
1세대 기술은통계 기반의 파라미터 합성 기술은 HMM(Hidden Markov Model)로 음성 파라미터들의 통계 정보를 모델링. HMM을 딥러닝의 심층 신경망(DNN)으로 교체
2세대는 시계열 데이터의 예측에서 뛰어난 성능을 보이는 LSTM-RNN활용
음성 파라미터 자체를 직접 예측
3세대부터는 1,2세대에서 활용됐던 음성의 특징 파라미터들을 대신해 음성 신호를 직접 예측
기존의 음성 파라미터를 활용하는 방식은 운율정보, 음향정보, 음의길이 등의 각 파라미터를 예측하기 위해 여러 단계의 모듈과 각 단계별 전문 지식과 최적화가 필요=> 입력부터 출력까지 하나의 모듈로 구성
입력 텍스트와 그에 대한 음성 데이터만 가지고도 모델을 학습할 수 있게 됨
Abstract
- 신경망 모델은 G2P 변환에서 SOTA 달성
- 하지만 성능은 많은 언어에서 사용할 수 없는 대규모 발음 사전에 의존
- 사전 학습된 언어 모델 BERT의 성공에 영감을 받아, 본 논문은 grapheme 정보만 있는 대규모 언어별 단어 목록에 대한 self-supervised 학습으로 구축된 사전 학습된 grapheme 모델인 grapheme BERT (GBERT)를 제안
- 또한 GBERT를 SOTA transformer기반 G2P 모델에 통합하기 위해 두 가지 접근 방식이 개발. 즉, GBERT를 fin-tuning하거나 attention을 통해 GBERT를 Transformer 모델에 융합
- SIGMORPHONE 2021 G2P 작업의 네덜란드어, 세르보크로아티아어, 불가리아어 및 한국어 데이터셋에 대한 실험 결과는 중간 자원 및 저자원 데이터 조건 모두에서 GBERT 기반 G2P 모델의 효과를 확인
1. Introduction
- G2P 변환 작업은 철자에서 단어의 발음을 예측하는 것
- G2P 변환은 TTS 및 ASR과 같은 언어의 구어체 형식과 문어체 형식 사이의 매핑 관게에 의존하는 모든 프로그램에 필수적
- G2P 변환에 대한 많은 연구가 수행되었음
- 초기에는 joint n-gram model, joint sequence model, WFST 제안
- 최근 LSTM 및 Transformer와 같은 neural networks은 G2P 변환에서 강력한 성능
- Transformer 기반 모델은 많은 벤치마크에서 SOTA 달성
- 일부 모방 학습 기반 방법도 transformer 모델과 비슷한 성능 달성
- 그럼에도 불구하고, neural G2P 모델을 구축하는 것은 일반적으로 많은 언어에서 사용할 수 없는 크고 언어별 발음 사전에 의존
- 이 문제를 해결하기 위한 한 가지 접근법은 cross-lingual modeling
- 초기 연구는 WFST 기반 시스템
- 그 결과, 다국어 neural network와 고자원 언어로 사전학습된 G2P 모델은 더 나은 cross-lingual G2P modeling 능력을 보여줌
- 다른 접근법은 multimodal data를 활용
- 추가 audio supervison이 G2P 모델이 보다 최적의 중간 grapheme 표현을 학습하는데 도움이 될 수 있다는 것을 발견
- 그러나 이러한 연구는 주로 unsupervised 방식으로 G2P에 대한 더 나은 grapheme 표현을 탐색하지 않는 제한된 리소스 G2P 변환의 성능을 개선하기 위해 다른 언어 또는 다른 모달의 데이터 리소스를 활용하는데 중점
