Abstract
- BERT는 downstream 언어 이해 작업을 위한 contextual embedding 대신 fine-tuning으로 더 일반적으로 사용되지만, NMT에서 BERT를 contextual embedding으로 사용하는 preliminary exploration이 fine-tuning에 사용하는 것보다 나음
- 먼저 BERT를 사용해 입력 시퀀스에 대한 representation을 추출한 다음 attention mechanisms을 통해 NMT 모델의 인코더 및 디코더의 각 레이어와 representation이 융합(fused)되는 BERT-fused model이라는 새로운 알고리즘 제안
- supervised(문장 수준 및 문서 수준 번역 포함), semi-supervised 및 unsupervised 기계 번역에 대한 실험에서 7개의 benchmark dataset에서 SOTA
1. Introduction
- NMT 모델은 일반적으로 입력 시퀀스를 hidden representation에 매핑하는 인코더와 hidden representation을 디코딩하여 대상 언어로 문장을 생성하는 디코더로 구성
- 계산 자원의 한계로 인해, BERT 모델을 처음부터 학습하기 힘듬
- 따라서 NMT에 처음부터 BERT 모델을 학습하는 대신 사전 학습된 BERT 활용
- BERT를 사용해 다운스트림 모델을 초기화한다음 모델을 fine-tuning
- 다운스트림 모델을 위한 context-aware embedding으로 BERT사용
1번째 방법은 효과 별로 없음
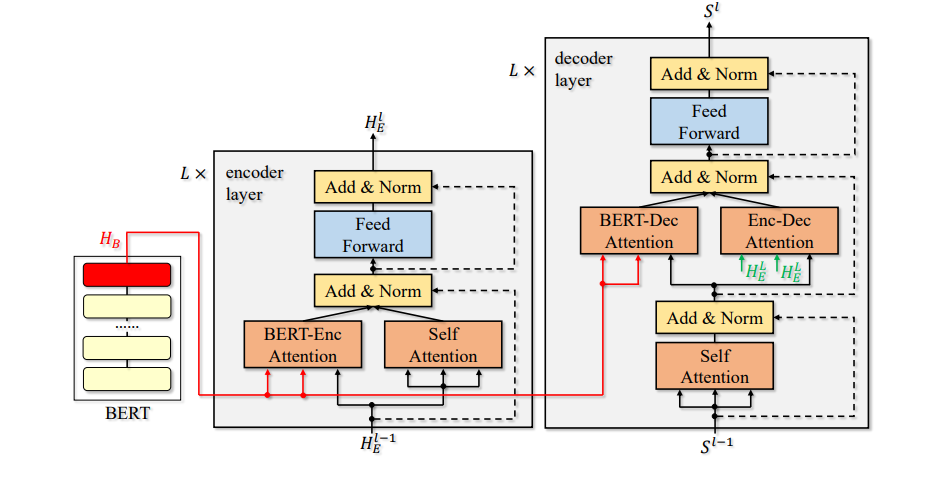
- BERT의 representation을 입력 임베딩으로만 제공하지 않고 모든 레이어에 공급하여 활용하는 새로운 알고리즘인 BERT-fused model 제안
- attention mechanism을 사용해 각 레이어가 representation과 상호 작용하는 방식을 adaptively하게 제어하고, BERT 모듈과 NMT 모듈이 서로 다른 단어 segmentation 규칙을 사용해 결과적으로 서로 다른 시퀀스길이(representation)를 생성할 수 있는 경우 처리
- standard NMT와 비교해 BERT외에도 BERT-encoder attention, BERT-decoder attention라는 구 가지 추가 attention module
- 입력 시퀀스는 먼저 BERT에서 처리되는 representation으로 변환
- 그런 다음 BERT encoder attention module에 의해 각 NMT 인코더 레이어는 BERT에서 얻은 representaion과 상호작용하고 결국 BERT와 NMT 인코더를 모두 활용해 융홥된 representation 출력
- 디코더는 유사하게 작동하며 BERT representaion과 NMT encoder representation 융합
4. Algorithm
Notations
X와 Y는 각각 source language domain과 target language domain을 나타냄
임의의 문장 x ∈ X 및 y ∈ Y에 대해 와 는 x및 y의 단위(단어 또는 하위 단어)의 수를 나타냄
x/y의 i번째 단위는 로 나타냄
우리 작업에서 encoder와 decoder를 NMT module이라고 부름
W.l.o.g. 이노더와 디코더 모두 L 레이어로 구성
attn(q,K,V)는 attention layer, q,K,V는 각각 query, key, value
4.1 BERT-fused model
Step-1
임의의 입력 x ∈ X가 주어지면, BERT는 먼저 = BERT(x)로 인코딩
는 BERT의 마지막 레이어의 출력
∈는 x에서 i번째 wordpiece 나타냄
Step-2
