTH, SPELL는 BART가 사전 학습에서 셔플, 마스킹된 시퀀스를 노이즈로 사용해서 이러한 오류를 수정하기 어렵고, 문자 수준 오류를 사용하지 않음
Kaneko는 pseudo 말뭉치에 문자 오류 도입