- 따라서 본 논문은 transformer 기반 G2P 모델을 개선하기 위해 사전 학습된 grapheme BERT(GBERT)를 제안
- GBERT의 설계는 contextual word representation을 제공하고 기계 번역 및 텍스트 요약과 같은 다양한 NLP 작업에서 큰 성골을 거준 언어 모델 BERT에서 영감
- 마찬가지로, GBERT는 단어의 자소 간의 문맥적 관계를 포착하도록 설계되었으며, 이는 동일한 자소가 문맥에 따라 다른 발음을 가질 수 있기 때문에 G2P 작업에 필수적
- GBERT는 multi-layer Transformer encoder이며 자소 정보만 있는 대규모 언어별 단어 목록에 대한 self-supervised으로 사전 학습
- GBERT의 사전학습 작업은 마스킹된 자소 예측 작업, 즉 단어에서 보이는 자소로부터 masked grapheme을 예측하는 작업
- 또한 GBERT를 사용해 Transformer 기반 G2P 모델을 개선하기 위한 두 가지 접근 방식 개발
- GBERT를 fine-tuning하고 GBERT를 Transformer model에 attention하여 융합
- SIGMORPHON 2021 G2P task의 네덜란드, 세르보크로아티아어, 불가리아어 및 한국어 데이터셋에 대한 실험이 수행
- 결과는 attention에 의해 GBERT를 융합하면 중간 자원 조건에서 G2P의 WER과 PER을 줄일 수 있으며, GBERT를 fine-tuning하면 저자원 조건에서 대부분의 언어에 효과적
- 동시 연수 T5G2P에서도 사전 학습된 grapheme model이 G2P 변환에 도움이 될 수 있다고 언급
- 차이점은 T5G2P가 사전 학습 단계에서 grapheme과 grapheme의 autoregressive 정보 사이의 문맥적 관계를 포착하는 encoder-decoder 프레임워크를 사용하고 직접 fine-tuning 방법만 사용
2. Proposed Method
섹션 2.1에서 제안된 사전 학습된 grapheme model GBERT 소개
섹션 2.2에서 G2P용 GBERRT를 fine-tuning하는 세부 사항
섹션 2.3에서 Transformer 기반 G2P model에 GBERT를 융합하는 세부 사항
2.1 Grapheme BERT(GBERT)
- GBERT의 모델 아키텍처는 각 입력 토큰이 모든 입력 토큰을 볼 수 있는 multi layer bidirectional Transformer encoder
- GBERT의 입력은 한 단어의 grapheme sequence이고 BERT의 입력은 한 두 문장의 wordpiece sequence라는 점에서 다름
- BERT의 두 문장 입력은 문자 쌍을 기반으로 downstream task를 처리하도록 설계
- 이 논문은 single-word G2P 작업에 초점을 맞추고 있으므로 단일 단어 grapheme sequence만 고려
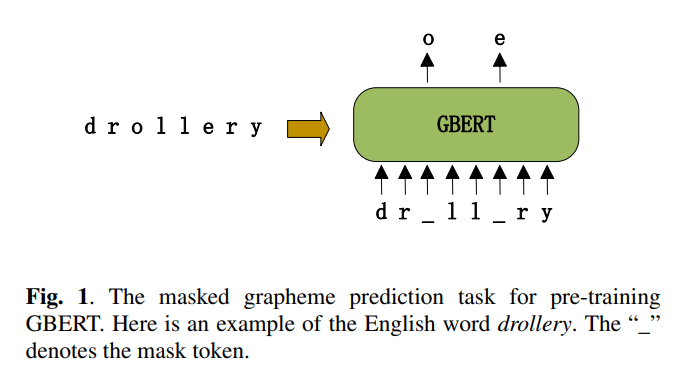
- GBERT는 masked grapheme 예측 작업을 사용해 사전 학습. 즉, 입력 grapheme의 일부를 랜덤하게 masking하고 grapheme에서 masked된 grapheme을 예측
- 이러한 마스크 입력( _ )은 사전 학습 작업과 downstream G2P 작업 간의 불일치를 제거하기 위해 mask token(80%), random grapheme(10%), original grapheme(10%)로 대체. 즉, mask token은 G2P 작업에서 발생X