는 인코더에서 l번째 hidden representaion을 나타내고 는 시퀀스 x의 단어 임베딩
임의의 i ∈ []에 대해 에 대한 i번째 요소를

- , 는 서로 다른 파라미터를 가진 attention model
- 그런 다음 는 FFN에 의해 추가로 처리되고 우린 l번째 레이어의 출력을 얻음
:
- 인코더는 최종적으로 마지막 레이어로부터 출력
Step-3
가 time step t 이전의 디코더에서 l번째 레이어의 hidden state를 나타냄
은 시퀀스의 시작을 나타내는 특수 토큰이고 는 time step t-1에서 예측 단어의 임베딩
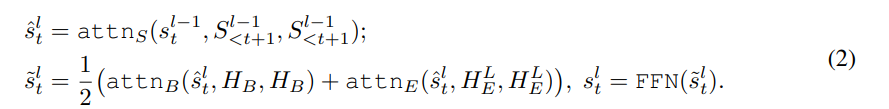
- attnS, attnB, attnE는 각각 self-attention model,BERT-decoder attention model,encoder-decoder attention model을 나타냄
- 식2는 레이어를 반복하고 결국 을 얻을 수 있음
- 마지막으로 는 선형 변환과 softmax를 통해 매핑되어 t번째 예측 단어 를 얻음
- 디코딩 프로세스는 문장 종료 토큰을 충족할 때 까지 계속
- 이는 tokenization 방식에 관계없이 사전 학습된 모델을 활용하는 일반적인 방법
- 우리의 프레임워크에서 BERT의 출력은 외부 시퀀스 표현의 역할을 하며, NMT mode에 통합하기 위해 attention module 사용
4.2 Drop-Net Trick
- 네트워크 학습을 정규화할 수 있는 dropout과 drop-path에서 영감을 받아, BERT와 기존 인코더가 출력하는 feature를 완전히 활용할 수 있도록 drop-net trick 제안
- drop-net은 식1과 식2에 영향을 미침
- drop-net rate를 ∈ [0, 1]로 표시
- 각 training iteration에서, 임의의 레이어 l에 대해, [0,1]에서 random variable 을 균일하게 샘플링한 다음, 식1의 모든 는 다음 방법으로 계산
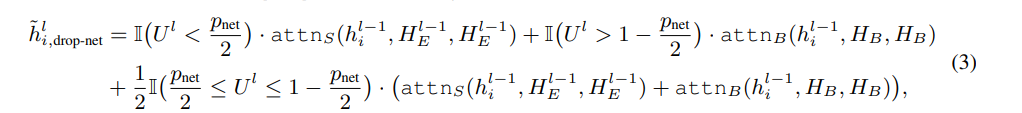
4.3 Discussion
- ELMO는 입력 시퀀스의 더 풍부한 정보를 포착하기 위해 인코더에 context aware embedding 제공
- 우리의 접근법은 사전 학습된 기능을 활용하는 보다 효과적인 방법
- 사전 학습된 모델의 output feature는 NMT 모듈의 모든 레이어에 융합되어, 사전학습된 feature가 완전히 활용되도록 보장
- attention model을 사용하여 NMT 모듈과 BERT의 사전 학습된 feature를 연결, 여기서 NMT 모듈은 다음의 기능을 활용하는 방법을 adaptively하게 결정
Limitation
(1) 추가 스토리지 비용: BERT 모델을 활용해서 스토리지 비용이 추가
BLEU 개선 및 BERT의 추가 학습이 필요하지 않다는 점을 고려하면 추가 스토리지는 수용 가능
(2) 추가 inference 시간: BERT를 사용해 입력 시퀀스를 인코딩하는데, 이는 약 45%의 추가 시간이 소요
8. Conclusion and Future Work
- BERT가 attention model을 통해 인코더와 디코더에 의해 활용되는 BERT와 NMT를 결합하는 효과적인 접근법인 BERT-fused model 제안
- Supervised NMT(문장 수준 및 문서 수준 번역 포함), semi-supervised NMT, unsupervised NMT에 대한 실험은 우리 방법의 효율성 보여줌
미래 연구
- 먼처 추론 과정을 가속화하는 방법 연구
- 둘째로, QA 같은 더 많은 응용 프로그램에 그러한 알고리즘을 적용
- 셋째, BERT-fused model을 light version으로 압축하는 방법
- knowledge distillation을 활용하여 사전 학습된 모델을 NMT와 결한