2.2 Fine-tuning GBERT for G2P Conversion
- GBERT는 사전 학습된 Transformer encoder이고 vanila Transformer는 인코더와 디코더가 포함하기 때문에 GBERT를 fine-tuning한다는 것은 vanila Transformer의 인코더를 GBERT로 대체하고 새로운 모델을 end-to-end로 학습
- 사전 학습된 인코더와 무작위로 초기화된 디코더에 서로 다른 learning rate를 사용하면 더 나은 수렴
2.3 Fusing GBERT into Transformer-based G2P Model
- 미세조정 외에도, 사전 학습된 언어 모델을 통합하는 또 다른 접근 법은 feature extractor를 활용하는 것인데, 이는 downstrea task를 Transformer encoder로 쉽게 표현할 수 없을 때 fine-tuning 접근법 보다 더 잘 작동할 수 있음
- 한 가지 예로 BERT 융합 모델인데, 이는 vanila Transformer 모델의 각 인코더 및 디코더 레이어가 BERT의 output feature와 상호 작용하는 방법을 adaptively하게 제어하기 위해 multi-head attention 및 drop net을 채택
- 이 방법은 medium-resource 기계 번역 작업에서 BERT를 fine-tuning하고 naive feature기반 방법보다 더 잘 작동했기 때문에, 본 논문에서는 medium-resource G2P 시나리오에서 더 나은 결과를 달성하는 것을 목표로 GBERT를 transformer 기반 G2P model에 융합하도록 조정
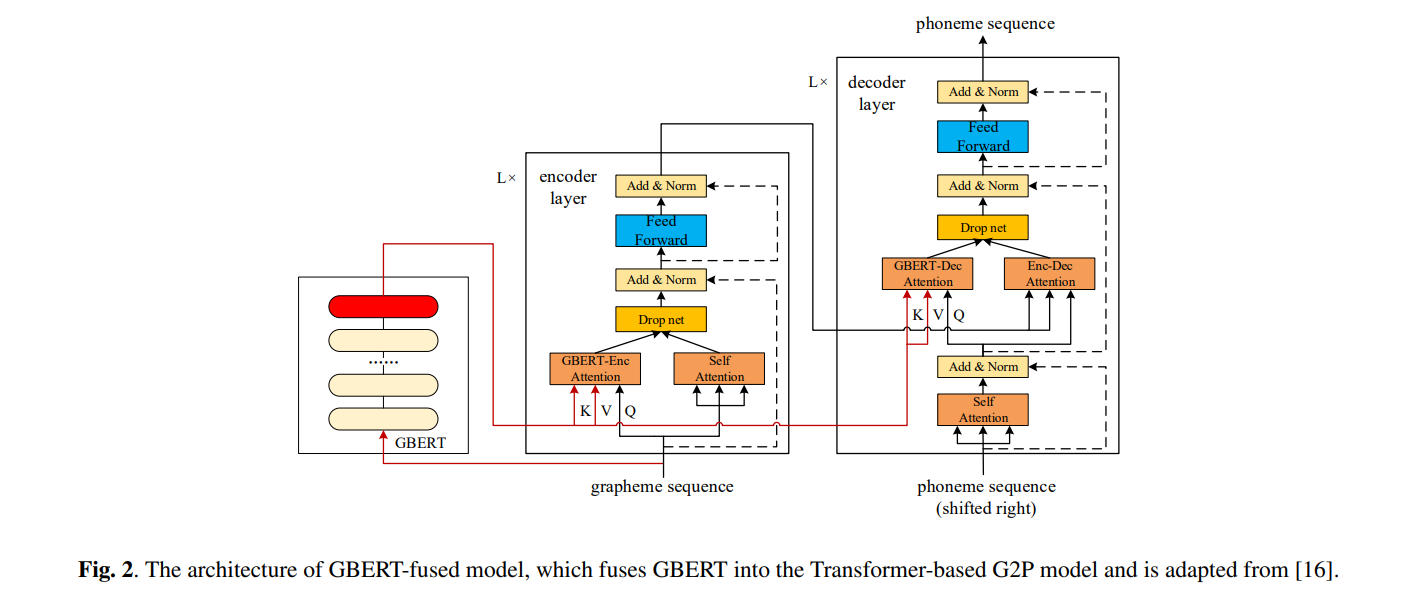
- Fig 2는 원래 BERT-fused 모델에서 GBERT가 BERT를 대체
- GBERT-fused model은 GBERT 외에 L encoder layer와 L decoder Layer로 구성
- I번째 인코더 계층의 경우, 입력은 (I-1)번째 인코더 계층의 출력 (또는 I=1일 때 grapheme sequence의 임베딩)과 GBERT에서 제공하는 문맥 grapheme representation이 포함
- I번째 디코더 레이어의 경우, 입력에는 (I-1)번째 디코더 레이어의 hidden state, 마지막 인코더 레이어의 출력 및 GBERT의 문맥 grapheme representation을 포함
- 특히, 각 인코더 계층에서, 이 계층이 GBERT representation과 상호 작용하는 방식을 adaptively하게 제어하기 위해 원래 Transformer encoder layer에 추가적인 GBERT Enc attention module이 추가
- 각 디코더 계층에는 유사한 목적을 위한 GBERT-Dec attention module이 있음
- 또한 drop net은 network 학습을 정규화하는데 사용되며, 학습 중에 두 입력 또는 평균 결과 중 하나를 출력하고 추론 중에 평균 결과를 출력
3. Experiments
3.1 Datasets
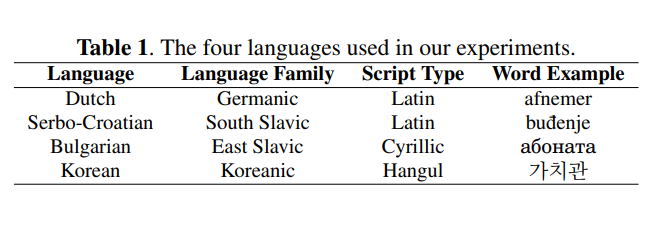
- SIGMORPHONE 20201 G2P 작업의 데이터셋
- official baseline의 G2P 성능에 따라 SIGMORPHONE 2021의 medium-resource 하위 작업에서 10개 언어 중 가장 어려운 4개 언어(즉 WER이 가장 높은 언어)가 선택
- 표 1에 나열된 것처럼, 이들은 서로 다른 언어 계열에 속하며 다른 스크립트 유형을 가지고 있음
- official setting에선 각 언어에 대한 학습, 검증, 및 테스트를 위해 8000, 1000, 1000 발음 기록이 사용
- 한글 자모를 사용하여 single-sound 문자로 분해 (예: 가감->ㄱ ㅏ ㄱ ㅏ ㅁ)
- 이 네가지 데이터셋을 기반으로 medium-resource G2P 작업과 low-resource G2P 작업 설계
- 중간 리소스는 학습, 검증, 테스트는 공식 설정과 동일
- low-resource task의 경우 원래 학습셋에서 1000개를 무작위로 샘플링하여 각 언어에 대해 더 작은 학습셋을 만들고 원래 validation, test셋에 사용
- 따라서 이 두작업의 테스트셋 성능을 직접 비교
- 또한 각 언어에 대한 단어 목록은 GBERT 사전 학습을 위해 WikiPron에서 수집
- G2P 작업의 검증 및 테스트셋의 단어는 제외되었고 Table 1의 4개 언어에 대한 최종 단어 목록은 각각 27000, 35000, 43100, 14100 단어를 포함
- 각 언어에 대해 단어의 90%는 단일 GBERT를 학습하는데 사용되었고 나머지 10%는 validation에 사용
3.2 Implementation
- 각 언어의 GBERT는 6-layer Transformer encoder
- 사전 학습 GBERT의 경우 단어의 마스크된 grapheme 비율은 20%로 설정했는데, 짧은 단어에서 마스크된 grapheme가 충분히 있을 것으로 예상해서 BERT의 마스킹된 단어의 비율(15%)보다 높음
- 각 언어의 검증셋에 대한 사전 학습된 GBERT 모델을 평가한 결과, masked grapheme의 예측 정확도는 각각 53.48%, 58.43%, 80.66%, 40.63%
- 단어와 grapheme 문맥적 관계를 보여주는 무작위 예측의 정확도(~2%)보다 모두 훨씬 높음
Imitation Learning
이 베이스라인 모델은 모방학습으로 명시적 edit action을 통해 작동하는 neural transducer를 채택했으며, SIGMORPHON 2020 G2P 작업에서 Transformer 모델과 유사한 성능 달성
중간 리소스 G2P 작업에 대한 IL 모델의 논문에 단일 모델 결과와 비교
Transformer
이 베이스라인 모델은 Transformer 기반 아키텍처를 채택했으며 이전 작업에 따라 구현
모델 hyperparameter는 다른 언어의 다른 작업에 맞게 조정
GBERT w/o fine-tuning
2.2절에서 제안한 방법, 다른 모델 파라미터 튜닝시 GBERT의 파라미터 고정(frozen)
GBERT fine-tuning
2.2절에서 제안한 방법
이전 연구와 마찬가지로, 사전 학습된 GBERT 인코더와 fine-tuning할 때 랜덤하게 초기화된 Transformer decoder에 서로 다른 learning rate 사용
1e-3, 5e-4, 3e-4, 1e-4, 1e-5 중에서 선택
GBERT attention
2.3절에서 제안된 방법, 기본 transformer model과 동일한 hyperparameter를 가짐
3.3 Evaluation Metrics
- WER, PER 사용
- WER은 예측된 phoneme sequence가 gold reference와 동일하지 않은 단어의 백분율
- PER은 예측 phoneme sequence와 reference phoneme sequence 사이의 Levenshtein 거리의 합을 테스트셋 기준 길이의 합으로 나눔
- WER 및 PER가 낮을 수록 성능 향상
- 다른 random seed를 사용해 각 실험을 5번 수행했고 각 모델에 대한 5개 결과 평균과 표준편차
- IL 모델의 결과는 인용, 저자들은 10번 반복 사용
- 그래서 표준 편차는 다른 모델과 비교X
3.4 Results
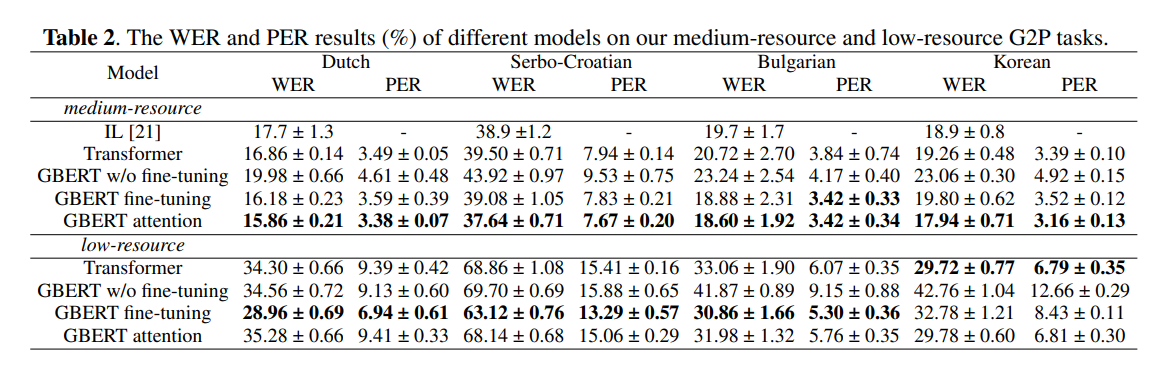
- Table 2는 중간 자원 및 저자원 G2P 작업에 대한 다양한 모델의 WER 및 PER 결과를 보여줌
- 우리가 구현한 Transformer baseline은 네덜란드어(Dutch)의 중간 리소스 작업에서 IL baseline은 능가했지만 다른 세 언어에선 IL보다 우수X
- GBERT w/o fine-tuning은 거의 모든 실험에서 transformer보다 성능이 떨어짐 특히 한국어
- 이는 사전 학습된 GBERT에서 파생된 grapheme representation이 G2P 변환에 필요한 모든 정보를 제공X
- 중간 리소스 G2P 작업에서 GBERT fine-tuning model은 4개 언어 모두에 대해 미세 조정하지 않은 모델보다 훨씬 우수, 한국어를 제외한 모든 언어에 대해 Transformer baseline보다 낮은 WER 및 PER 달성
- GBERT attention model은 모든 언어에 대한 5개 모델 중에서 가장 낮은 WER과 PER
- 이 모든 결과는 중간자원 G2P 작업을 위해 GBERT를 fine-tuning하거나 GBERT를 Transformer에 fusing하는 제안된 방법의 효율성 보여줌
- GBERT attention model도 GBERT w/o fine-tuning model과 마찬가지로 GBERT를 feature extractor로 채택했지만, GBERT representation 뿐만 아니라 Transformer 기반 G2P model의 원래 입력도 attention module에 활용된다는 장점
- 저자원 G2P 작업에선 중간자원 시나리오에 비해 모든 모델의 성능이 크게 감소하여 SOTA G2P 모델에 학습 데이터의 양이 중요함
- GBERT fine-tuning model은 4개 언어 모두에 대해 GBERT w/o fine-tuning 모델을 능가했으며 한국어를 제외한 모든 언어에 대해 Transformer baseline보다 우수한 성능
- 그러나 GBERT attention model은 Serbo-Croatian 및 불가리아어(Bularian)에 대해서만 Transformer baseline 보다 우수한 성능을 보였고, 네덜란드어, Serbo-Croatian 및 불가리어에 대해서는 GBERT fine-tuning model 만큼 좋진 않음
- 이러한 결과는 GBERT를 Transformer에 fusing하는 방법이 모델 구조가 복잡하기 때문에 GBERT를 미세 조정하는 방법보다 학습 데이터의 양에 더 민감
- 제안 방법이 저자원 G2P 작업에서 한국어에 대해 만족스러운 성능을 달성하지 목한 이유는 3.2절에서 보듯이 한국어의 마스크 예측 정확도가 다른 3개 언어보다 훨씬 낮았기 때문. 즉, 한국어의 grapheme간의 문맥 관계가 다른 3개 언어보다 약했기 때문
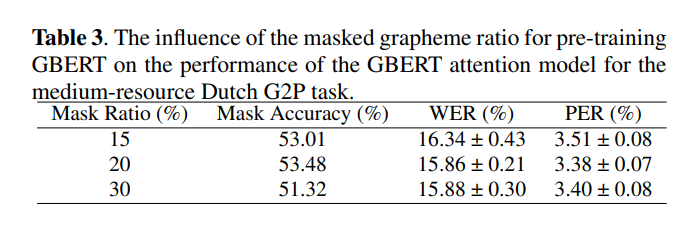
- GBERT의 사전 학습을 위한 masked grapheme 비율이 성능에 미치는 영향을 조사하기 위해 추가 실험
- 중간 자원 네덜란드어 G2P 작업에 대한 GBERT attention model을 예로 들었으며, 결과는 Table 3
- 마스크 비율(20%, 30%)이 높을 수록 BERT의 원래 비율인 15%보다 낮은 WER및 PER 달성
- 한 가지 가능한 이유는 한 단어의 평균 grapheme수가 평균 단어 수보다 훨씬 적고 grapheme space가 word space보다 훨씬 더 작기 때문
- 따라서 낮은 마스크 비율은 모델이 grapheme 간의 문맥적 관계를 발견X
3.5 GBERT-based Transfer Learning For G2P Conversion
- 저자원 G2P작업의 성능을 향상시키기 위해 고자원 언어의 G2P 데이터를 사용하는 GBERT 기반 transfer learning 실험 수행
- 저자원 언어로 네덜란드어를, 고자원 언어로 영어를 선택했는데, 이는 같은 게르만어족에 속하고 같은 라틴어 문자 유형을 가지고 있어서
- 영어의 supervised training data는 SIGMORPHON 2021 task의 고자원 하위 작업에서 33,344개의 단어-발음 쌍 포함
- 먼저, bilingual GBERT는 WikiPron의 49100개의 영어 단어와 3.1절에서 언급된 네덜란드어 단어 목록을 혼합하여 사전 학습
- BERT의 변형에 따라, 다른 언어를 구별하기 위해 GBERT의 입력 토큰에 언어 임베딩 추가
- 그런 다음 영어와 네덜란드어의 supervised training data를 사용해 neural G2P model 구축
- 이전 연구에 이어 언어 태그가 붙은 단어가 모델 입력에 사용
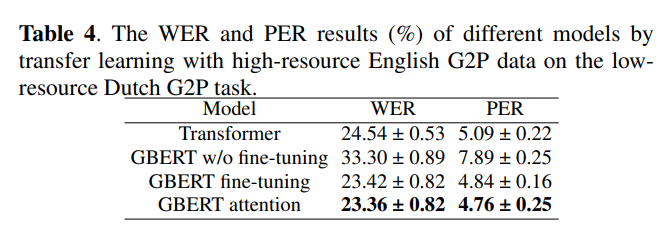
- Table 4와 Table 2의 저자원 결과를 비교하면, transfer learning 후 모든 시스템의 WER 및 PER이 크게 저하
- Table 2의 저자원 결과와 달리, GBERT attention model은 네 가지 모델 중 가장 낮은 WER와 PER 달성
- 이는 GBERT attention model이 유사한 고자원 언어에서 증간된 학습 데이터의 이점을 얻을 수 있으며 제안된 GBERT 기반 방법도 transfer learning 학습 전략과 결합하면 더 나은 성능
4. Conclusion
- 본 논문에선 contextual grapheme representation을 출력하는 사전 학습된 grapheme model GBERT 제안
- GBERT의 학습엔 쉽게 접근할 수 있는 단어 리스트만 필요
- 또한 GBERT를 사용해 SOTA Transformer 기반 G2P model을 향상시키기 위해 GBERT를 fine-tuning하고 GBERT를 Transformer에 fusing하는 두 가지 방법 개발
- SIGMORPHON 2021 G2P 작업의 네덜란드어, 세르보-크로아티아, 불가리아, 한국어 데이터셋에 대한 실험은 GBERT를 fusing하는 방법이 중간 자원 G2P 작업에서 모든 언어의 WER 및 PER을 줄일 수 있는 반면 fine-tuning 방법은 저자원 G2P 작업에서 대부분 언어의 G2P 성능 향상
- 앞으로 개로운 아키텍처와 loss function을 개발하고 구문 수준 또는 문장 수준의 학습 데이터를 활용해 사전 학습된 grapheme model 개선할 계획
